目录
一、GET与POST简介
二、空行和body
三、初识请求报头以及粘包问题
四、认识请求报头剩余部分
一、GET与POST简介
GET https://www.sogou.com/HTTP/1.1
请求报文中的方法,是最常规的方法(获取资源)
POST:传输实体主体的方法
一般来说方法的比重
GET占据八成
POST占据一成
其他的各种杂七杂八的方法一成
方法描述的语义:
GET:从服务器获取XXX💛
POST(常见语境登入,上传):从服务器传输一个XXX💙
但是后来人们都不咋遵守这个语义了
POST和GET主要区别🙆 🙆 🙆
GET把一些自定义的数据放到QueryString里,body通常是空的
POST把一些自定义的数据放到body里,QueryString通常是空的
共性:都是传输到服务器,本质上没有任何区别,放到URL中QueryString用户可以看到,Body不可视。
经典面试题
上传和登入POST更多
本质上数据放到哪里都可以,二者可以相互替代,只需要记住
Body用户不可视(不可收藏)
QueryString:用户可视(收藏夹可以收藏)
网上部分错误说法: 💢 💢 💢
1.比较长的数据放到body中(用POST)原因:GET请求,URL有限制,规定了具体长度上限(1kb,2kb····老黄历,好久之前的事情了)
2。POST比GET安全,我们说的安全都是:容不容易被黑客截胡,就算POST只是让普通的用户看不到数据了,但是并不影响黑客操作,保证安全的关键是对传输的敏感数据进行加密
网上的部分需要注意的发言(不是很对): 💫 💫 💫
1.GET和POST语义不同
设计者最初是赋予了不同的语义,但是实践中不一定完全遵守
如:有的公司,不管你请求还是发送,都是POST
2.GET幂等,POST不是幂等
给你相同的输入,每次都是相同的输出就是幂等,每次输出的不相同就不是幂等(说是幂等其实更像是说你的产出不稳定,随时做出改变)(就像是百度不孕不育的广告,第一个地点肯定不是北京的医院而是你们当地的医院。
3GET请求可以被缓存,POST不可以被缓存
有的操作,比较耗时,与其每次都要重新计算,不如保存下来结果,在下次存的时候,去直接的获取他(但是获取的前提是幂等,换句话说,23放到一起更容易记住)
二、空行和body
空行,相当于一个分隔符分隔了header和body描述了body从哪里开始,body里格式,其实有很多种,此处body格式和之前说过的QueryString
body:encrypt key=password&utf8=%E2%9C%a3&anthenticy_token=jp%24subbyhwj
也是键值对,只不过经过了urlencode的,在登入场景中,这里就包含当前这次登入的用户名和密码等认证信息。
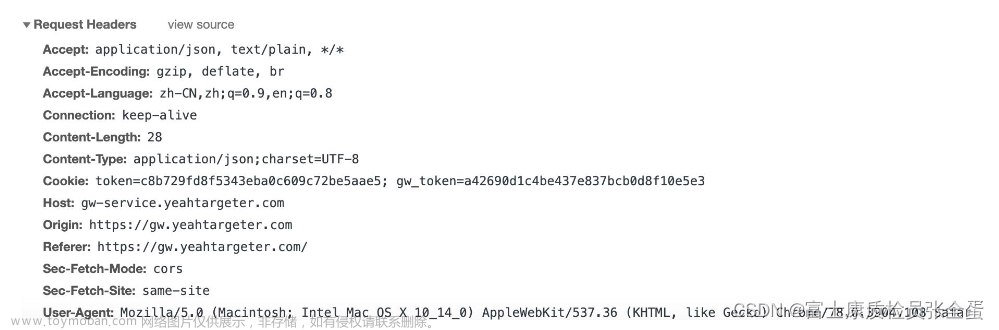
三、初识请求报头以及粘包问题
请求报头也是键值对结构,每一行是一个键值对,键与值之间使用,空格来分隔,例如:
Cookie: xxxx(键和值之间存在空格)
QueryString(body中键值对,完全是程序自定义的,header中键值对,主要是标准规定的(有哪些值,对应的取值有哪些,当然他也会有自定义的部分)
Host:服务器主机地址和端口,Host内容,不实在URL中已经有了吗,为什么还要再去表示一遍呢
原因:HOST内容和URL是一致的,但是也有例外,如果用了代理,就不一定一样了。
Content-Length->描述了body长度是多少字节,有的有body,有的没有,如果没有body,这个字段可以没有,假如说有body,则这个字段就必须有。否则他就是一个非法的请求。
body从空行开始,数Content-Length这么长,就是body结束
这个长度Content-Length有没有让你想起一位经典呢——没错就是我们的TCP粘包问题,HTTP基于TCP来解决,当浏览器连续发起多个HTTP的请求的时候,或者服务器连续返回HTTP服务器的时候,服务器和浏览器如何区分,从哪里到哪里是一个完整的HTTP数据呢(这就是粘包问题,老方法 1:使用分隔符,2:使用长度,HTTP两个都有,假如是GET,没有Body使用空行来作为结尾标点,假如是POST,有Body,使用长度来区分结尾。)


四、认识请求报头其他部分
Content-Type请求的Body中数据格式<->HTTP有多个用途,传输数据也有很多种类
主要分为以下三种:
1.application/x-www-form-urlended:Body的格式就和QueryString一样(登入请求)
2.multiport/form-data 一般上传文件/或者图片会是这种情况(当然也不绝对,码云上传的图片不是这种)
3.application/json:body是json格式
当然这是请求的格式,假如是响应可能更复杂如html:text/html····· image/jpg/applictaion/json/text/css都有可能的,通过Content-Type可以区分body格式是什么,尤其是浏览器,需要根据不同格式来决定如何处理 ,一个网站很多资源是固定不变的(css,图片,js很少变化)为了提高网站的加载速度,会第一次访问之后,把这些资源缓存在本地(也就是你浏览器的电脑硬盘上)下次访问,就不必重新访问网盘。
4.User-Agent(UA)
User-Agent:Mozila/5.0/windows NT 10.0;win64;x64 (操作版本系统, win64,就像是我的电脑ARM架构)AppleWebKit/537.36(KHTML ,like Gecko不用知道),Chrome/116.0.0.0 Safari/537.36
属于是旧时代的遗物了
新的浏览器支持的功能更多,旧的浏览器支持功能少,但是同一时刻,市面上有人使用新的浏览器版本,有人用旧的
如果你此时开发一个网站,是否会选择让他拥有更牛的功能呢?(假如是拥有了,新用户舒服了,但是老用户就无法使用了),聪明的猿们想了个办法:浏览器发送HTTP请求的时候,向服务器自报家门,告诉服务器,我是使用什么系统,什么浏览器上网,服务器可以根据该信息,区分对待。->(让他变的更兼容),UA主要区分的PC端/移动端(PC:电脑,移动端:手机)
Refer:描述了当前页面从哪里来,如果你里面通过浏览器地址直接输入URL,点击收藏夹打开的网页,这个请求带referer,但是如果你是点击了某人网页的内容,产生了跳转,就是referer。
一般广告主可能在多个网站投广告,广告主分别统计来自百度,搜狗,哪个来自哪个端搜索引擎,来给他们💰,当然你的refeerer是明文传输的前提。文章来源:https://www.toymoban.com/news/detail-712888.html
当然了,这样也容易出现一种情况叫做“运营商劫持”,比如说来自搜狗的广告,你把它改成联通的,这样就会提高运营商的收入。文章来源地址https://www.toymoban.com/news/detail-712888.html
到了这里,关于HTTP的请求方法,空行,body,介绍请求报头的内部以及粘包问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!