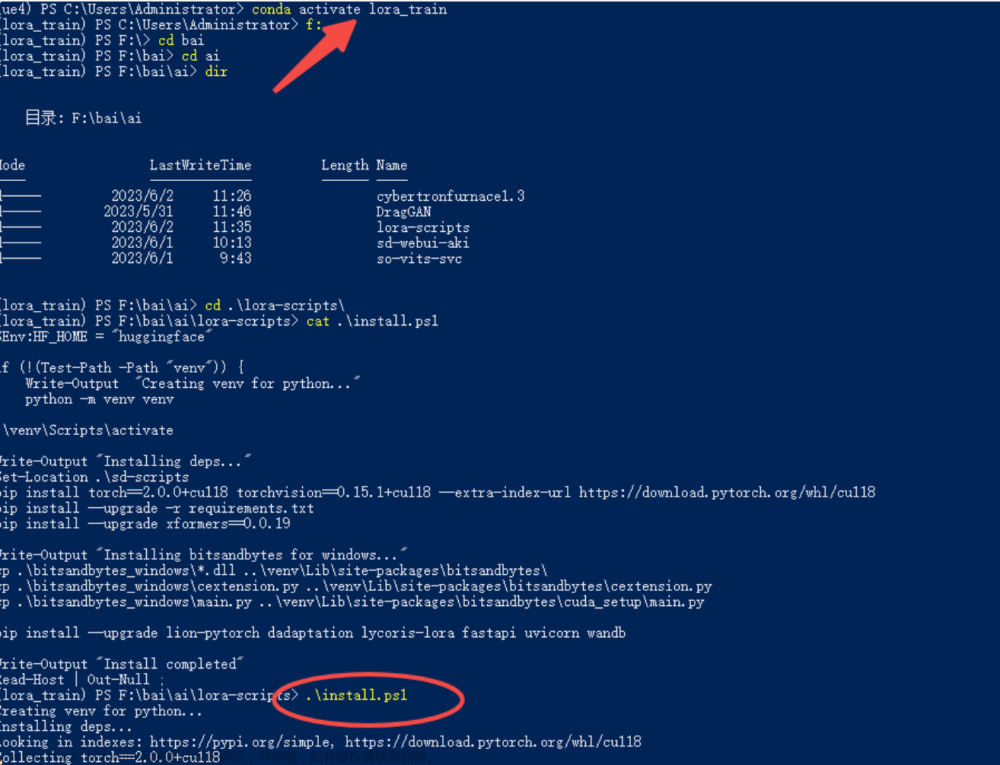
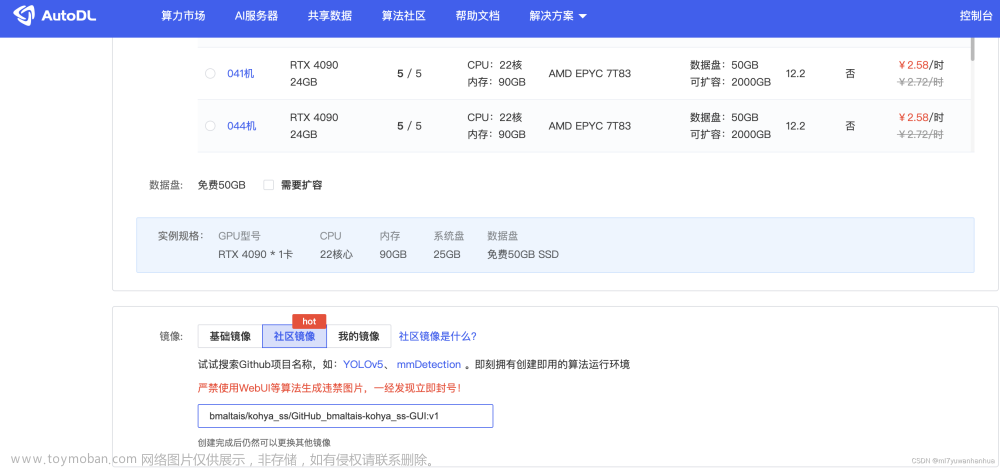
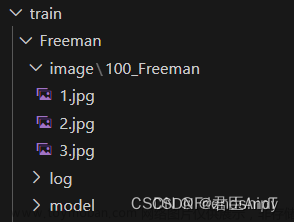
▷ 训练集准备
- 声明: 该文中所涉及到的女神图片均来自于网络,仅用作技术教程演示,图片已码
- 一般同一个训练集需要准备
20~40张不同角度的照片,当然可以更多,只是训练的时间会变长而已 - 比如如果训练的是人物,就准备同一个人物的不同角度的照片,并且各种表情都有是最好的,图片背景杂色越少越好
- 所以可以借助在线工具:在线消除背景,来让图片更加的干净
- 除了图片要干净外,另外对于图片的分辨率和尺寸是有要求的,所有图片的尺寸必须保持一致,并且是
64的倍数 - 所以可以借助在线工具:
文章来源地址https://www.toymoban.com/news/detail-713340.html
文章来源:https://www.toymoban.com/news/detail-713340.html
到了这里,关于〔024〕Stable Diffusion 之 模型训练 篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!