- 一、爬取目标
- 二、爬取结果
- 三、代码讲解
- 四、技术总结
- 五、演示视频
- 六、附完整源码
一、爬取目标
您好!我是@马哥python说,一名10年程序猿。
今天分享一期爬虫案例,爬取的目标是:今日头条热榜的榜单数据。
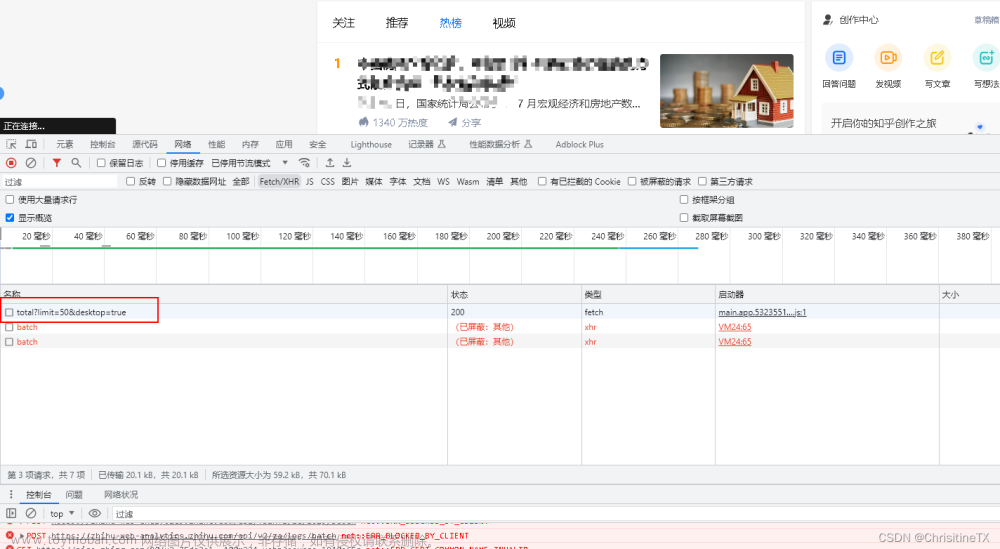
打开今日头条 首页,在页面右侧会看到头条热榜,如下:
爬取以上6个关键字段,含:
热榜排名,热榜标题,热度值,热榜标签,热榜分类,热榜链接。
开发者模式分析:
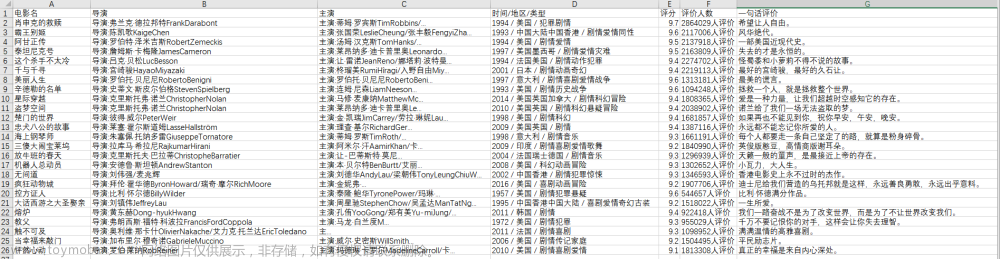
二、爬取结果
爬取结果截图:
三、代码讲解
首先,导入需要用到的库:
import requests
import pandas as pd
import re
定义一个请求头:(爬取目标较简单,一个User-agent即可)
# 请求头
h1 = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
}
定义请求地址:
url = 'https://www.toutiao.com/hot-event/hot-board/?origin=toutiao_pc'
用requests发送请求:
# 发送请求
response = requests.get(url, headers=h1)
查看响应码并以json方式接收返回数据:
# 查看响应码
print(r.status_code)
# 接收返回数据
json_data = r.json()
定义一些空列表,用于存放数据:
title_list = [] # 热榜标题
value_list = [] # 热度值
url_list = [] # 热榜链接
category_list = [] # 热榜分类
label_list = [] # 热榜标签
以"热榜标题"字段为例:
for data in json_data['data']:
# 热榜标题
title = data['Title']
print('热榜标题:', title)
title_list.append(title)
其中,热榜链接比较特殊,接口中返回的url很长,形如:
可以看到,url中从?往后,都是不必要的请求参数。
所以,用正则表达式把?后面的全部删掉,提取出id,再进行拼接url,如下:
# 正则表达式提取出链接id
url3 = re.search(r"(?<=https:\/\/www\.toutiao\.com\/trending\/)\d+", url2).group(0)
# 拼接链接
url4 = 'https://www.toutiao.com/trending/' + str(url3)
最后,把所有字段存放的列表数据组成Dataframe格式:
# 把列表数据组装成Dataframe数据
df = pd.DataFrame(
{
'热榜排名': range(1, data_num + 1), # 一共50条
'热榜标题': title_list,
'热度值': value_list,
'热榜标签': label_list,
'热榜分类': category_list,
'热榜链接': url_list,
}
)
进一步保存到csv文件里:
# 保存到csv文件
df.to_csv(result_file, header=True, index=False, encoding='utf_8_sig')
以上,核心逻辑讲解完毕。
代码中还含有:解析热度值、热榜标签、热榜分类、热榜链接字段等,详见文末完整代码。
四、技术总结
爬取技术流程:
- requests 发送请求
- json 解析数据
- re 正则表达式提取文本
- pandas 保存csv
五、演示视频
演示视频:代码演示:用python爬头条热榜TOP50榜单!
六、附完整源码
本案例完整源码已上传微信公众号"老男孩的平凡之路",后台回复"爬头条热榜"即可获取。 点击直达:点这里文章来源:https://www.toymoban.com/news/detail-712101.html
我是@马哥python说,一名10年程序猿,持续分享python干货中!文章来源地址https://www.toymoban.com/news/detail-712101.html
到了这里,关于【爬虫实战】用python爬今日头条热榜TOP50榜单!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!