前言
鉴于“一课一得,一事一展”的要求,我们小组选择了第一个项目——集群搭建:使用Hadoop、Hbase搭建新能源汽车大数据平台。我主要负责的部分是集群的基本环境搭建,也就是下图的要求1,2和3,要求4咱宿舍说摇色子看谁摇最大谁来做,本人很社恐还好没摇着我。


一、准备三台虚拟机
之前上课的时候我就已经用VMware Workstation 15 player创过了一台虚拟机并做了Hadoop的伪分布式安装,所以就不再从头演示,直接在这基础上接着讲了
1.在虚拟机上找到之前安装Hadoop的路径
鼠标右键点击有深蓝色底纹文件名为hadoop的文件,在弹出的选项中选择 设置——选项,全选然后复制工作目录下的文件路径,到D盘粘贴找出hadoop的文件
2、新建三个文件夹
找到这些文件以后全选复制下来,家人们先别急着粘贴,咱就是说,先新建三个文件夹,分别取名为master、slave1、slave2,然后再把刚刚复制好的文件分别粘贴到这三个文件夹中。
3.用vmware分别打开master、slave1、slave2文件夹下的虚拟机
以master为例。首先Player>文件>打开>…弹出一个对话框,然后在对话框中选中要vmx为后缀的文件。打开以后右键点击虚拟机进行重命名。
打开后,默认是选中的,此时右键就可以重命名了, 最终打开三个虚拟机,并重命名
作业的要求2是集群至少可以存储100G的数据,但是我忘记了,不过可以在建虚拟机的时候就把磁盘改成100G,我感觉应该是这样,我也不太懂。
二、修改master、slave1、slave2的IP
因为master、slave1、slave2这三台虚拟机是从原有的虚拟机拷贝过来的,所以所有的东西都是一样的,包括环境变量、已安装的程序(jdk、redis、hadoop、hbase等)、IP、主机名。不同的主机,IP肯定是不能一样的,所以要修改这三台虚拟机的IP和主机名。
进入虚拟机后,通过执行以下代码修改主机的IP地址:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
1.ip修改后,重启网卡:
systemctl restart network
2.ping一下外网确认是否可以访问
ping www.baidu.com
3.修改主机名,改为master
hostnamectl set-hostname master
最后退出root,再重新登录,命令行提示符就可以看到新的主机名了,剩余的slave1和slave2也是一样的操作。
三、修改master、slave1、slave2的IP映射
通过以下代码添加三条映射记录
vi /etc/hosts

能够成功ping三台主机就说明映射配置成功
为了避免手写错误,master的host映射配置好后,可以通过scp命令,将master修改好的/etc/hosts文件,同步到slave1、slave2主机上。
scp /etc/hosts root@slave1:/etc
scp /etc/hosts root@slave1:/etc
同步成功:
由于master、slave1、slave2这三个节点都是从之前已经安装好的Hadoop伪分布式的虚拟机复制得来的,而当时已经设置好了免密登录,所以就不用再设置了,也就是master可以免密登录到master、slave1、slave2。同理,之前已经设置了不允许防火墙自己开机,默认开机是关闭的,所以也不需要再操作,没操作的同学还是需要再补上的——设置免密登录以及关闭防火墙。
四、修改master主机上的hadoop配置文件
1、修改core-site.xml文件
先cd $HADOOP_HOME/etc/hadoop然后再vi core-site.xml
cd $HADOOP_HOME/etc/hadoop
vi core-site.xml
配置内容如下:
记得要把存放namenode、datanode数据的根路径的tem换成tmp啊!!!!不然他会存放到临时路径下,到时候文件太多会被删掉的!!!怪不得我之前还说找半天为什么找不到我文件夹。
然后就是把数据块副本数改为3,命令如下:修改为3即可文章来源:https://www.toymoban.com/news/detail-713963.html
vi hdfs-site.xml
五、Hadoop高可用集群搭建
1、Linux部署jdk
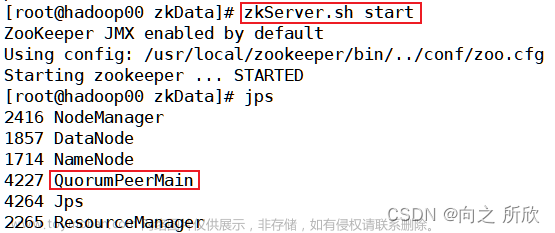
由于我之前上课的时候就已经部署过jdk了所以就不再进行讲解了,没有部署的同学还是要部署的——找一份适用于Linux版本的jdk压缩包—>把压缩文件解压到想存放的的位置然后进行解压---->修改环境变量(如果权限不够的话切换到root用户)只需要添加JAVA_HOME和PATH即可,最后只需要重新启用环境变量(source /etc/profile)再检验(java -version)一下就好啦。成功了的话就是这样子的。 文章来源地址https://www.toymoban.com/news/detail-713963.html
文章来源地址https://www.toymoban.com/news/detail-713963.html
到了这里,关于hadoop——环境配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!