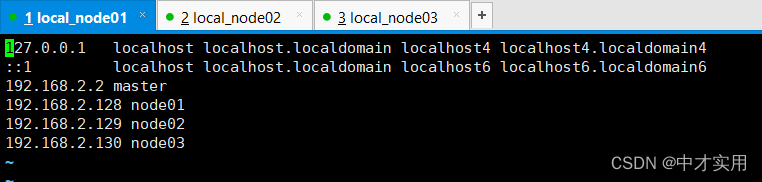
配置核心文件
core-site.xml
编辑core-site.xml(进入hadoop文件夹内)
vim etc/hadoop/core-site.xml
--------------------------------------------------------
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.deaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
----------------------------------------------------------hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
---------------------------------------------------------
<configuration>
<!-- nn web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!-- 2nn web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102</value>
</property>
</configuration>
----------------------------------------------------------yarn-site.xml
vim etc/hadoop/hdfs-site.xml
----------------------------------------------------------
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>varn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>varn.nodemanager.eny-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOPYARN_HOME.HADOOP_MAPRED_HOME</value>
</property>
</configuration>
-----------------------------------------------------------mapred-site.xml
vim etc/hadoop/mapred-site.xml
-----------------------------------------------------------
<confiquration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</confiquration>
-----------------------------------------------------------配置完后要分发给其他服务器,可以使用之前写的分发脚本xsync进行快速分发
配置workers(各集群节点)
vim etc/hadoop/workers
-----------------------------------------------------------
hadoop102
hadoop103
hadoop104
-----------------------------------------------------------启动集群
如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode(注意:格式化NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停上 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化)
hdfs namenode -format启动hdfs
sbin/start-dfs.sh在配置了ResourceManager(hadoop103)的节点启动YARN
sbin/start-yarn.shweb查看HDFS的NameNode:
浏览器输入:http://hadoop102:9870文章来源:https://www.toymoban.com/news/detail-714181.html
web查看YARN的ResourceManager
浏览器输入: http://hadoop103:8088文章来源地址https://www.toymoban.com/news/detail-714181.html
集群基本测试
上传文件到集群
hadoop fs -mkdir /xxx
hadoop fs -put /xxx查看HDFS在磁盘存储文件内容
cd /hadoop-3.1.3/data/dfs/data/current/BP-349999175-192.168.10/current/finalized/subdiro/subdir0
cat blk_1073741825到了这里,关于Hadoop学习-集群配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!