背景
在分布式系统中,经常需要用到全局唯一ID发生器,标识需要存储的数据。我们需要什么样的ID生成器?
ID生成器除了是数据的唯一标识以外,一般需要在系统中承担更多的责任,概括起来有以下几点:
唯一性:“全局唯一” vs “业务唯一”?
分布式系统使用唯一的ID生成器,会有非常严重的申请互斥问题。互斥加锁意味着成本和性能的下降,不容易去实现一个高性能高可靠的架构。在业务系统中,往往也不需要全局唯一的ID。
比如在通讯系统里,聊天消息不需要全局唯一,标识一条用户发出的消息的ID,只要保证用户唯一性即可。因为消息本身归属于某一用户,因此用户唯一已经隐含了“全局唯一ID ( = 用户ID + 消息ID )”。
时间相关:“秒级” vs “毫秒”?
时间是天然唯一的,因此也是很多设计的选择。但对于一个8Byte的 ID 而言,时间并没有那么多。你如果精确到秒级别,三十年都要使用30bit,到毫秒级则要再增加10bit,你也只剩下20bit 可以做其他事情了。每秒一个或者每毫秒一个ID明显是不够的,刚才说到还有20bit 可以做其他事情,就包括一个SequenceID。
那时间用秒还是毫秒呢?其实不用毫秒的时候就可以把空出来的10bit 送给 Sequence,但整个ID 的精度就下降了。峰值速度是更现实的考虑。Sequence 的空间决定了峰值的速度,而峰值也就意味着持续的时间不会太久。这方面,每秒100万比每毫秒1000限制更小。
有序:“粗略有序” vs “精确有序”?
首先,如果要达到精确的有序,就要对 Sequence 进行并发控制,性能上肯定会打折。其次,同一时间只能生成一个ID,意味着同一时间只有一个ID生成服务实例可以提供服务,精确有序还会面临容灾问题。
另外一个选择就是,在这个秒的级别上不再保证顺序,而整个 ID 则只保证时间上的有序。后一秒的 ID肯定比前一秒的大,但同一秒内可能后取的ID比前面的号小。粗略有序在使用时非常关键,业务上可接受才能成为候选方案。
设计细节
看下业界如何设计ID发生器
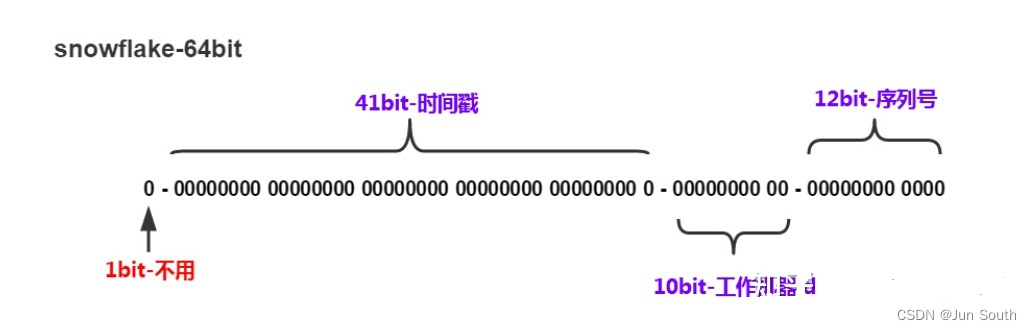
SnowFlake
41bit留给毫秒时间,10bit给机器 (MachineID) ,剩下12bit留给Sequence。
微博 30bit的秒级时间,4bit来区分IDC,2bit 区分业务,15bit 给 Sequence。理论上限3.2w/s的速度。由于当前发号服务是机房中心式的,1bit 来区分热备。最终,没有用满64bit。
Flicker
Flicker 在解决全局ID生成方案里就采用了MySQL自增长ID的机制(auto_increment + replace into + MyISAM)。
在我们的应用端需要做下面这两个操作,在一个事务会话里提交:
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
Flicker启用了两台数据库服务器生成ID来容灾,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1
TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2
微信
微信使用MySQL持久化未分配的最大ID,每次从DB取一段放到内存分配给调用方。微信的ID生成是严格递增的,意味着同一时间只能有一台机器提供服务,因此使用仲裁服务+租约机制+路由表,进行容灾。

Shopee Feeds 如何生成ID ?
考虑到Feeds业务的特性,并不需要精确有序,因此我们使用snowflake算法进行ID生成。使用39 (毫秒)+ 5(机器) + 9(seq),来保证ID作为Redis的score不会溢出。
Redis 有序集合的分数使用双精度64位浮点数, 表示为一个IEEE 754 floating point number,它能包括的整数范围是-(2^53) 到 +(2^53)
这样的ID生成器可以使用大约17年,对于一款产品的生命周期来说已经足够使用。
针对时间回拨产生的问题,因为发生的频率极小,所以只需要简单判断,如果不满足 currentMillis <= lastTime,则返回错误即可。
作者:cyningsun
来源:www.cyningsun.com/12-26-2018/id-generator.html
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
2.劲爆!Java 协程要来了。。。
3.Spring Boot 2.x 教程,太全了!
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
5.《Java开发手册(嵩山版)》最新发布,速速下载!文章来源:https://www.toymoban.com/news/detail-712306.html
觉得不错,别忘了随手点赞+转发哦!文章来源地址https://www.toymoban.com/news/detail-712306.html
到了这里,关于京东一面:分布式 ID 生成方案怎么选?写得太好了!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!