Hash算法的问题
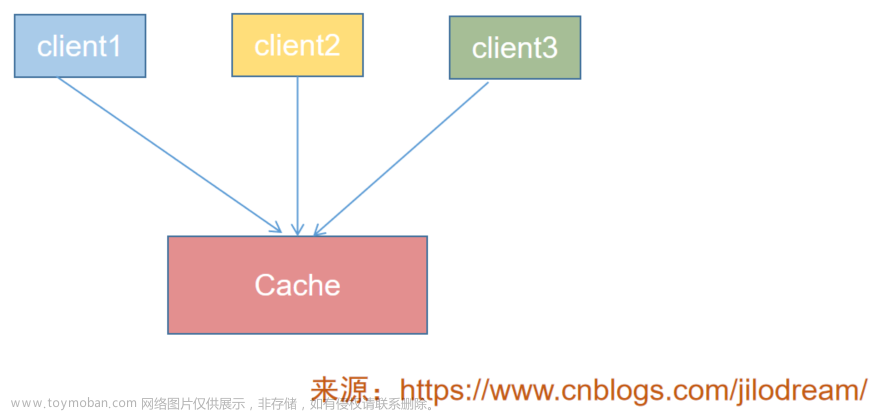
今天看下一致性hash,常见的负载均衡可能使用过hash,比如nginx中,如果使用session最简单就是通过hash,比如根据用户的请求ip进行hash,让不同用户的请求打到同一台服务器,这样状态处理起来最简单,对于session来说,如果现在重新上线了一台服务器,导致了所有请求hash之后的得到的服务器地址变了,也就是session可能全部丢失了,即使用户对应的服务器并没有重启,但是因为服务器数量发生了变化,导致分配到的服务器有所改变,这就是hash带来的问题。
一致性hash的使用场景
那么一致性hash就是解决hash的这些问题诞生的,一致性hash常见的落地场景可以想象下redis的数据,redis是设计了16384的hash槽,每个数据来的根据key做hash,然后分配到固定的hash槽,redis需要集群分片的时候不具体区分每一个key,是去分hash槽,然后新增节点的之后只需要分配给其一些hash槽,然后转移对应的数据过去即可,删除节点的时候也是,只需要把这个节点的数据分配给其他节点即可,没涉及到的数据不会有影响。
一致性hash概念
所以一致性hash的定义也就是,我先分配很多的hash节点,然后我每一个实际的提供服务的节点,负责一部分的hash节点,hash节点是固定的(比实际节点大很多),然后上下线节点只需要调整实际节点负责的节点数量即可。
实际大家说的hash环的问题,就是说,我的很多虚拟节点(hash节点)组成的环,然后让实际的提供服务的节点尽量均匀的落到hash节点上,后续的请求或者说数据,按照hash之后也落到虚拟hash节点上,这个节点可能并没有实际的服务节点,他就可以向后遍历找到对应提供服务的节点,也就代表着一个实际提供服务的节点负责他前面的所有虚拟节点,直到遇到上一个实际服务的节点。
一致性hash需要处理的问题
这样可能存在的问题就是实际服务提供者的hash结果倾斜怎么办,也就是所有节点都落到一片去了,这样前面的节点就需要负责绝大部分的请求,还是要想办法让其尽量均匀,也就是要给每个实际节点,可以多种hash算法,生成多个节点,让其尽可能均匀的分布到环上,让请求均匀分配到节点上
来看下dubbo怎么具体实现的这个问题,关键代码如下:文章来源:https://www.toymoban.com/news/detail-714212.html
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
// treeMap方便向上取
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// 虚拟节点数量?默认160,这里是一个服务虚拟出来的节点
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
// 这里也就是一个服务默认先虚拟160个节点
byte[] digest = Bytes.getMD5(address + i);
for (int h = 0; h < 4; h++) {
// 分别4位,4位的进行运算,也就是放四个值,每个invoker,使用不同位数得到的hash值
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
// hash算法,对其每一位进行处理,想要均匀
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
// 具体的选择算法,也就是hash结果选择,关键结构逻辑参考构造方法
public Invoker<T> select(Invocation invocation) {
byte[] digest = Bytes.getMD5(RpcUtils.getMethodName(invocation));
return selectForKey(hash(digest, 0));
}
// 具体的选择方法
private Invoker<T> selectForKey(long hash) {
// 向上取,TreeMap的方法
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
if (entry == null) {
// 没取到的取第一个,也就是造成一个环的概念,数据落到最后一个节点后面
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
总结
可以看到dubbo为了处理数据倾斜的问题,默认虚拟160个节点,然后根据地址加上对应的值,然后又采用每一位数字的hash算法进行散列,得到的值,采用的数据结构就是TreeMap,是一个可排序的Map,可以直接向上取,ceilingEntry,数据过来之后hash得到值,然后取对应的节点,TreeMap兼具一定的查找性能能文章来源地址https://www.toymoban.com/news/detail-714212.html
到了这里,关于一致性hash负载均衡的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!