⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬、关注🤝,关注必回关
上一篇文章已经跟大家介绍过《用户画像的设计准则以及美团外卖用户画像的设计案例》,相信大家对用户画像都有一个基本的认识。下面我讲一下:数据采集:数据挖掘的基础。
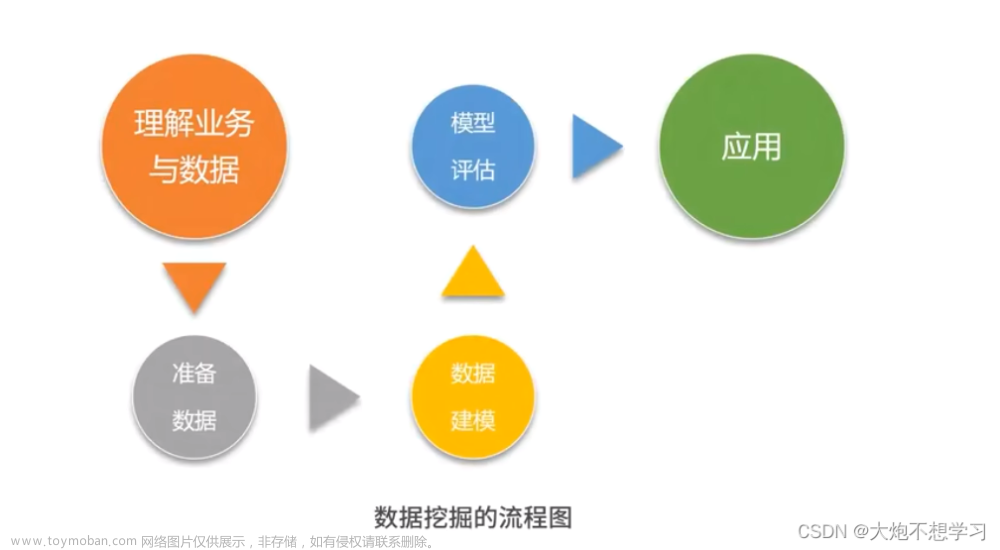
一、数据挖掘的基础
上一节中我们讲了如何对用户画像建模,而建模之前我们都要进行数据采集。数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。很多时候,我们拥有多少数据源,多少数据量,以及数据质量如何,将决定我们挖掘产出的成果会怎样。
举个例子,你做量化投资,基于大数据预测未来股票的波动,根据这个预测结果进行买卖。你当前能够拿到以往股票的所有历史数据,是否可以根据这些数据做出一个预测率高的数据分析系统呢?
实际上,如果你只有股票历史数据,你仍然无法理解股票为什么会产生大幅的波动。比如,当时可能是爆发了 SARS 疫情,或者某地区发生了战争等。这些重大的社会事件对股票的影响也是巨大的。
因此我们需要考虑到,一个数据的走势,是由多个维度影响的。我们需要通过多源的数据采集,收集到尽可能多的数据维度,同时保证数据的质量,这样才能得到高质量的数据挖掘结果。
那么,从数据采集角度来说,都有哪些数据源呢?我将数据源分成了以下的四类。

这四类数据源包括了:开放数据源、爬虫抓取、传感器和日志采集。下面详情说明你一下。
1、开放数据源
一般是针对行业的数据库。比如美国人口调查局开放了美国的人口信息、地区分布和教育情况数据。除了政府外,企业和高校也会开放相应的大数据,这方面北美相对来说做得好一些。国内,贵州做了不少大胆尝试,搭建了云平台,逐年开放了旅游、交通、商务等领域的数据量。
2、爬虫抓取
一般是针对特定的网站或 App。如果我们想要抓取指定的网站数据,比如购物网站上的购物评价等,就需要我们做特定的爬虫抓取。
3、传感器
它基本上采集的是物理信息。比如图像、视频、或者某个物体的速度、热度、压强等。
4、日志采集
这个是统计用户的操作。我们可以在前端进行埋点,在后端进行脚本收集、统计,来分析网站的访问情况,以及使用瓶颈等
二、如何使用开放数据源
1、单位的维度
单位纬度,一般指政府、企业、高校等单位。
下面这张表格列举的就是单位维度的数据源。

2、行业维度
行业纬度,一般指交通、金融、能源等领域。
具体行业数据需要自行百度。
三、如何使用采集数据
1、编写爬虫程序
目前常用的编写爬虫语言有:python、java、nodejs等,其中python是使用最广的。
下面是python爬虫的最常见的三步:
- 请求页面/接口抓取内容。常用requests库来请求,返回的数据可以是html,也可以是json。
- 返回数据解析。常用的解析方法,html对应xpath、正则、bs4等;json就使用json序列化。
- 数据存储。一般解析后的数据都需要存储起来,可以是mangoDB、redis、mysql、文件等。
2、使用采集工具
市面上常见的采集工具有:
- 火车头采集工具
- 八爪鱼采集工具
- 集搜客采集工具
四、如何使用日志采集工具
传感器采集基本上是基于特定的设备,将设备采集的信息进行收集即可,
这里我们就不重点讲解了。下面我们来看日志采集。
为什么要做日志采集呢?日志采集最大的作用,就是通过分析用户访问情况,提升系统的性能,从而提高系统承载量。及时发现系统承载瓶颈,也可以方便技术人员基于用户实际的访问情况进行优化。
日志就是日记的意思,它记录了用户访问网站的全过程:哪些人在什么时间,通过什么渠道(比如搜索引擎、网址输入)来过,都执行了哪些操作;系统是否产生了错误;甚至包括用户的 IP、HTTP 请求的时间,用户代理等。这些日志数据可以被写在一个日志文件中,也可以分成不同的日志文件,比如访问日志、错误日志等。
日志采集可以分两种形式。
1、通过 Web 服务器采集,例如 httpd、Nginx、Tomcat 都自带日志记录功能。同时很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如 Hadoop 的 Chukwa、Cloudera 的 Flume、Facebook 的 Scribe 等,这些工具均采用分布式架构,能够满足每秒数百 MB 的日志数据采集和传输需求。
2、自定义采集用户行为,例如用 JavaScript 代码监听用户的行为、AJAX 异步请求后台记录日志等。
埋点是日志采集的关键步骤,那什么是埋点呢?
埋点就是在有需要的位置采集相应的信息,进行上报。比如某页面的访问情况,包括用户信息、设备信息;或者用户在页面上的操作行为,包括时间长短等。这就是埋点,每一个埋点就像一台摄像头,采集用户行为数据,将数据进行多维度的交叉分析,可真实还原出用户使用场景,和用户使用需求。
那我们要如何进行埋点呢?
埋点就是在你需要统计数据的地方植入统计代码,当然植入代码可以自己写,也可以使用第三方统计工具。我之前讲到“不重复造轮子”的原则,一般来说需要自己写的代码,一般是主营核心业务,对于埋点这类监测性的工具,市场上已经比较成熟,这里推荐你使用第三方的工具,比如友盟、Google Analysis、Talkingdata 等。他们都是采用前端埋点的方式,然后在第三方工具里就可以看到用户的行为数据。但如果我们想要看到更深层的用户操作行为,就需要进行自定义埋点。
五、总结
数据采集是数据分析的关键,很多时候我们会想到 Python 网络爬虫,实际上数据采集的方法、渠道很广,有些可以直接使用开放的数据源,比如想获取比特币历史的价格及交易数据,可以直接从 Kaggle 上下载,不需要自己爬取。
另一方面根据我们的需求,需要采集的数据也不同,比如交通行业,数据采集会和摄像头或者测速仪有关。对于运维人员,日志采集和分析则是关键。所以我们需要针对特定的业务场景,选择适合的采集工具。
最后,日志的采集依靠埋点,需要了解日志采集的过程。文章来源:https://www.toymoban.com/news/detail-712501.html
福利:爬虫示例可以看《Python爬虫:如何下载懂车帝的电动车数据(完整代码)》
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。文章来源地址https://www.toymoban.com/news/detail-712501.html
到了这里,关于数据采集:数据挖掘的基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!