微调类型简介
1. SFT监督微调:适用于在源任务中具有较高性能的模型进行微调,学习率较小。常见任务包括中文实体识别、语言模型训练、UIE模型微调。优点是可以快速适应目标任务,但缺点是可能需要较长的训练时间和大量数据。
2. LoRA微调:通过高阶矩阵秩的分解减少微调参数量,不改变预训练模型参数,新增参数。优点是减少了微调的参数量和成本,同时能达到与全模型微调相近的效果。
3. P-tuning v2微调:引入了prefix-tuning的思想,每一层都加入了prefix,并采用了多任务学习。解决了P-tuning v1中序列标注任务效果不佳和普遍性差的问题。其参数对象是各层的prefix。优点是适用于多任务学习,但在自然语言理解任务上表现可能不佳。
4. Freeze微调:主要用于大语言模型的微调,后几层网络提取语义特征,前几层提取文本表层特征。优点是参数高效,适用于提取特定层次的特征。
综上所述,各种微调方法适用于不同的场景和任务。SFT监督微调适用于快速适应目标任务,LoRA适用于减少参数量和成本,P-tuning v2适用于多任务学习,而Freeze适用于提取特定层次的特征。
1.下载glm2训练脚本
git clone https://github.com/THUDM/ChatGLM2-6B.git
2.然后使用 pip 安装依赖
pip install -r requirements.txt -i https://pypi.douban.com/simple/
运行行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets transformers[torch] -i https://pypi.douban.com/simple/
3.下载样例数据或者自己构建样例
{"content": "类型#裙_材质#网纱_颜色#粉红色_图案#线条_图案#刺绣_裙腰型#高腰_裙长#连衣裙_裙袖长#短袖_裙领型#圆领", "summary": "这款连衣裙,由上到下都透出女性魅力,经典圆领型,开口度恰好,露出修长的脖颈线条,很是优雅气质,短袖设计,这款对身材有很好的修饰作用,穿起来很女神;裙身粉红色花枝重工刺绣,让人一眼难忘!而且在这种网纱面料上做繁复图案的绣花,是很考验工艺的,对机器的要求会更高,更加凸显我们的高品质做工;"}
可以根据以上格式,构建自己的训练样本,我们可以用一些行业生产数据,如会话记录对模型进行训练,
官方示例数据下载:
https%3A//cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/%3Fdl%3D1
4.根据自己的环境修改训练脚本中对应的文件地址
PRE_SEQ_LEN=128 #序列的预设长度为128
LR=2e-2 #学习率为0.02
NUM_GPUS=4 #用几颗GPU进行训练
torchrun --standalone --nnodes=1 --nproc_per_node=$NUM_GPUS main.py \
--do_train \
--train_file /export/data/train.json \ #设置训练数据文件的目录
--validation_file /export/data/validation.json \ #设置验证文件的目录
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /opt/tritonserver/python_backend/models/chatglm2-6b \ #模型目录
--output_dir /export/models/trained-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \ #训练后的模型目录
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
5.开始训练吧
sh train.sh
训练中
快要训练完成
6.训练完成
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 4598.3849, 'train_samples_per_second': 41.754, 'train_steps_per_second': 0.652, 'train_loss': 0.1287700497706731, 'epoch': 2400.0}
100%|██████████| 3000/3000 [1:16:37<00:00, 1.53s/it]
***** train metrics *****
epoch = 2400.0
train_loss = 0.1288
train_runtime = 1:16:38.38
train_samples = 24
train_samples_per_second = 41.754
train_steps_per_second = 0.652
7.部署训练后的模型
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM-6B 模型以及 PrefixEncoder 的权重
model_path = "/opt/tritonserver/python_backend/models/chatglm2-6b"
model = AutoModel.from_pretrained(model_path, config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join('/opt/train/trained-chatglm2-6b-pt-128-1e-4/checkpoint-3000', "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
8.过程中遇到的问题
8.1 微调后无法应答
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc_per_node=$NUM_GPUS main.py \
--do_train \
--train_file train.json \
--validation_file dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /opt/tritonserver/python_backend/models/chatglm2-6b \
--output_dir trained-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
使用官方脚本中的学习率设置 LR=2e-2 (0.02)
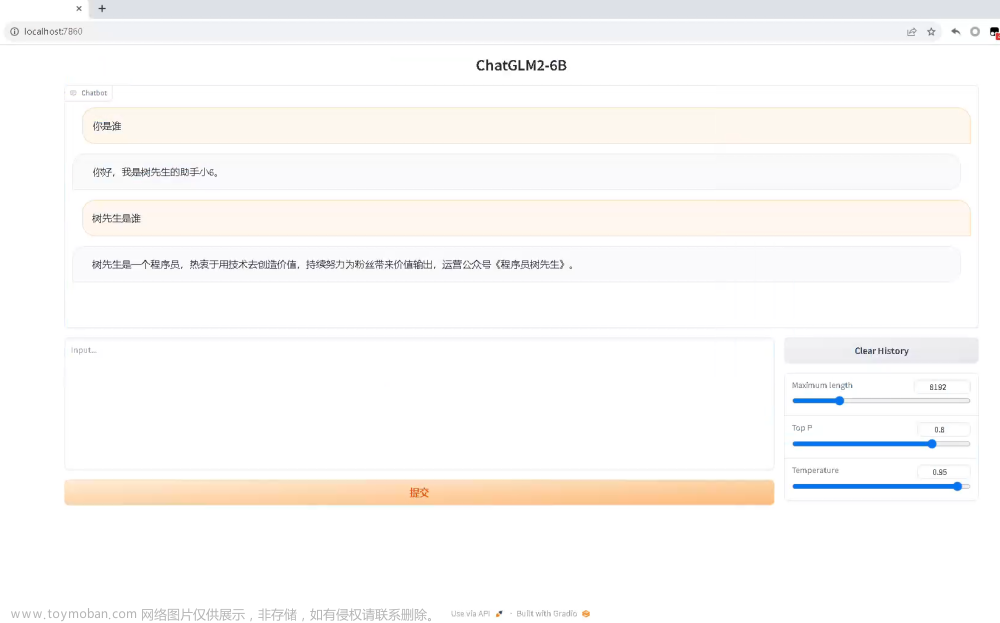
模型出现无法应答,灾难性遗忘,基本上原有的知识都遗忘了,无法应答普通提问 , 比如"你好.."
于是尝试使用 LR=1e-4 (0.0001) 进行训练
"1e-4" 表示 1 乘以 10 的 -4 次方,即等于 0.0001,"2e-2" 表示 2 乘以 10 的 -2 次方,即等于 0.02。
模型最终可以应答.
镜像问题:
https://github.com/THUDM/ChatGLM-6B/issues/1148
8.2 关于学习率:
我理解是,学习率大小像看书看的粗细,看的太粗就学的快(收敛快)但啥也学不到,
学习率是影响模型训练效果的重要参数。过大的学习率可能导致模型不稳定,过小的学习率则可能导致训练速度变慢。因此,需要反复试验,找到合适的学习率。
学习率(lr)表示每次更新权重参数的尺度(步长),ΔΘ=Θ0−(lr)(loss′)。
学习率与batch_size在权重更新中的关系
学习率(lr)直观可以看出lr越大,权重更新的跨度越大,模型参数调整变化越快。
batch_size对模型的影响,在于模型每次更新时,计算梯度是计算整个Batch的平均梯度,
即权重更新公式中的loss′=1batchsize(lossbatch)′, 整合就是 ΔΘ=Θ0−(lr)1batchsize(lossbatch)′ 。即lr与batch_size共同影响模型更新。
作者:京东科技 杨建文章来源:https://www.toymoban.com/news/detail-711545.html
来源:京东云开发者社区 转发请注明来源文章来源地址https://www.toymoban.com/news/detail-711545.html
到了这里,关于基于 P-Tuning v2 进行 ChatGLM2-6B 微调实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!