一、安装python
官网
下载python3.9及以上版本
二、安装playwright
playwright是微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作。
(1)安装Playwright依赖库
1 pip install playwright
文章来源地址https://www.toymoban.com/news/detail-711675.html
(2)安装Chromium、Firefox、WebKit等浏览器的驱动文件(内置浏览器)
1 python -m playwright install
三、分析网站的HTML结构
魔笔小说网是一个轻小说下载网站,提供了mobi、epub等格式小说资源,美中不足的是,需要跳转城通网盘下载,无会员情况下被限速且同一时间只允许一个下载任务。
当使用chrome浏览器时点击键盘的F12进入开发者模式。
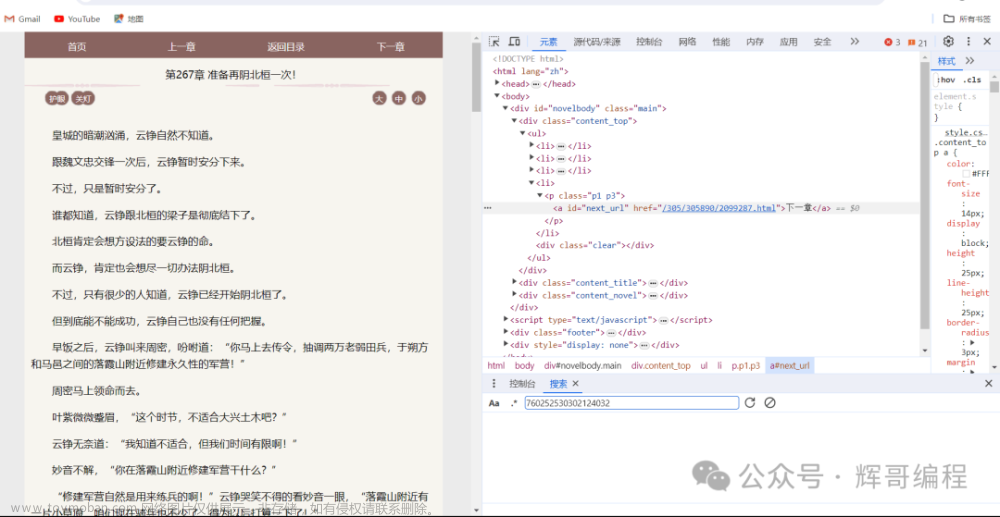
(一)小说目录

HTML内容

通过href标签可以获得每本小说的详细地址,随后打开该地址获取章节下载地址。
(二)章节下载目录

HTML内容

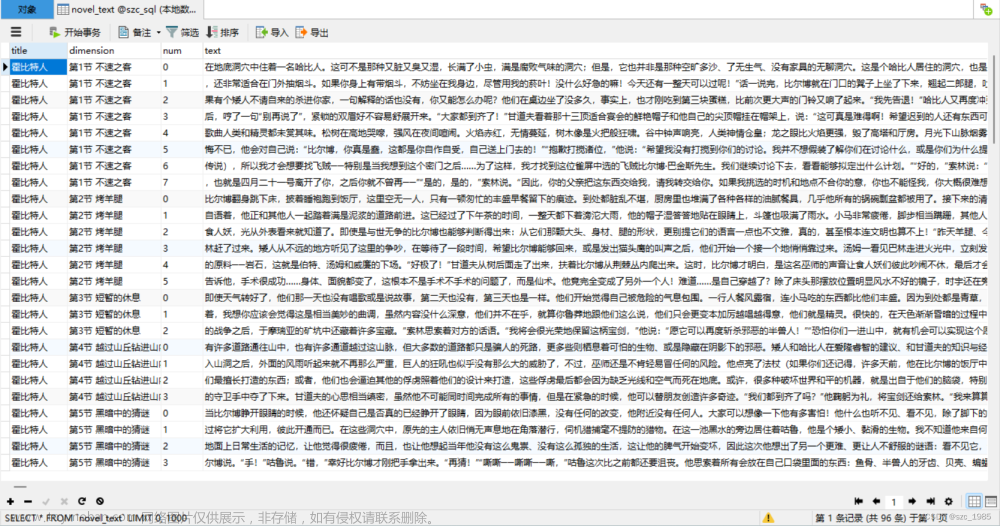
遍历每本小说的地址并保存到单独的txt文件中供后续下载。
(三)代码
1 import time,re 2 3 from playwright.sync_api import Playwright, sync_playwright, expect 4 5 def cancel_request(route,request): 6 route.abort() 7 def run(playwright: Playwright) -> None: 8 browser = playwright.chromium.launch(headless=False) 9 context = browser.new_context() 10 page = context.new_page() 11 # 不加载图片 12 # page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request) 13 page.goto("https://mobinovels.com/") 14 # 由于魔笔小说首页是动态加载列表,因此在此处加30s延迟,需手动滑动页面至底部直至加载完全部内容 15 for i in range(30): 16 time.sleep(1) 17 print(i) 18 # 定位至列表元素 19 novel_list = page.locator('[class="post-title entry-title"]') 20 # 统计小说数量 21 total = novel_list.count() 22 # 遍历获取小说详情地址 23 for i in range(total): 24 novel = novel_list.nth(i).locator("a") 25 title = novel.inner_text() 26 title_url = novel.get_attribute("href") 27 page1 = context.new_page() 28 page1.goto(title_url,wait_until='domcontentloaded') 29 print(i+1,total,title) 30 try: 31 content_list = page1.locator("table>tbody>tr") 32 # 保存至单独txt文件中供后续下载 33 with open('./novelurl/'+title+'.txt', 'a') as f: 34 for j in range(content_list.count()): 35 if content_list.nth(j).locator("td").count() > 2: 36 content_href = content_list.nth(j).locator("td").nth(3).locator("a").get_attribute("href") 37 f.write(title+str(j+1)+'分割'+content_href + '\n') 38 except: 39 pass 40 page1.close() 41 # 程序结束后手动关闭程序 42 time.sleep(50000) 43 page.close() 44 45 # --------------------- 46 context.close() 47 browser.close() 48 49 50 with sync_playwright() as playwright: 51 run(playwright)
(四)运行结果


四、开始下载
之所以先将下载地址保存到txt再下载而不是立即下载,是防止程序因网络等原因异常崩溃后记录进度,下次启动避免重复下载。
(一)获取cookies
城通网盘下载较大资源时需要登陆,有的轻小说文件较大时,页面会跳转到登陆页面导致程序卡住,因此需利用cookies保存登陆状态,或增加延迟手动在页面登陆。
chrome浏览器可以通过cookies editor插件获取cookies,导出后即可使用。
(二)分析下载地址
下载地址有三种类型,根据判断条件分别处理:
(1)文件的访问密码统一为6195,当域名为 https://url74.ctfile.com/ 地址后缀带有 ?p=6195 时,页面自动填入访问密码,我们需要在脚本中判断后缀是否为 ?p=6195 ,如不是则拼接字符串后访问;
(2)有后缀时无需处理;
(3)当域名为 https://t00y.com/ 时无需密码;
1 if "t00y.com" in new_url: 2 page.goto(new_url) 3 elif "?p=6195" not in new_url: 4 page.goto(new_url+"?p=6195") 5 page.get_by_placeholder("文件访问密码").click() 6 page.get_by_role("button", name="解密文件").click() 7 else: 8 page.goto(new_url) 9 page.get_by_placeholder("文件访问密码").click() 10 page.get_by_role("button", name="解密文件").click()
(三)开始下载
playWright下载资源需利用 page.expect_download 函数。
下载完整代码如下:
1 import time,os 2 3 from playwright.sync_api import Playwright, sync_playwright, expect 4 5 6 def run(playwright: Playwright) -> None: 7 browser = playwright.chromium.launch(channel="chrome", headless=False) # 此处使用的是本地chrome浏览器 8 context = browser.new_context() 9 path = r'D:\PycharmProjects\wxauto\novelurl' 10 dir_list = os.listdir(path) 11 # 使用cookies 12 # cookies = [] 13 # context.add_cookies(cookies) 14 page = context.new_page() 15 for i in range(len(dir_list)): 16 try: 17 novel_url = os.path.join(path, dir_list[i]) 18 print(novel_url) 19 with open(novel_url) as f: 20 for j in f.readlines(): 21 new_name,new_url = j.strip().split("分割") 22 if "t00y.com" in new_url: 23 page.goto(new_url) 24 elif "?p=6195" not in new_url: 25 page.goto(new_url+"?p=6195") 26 page.get_by_placeholder("文件访问密码").click() 27 page.get_by_role("button", name="解密文件").click() 28 else: 29 page.goto(new_url) 30 page.get_by_placeholder("文件访问密码").click() 31 page.get_by_role("button", name="解密文件").click() 32 33 with page.expect_download(timeout=100000) as download_info: 34 page.get_by_role("button", name="立即下载").first.click() 35 print(new_name,"开始下载") 36 download_file = download_info.value 37 download_file.save_as("./novel/"+dir_list[i][:-4]+"/"+download_file.suggested_filename) 38 time.sleep(3) 39 os.remove(novel_url) 40 print(i+1,dir_list[i],"下载结束") 41 except: 42 print(novel_url,"出错") 43 time.sleep(60) 44 page.close() 45 46 # --------------------- 47 context.close() 48 browser.close() 49 50 51 with sync_playwright() as playwright: 52 run(playwright)
(四)运行结果
 文章来源:https://www.toymoban.com/news/detail-711675.html
文章来源:https://www.toymoban.com/news/detail-711675.html
| Arabic | Hebrew | Polish |
| Bulgarian | Hindi | Portuguese |
| Catalan | Hmong Daw | Romanian |
| Chinese Simplified | Hungarian | Russian |
| Chinese Traditional | Indonesian | Slovak |
| Czech | Italian | Slovenian |
| Danish | Japanese | Spanish |
| Dutch | Klingon | Swedish |
| English | Korean | Thai |
| Estonian | Latvian | Turkish |
| Finnish | Lithuanian | Ukrainian |
| French | Malay | Urdu |
| German | Maltese | Vietnamese |
| Greek | Norwegian | Welsh |
| Haitian Creole | Persian |
到了这里,关于使用playwright爬取魔笔小说网站并下载轻小说资源的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!