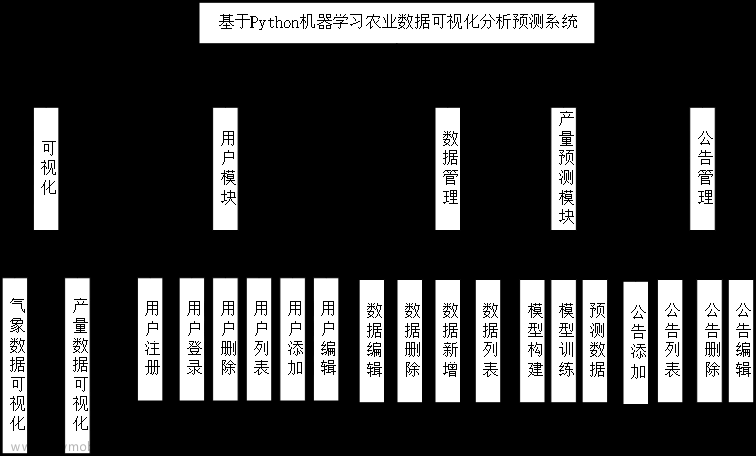
1.什么是XGBoost?
GBDT,它是一种基于boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t − 1 t-1 t−1 棵树的预测结果与训练样本真实值的残差。XGBoost对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想没有大的变化。
2.XGBoost的核心原理
2.1 如何构造目标函数?
对于一个给定有 n n n 个样本和 m m m 个特征的数据集 D = { ( x i , y i ) } ( ∣ D ∣ = n , x i ∈ R m , y i ∈ R ) D=\{(x_i,y_i)\}(|D|=n, x_i\in \mathbb{R}^m, y_i\in \mathbb{R} ) D={(xi,yi)}(∣D∣=n,xi∈Rm,yi∈R)。 树集成算法使用个数为 K K K 的加法模型(如图1)来预测输出。

预测,这一家子人中每个人想玩游戏的意愿值?
先训练出来第一棵决策树, 预测小男孩想玩游戏的意愿是 2 2 2, 然后发现离标准答案差一些,又训练出来了第二棵决策树, 预测小男孩想玩游戏的意愿是 0.9 0.9 0.9, 那么两个相加就是最终的答案 2.9 2.9 2.9。
1.假设训练了
K
K
K 棵树,对于第
i
i
i 个样本的(最终)预测值为:
y
^
i
=
ϕ
(
x
i
)
=
∑
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
(
1
)
\hat y_i = \phi(\bold x_i) = \sum^K_{k=1}f_k(\bold x_i), \quad f_k\in F \qquad\qquad\qquad (1)
y^i=ϕ(xi)=k=1∑Kfk(xi),fk∈F(1)
2.目标函数为(损失函数+模型复杂度(penalty))
o
b
j
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
)
+
∑
k
=
1
K
Ω
(
f
k
)
(
2
)
obj = \sum\limits_{i=1}\limits^nl(y_i,\hat y_i) + \sum\limits^K\limits_{k=1} \Omega(f_k) \qquad \qquad (2)\\
obj=i=1∑nl(yi,y^i)+k=1∑KΩ(fk)(2)
Q:如何描述树模型的复杂度?
A:叶子结点的个数、树的深度、叶子结点值
3.加法模型
当训练第 k k k 棵树时,前 k − 1 k-1 k−1 棵树都是已知的:

对于给定的样本
x
i
x_i
xi而言:
y
^
i
(
0
)
=
0
(
d
e
f
a
u
l
t
c
a
s
e
)
y
^
i
(
1
)
=
f
1
(
x
i
)
=
f
1
(
x
i
)
+
y
^
i
(
0
)
y
^
i
(
2
)
=
f
2
(
x
i
)
+
f
1
(
x
i
)
=
f
2
(
x
i
)
+
y
^
i
(
1
)
⋮
y
^
i
(
k
)
=
f
k
(
x
i
)
+
⋯
+
f
2
(
x
i
)
+
f
1
(
x
i
)
=
f
k
(
x
i
)
+
y
^
i
(
k
−
1
)
\begin{align} & \hat y^{(0)}_i = 0 \ (default\ case) \\[2ex] & \hat y^{(1)}_i = f_1(x_i)=f_1(x_i)+\hat y^{(0)}_i \\[2ex] & \hat y^{(2)}_i = f_2(x_i)+f_1(x_i)=f_2(x_i)+\hat y^{(1)}_i \\[2ex] & \qquad\qquad\qquad\vdots \\[2ex] & \hat y^{(k)}_i = f_k(x_i)+\cdots+f_2(x_i)+f_1(x_i)=f_k(x_i)+\hat y^{(k-1)}_i \\[2ex] \end{align}
y^i(0)=0 (default case)y^i(1)=f1(xi)=f1(xi)+y^i(0)y^i(2)=f2(xi)+f1(xi)=f2(xi)+y^i(1)⋮y^i(k)=fk(xi)+⋯+f2(xi)+f1(xi)=fk(xi)+y^i(k−1)
因为
f
f
f 是决策树,而不是数值型的向量,所以我们不能使用梯度下降法进行优化。XGBoost是前项分布算法,我们可以通过贪心算法寻找局部最优解:每一次迭代寻找是损失函数降低最大的
f
f
f(CART树)。
此时的目标函数(目标:最小化)可以改写成:
o
b
j
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
k
)
)
+
∑
k
=
1
K
Ω
(
f
k
)
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
k
−
1
)
+
f
k
(
x
i
)
)
+
∑
j
=
1
K
−
1
Ω
(
f
j
)
+
Ω
(
f
k
)
(
3
)
\begin{align} obj &= \sum\limits_{i=1}\limits^nl(y_i,\hat y^{(k)}_i) + \sum\limits^K\limits_{k=1} \Omega(f_k) \\[2ex] &=\sum\limits_{i=1}\limits^nl\left(y_i,\hat y^{(k-1)}_i+f_k(x_i)\right) + \sum\limits^{K-1}\limits_{j=1} \Omega(f_j)+\Omega(f_k) \qquad \qquad (3) \end{align}
obj=i=1∑nl(yi,y^i(k))+k=1∑KΩ(fk)=i=1∑nl(yi,y^i(k−1)+fk(xi))+j=1∑K−1Ω(fj)+Ω(fk)(3)
其中
y
^
i
(
k
−
1
)
、
∑
j
=
1
K
−
1
Ω
(
f
j
)
\hat y^{(k-1)}_i、\sum\limits^{K-1}\limits_{j=1} \Omega(f_j)
y^i(k−1)、j=1∑K−1Ω(fj) 均是常量。
当训练第
k
k
k 棵树时,最小化目标函数有:
a
r
g
m
i
n
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
k
−
1
)
+
f
k
(
x
i
)
)
+
Ω
(
f
k
)
arg\ min \sum\limits_{i=1}\limits^n l\left(y_i,\hat y^{(k-1)}_i+f_k(x_i)\right)+\Omega(f_k)
arg mini=1∑nl(yi,y^i(k−1)+fk(xi))+Ω(fk)
注:
- y i y_i yi:真实值
- y ^ i ( k − 1 ) \hat y^{(k-1)}_i y^i(k−1):前 k − 1 k-1 k−1棵树的预测值
- f k ( x i ) f_k(x_i) fk(xi):第 k k k 棵树的预测值
- Ω ( f k ) \Omega(f_k) Ω(fk):第 k k k 棵树的复杂度
2.2 如何优化目标函数?
在数学中,我们可以用泰勒公式近似
f
(
x
)
f(x)
f(x) ,具体如下式。XGBoost 对损失函数运用二阶展开来近似。
f
(
x
0
+
Δ
x
)
≈
f
(
x
0
)
+
f
(
1
)
(
x
0
)
Δ
x
+
1
2
f
(
2
)
(
x
0
)
Δ
x
2
+
⋯
+
o
(
Δ
x
2
)
f(x_0+\Delta x) ≈ f(x_0) + f^{(1)}(x_0)\Delta x+\frac{1}{2}f^{(2)}(x_0)\Delta x^2+\cdots+o(\Delta x^2)
f(x0+Δx)≈f(x0)+f(1)(x0)Δx+21f(2)(x0)Δx2+⋯+o(Δx2)
对应XGBoost的损失函数,则有:
f
(
x
+
Δ
x
)
=
l
(
y
i
,
y
^
i
(
k
−
1
)
+
f
k
(
x
i
)
)
f(x+\Delta x) = l(y_i,\hat y^{(k-1)}_i+f_k(x_i))
f(x+Δx)=l(yi,y^i(k−1)+fk(xi))
o b j = ∑ i = 1 n l ( y i , y ^ i ( k − 1 ) + f k ( x i ) ) + Ω ( f k ) = ∑ i = 1 n [ l ( y i , y ^ ( k − 1 ) ) + ∂ l ( 1 ) ( y i , y ^ ( k − 1 ) ) ∂ y i f k ( x i ) + 1 2 ∂ l ( 2 ) ( y i , y ^ ( k − 1 ) ) ∂ y i f k ( x i ) 2 ] + Ω ( f k ) = ∑ i = 1 n [ l ( y i , y ^ ( k − 1 ) ) + g i f k ( x i ) + 1 2 h i f k ( x i ) 2 ] + Ω ( f k ) ( 4 ) \begin{align} obj &= \sum\limits_{i=1}\limits^n l\left(y_i,\hat y^{(k-1)}_i+f_k(x_i)\right)+\Omega(f_k)\\[2ex] &=\sum\limits_{i=1}\limits^n\left[l(y_i,\hat y^{(k-1)})+\frac{\partial l^{(1)}(y_i,\hat y^{(k-1)})}{\partial y_i}f_k(x_i)+\frac{1}{2}\frac{\partial l^{(2)}(y_i,\hat y^{(k-1)})}{\partial y_i}f_k(x_i)^2\right]+\Omega(f_k)\\[2ex] &=\sum\limits_{i=1}\limits^n\left[l(y_i,\hat y^{(k-1)})+g_if_k(x_i)+\frac{1}{2}h_if_k(x_i)^2\right]+\Omega(f_k)\qquad\qquad (4) \end{align} obj=i=1∑nl(yi,y^i(k−1)+fk(xi))+Ω(fk)=i=1∑n[l(yi,y^(k−1))+∂yi∂l(1)(yi,y^(k−1))fk(xi)+21∂yi∂l(2)(yi,y^(k−1))fk(xi)2]+Ω(fk)=i=1∑n[l(yi,y^(k−1))+gifk(xi)+21hifk(xi)2]+Ω(fk)(4)
上述式子转换为优化如下式子:
a
r
g
m
i
n
∑
i
=
1
n
(
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
(
x
i
)
2
)
+
Ω
(
f
k
)
arg\ min\ \sum\limits_{i=1}\limits^n\left(g_if_k(x_i)+\frac{1}{2}h_if_k(x_i)^2\right)+\Omega(f_k)
arg min i=1∑n(gifk(xi)+21hifk(xi)2)+Ω(fk)
注:当训练第
k
k
k 棵树时,
{
h
i
,
g
i
}
\{h_i,g_i\}
{hi,gi} 均是已知的。
2.3 如何将树结构引入到目标函数中?
新的目标函数为:
a
r
g
m
i
n
∑
i
=
1
n
(
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
(
x
i
)
2
)
+
Ω
(
f
k
)
arg\ min\ \sum\limits_{i=1}\limits^n\left(g_if_k(x_i)+\frac{1}{2}h_if_k(x_i)^2\right)+\Omega(f_k)
arg min i=1∑n(gifk(xi)+21hifk(xi)2)+Ω(fk)
现在是如何将
f
k
(
x
i
)
f_k(x_i)
fk(xi)、
Ω
(
f
k
)
\Omega(f_k)
Ω(fk) 两者参数化?如何描述一棵树的复杂度?
树的参数化(如何表达一棵树?)

-
叶子结点的数值(leaf value)
w = ( w 1 , w 2 , w 3 ) = ( 15 , 12 , 20 ) w=(w_1,w_2,w_3)=(15,12,20) w=(w1,w2,w3)=(15,12,20)
-
q ( x ) q(x) q(x) :样本 x x x 的位置(在哪个位置) 将输入 x x x 映射到某个叶子结点上
q ( x 1 ) = 1 q(x_1)=1 q(x1)=1 q ( x 2 ) = 3 q(x_2)=3 q(x2)=3 q ( x 3 ) = 1 q(x_3)=1 q(x3)=1 q ( x 4 ) = 2 q(x_4)=2 q(x4)=2 q ( x 5 ) = 3 q(x_5)=3 q(x5)=3
根据上述信息可以得到: f k ( x i ) = w q ( x i ) f_k(x_i)=w_{q(x_i)} fk(xi)=wq(xi)
定义函数: I j = { i ∣ q ( x i ) = j } I_j=\{i|q(x_i)=j\} Ij={i∣q(xi)=j} 表示哪些样本落在第 j j j 个叶子结点上。
I 1 = { 1 , 3 } I_1=\{1,3\} I1={1,3}, I 2 = { 4 } I_2=\{4\} I2={4}, I 3 = { 2 , 5 } I_3=\{2,5\} I3={2,5}
树模型的复杂度:叶子结点的个数,树的深度,叶子结点的数值。则有:
Ω
(
f
k
)
=
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
(
5
)
\Omega(f_k) = \gamma T+ \frac{1}{2}\lambda\sum\limits_{j=1}\limits^Tw_j^2 \qquad\qquad (5)
Ω(fk)=γT+21λj=1∑Twj2(5)
其中
T
T
T 表示叶子结点的个数,
w
j
w_j
wj 表示叶子结点的权重,
γ
、
λ
\gamma、\lambda
γ、λ 均为超参数。
最终目标函数如下:
o
b
j
=
a
r
g
m
i
n
∑
i
=
1
n
(
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
(
x
i
)
2
)
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
(
6
)
obj = arg\ min\ \sum\limits_{i=1}\limits^n\left(g_if_k(x_i)+\frac{1}{2}h_if_k(x_i)^2\right)+\gamma T+ \frac{1}{2}\lambda\sum\limits_{j=1}\limits^Tw_j^2 \qquad\qquad (6)
obj=arg min i=1∑n(gifk(xi)+21hifk(xi)2)+γT+21λj=1∑Twj2(6)
现在就是求解最优解的问题。 为了使正则项和经验风险项合并到一起。我们把在样本层面上求和的经验风险项,转换为叶节点层面上的求和。
o
b
j
=
a
r
g
m
i
n
∑
i
=
1
n
(
g
i
f
k
(
x
i
)
+
1
2
h
i
f
k
(
x
i
)
2
)
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
=
a
r
g
m
i
n
∑
j
=
1
T
[
g
i
w
q
(
x
i
)
+
1
2
h
i
w
q
(
x
i
)
2
]
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
=
a
r
g
m
i
n
∑
j
=
1
T
[
∑
i
∈
I
j
g
i
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
(
7
)
\begin{align} obj &= arg\ min\ \sum\limits_{i=1}\limits^n\left(g_if_k(x_i)+\frac{1}{2}h_if_k(x_i)^2\right)+\gamma T+ \frac{1}{2}\lambda\sum\limits_{j=1}\limits^Tw_j^2\\[2ex] &= arg\ min\ \sum\limits_{j=1}\limits^T\left[g_iw_q(x_i)+\frac{1}{2}h_iw_q(x_i)^2\right]+\gamma T+ \frac{1}{2}\lambda\sum\limits_{j=1}\limits^Tw_j^2\\[2ex] &= arg\ min\ \sum\limits_{j=1}\limits^T\left[\sum\limits_{i\in I_j}g_iw_j+\frac{1}{2}(\sum\limits_{i\in I_j}h_i+\lambda)w_j^2\right]+\gamma T \qquad\qquad(7) \end{align}
obj=arg min i=1∑n(gifk(xi)+21hifk(xi)2)+γT+21λj=1∑Twj2=arg min j=1∑T[giwq(xi)+21hiwq(xi)2]+γT+21λj=1∑Twj2=arg min j=1∑T
i∈Ij∑giwj+21(i∈Ij∑hi+λ)wj2
+γT(7)
进一步简化表达,令
∑
i
∈
I
j
g
i
=
G
j
、
∑
i
∈
I
j
h
i
=
H
j
\sum\limits_{i\in I_j}g_i=G_j、\sum\limits_{i\in I_j}h_i=H_j
i∈Ij∑gi=Gj、i∈Ij∑hi=Hj, 注意这里
G
G
G 和
H
H
H 都是关于
j
j
j 的函数:
o
b
j
=
a
r
g
m
i
n
∑
j
=
1
T
[
∑
i
∈
I
j
g
i
w
j
+
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
=
a
r
g
m
i
n
∑
j
=
1
T
[
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
]
+
γ
T
(
8
)
\begin{align} obj &= arg\ min\ \sum\limits_{j=1}\limits^T\left[\sum\limits_{i\in I_j}g_iw_j+\frac{1}{2}(\sum\limits_{i\in I_j}h_i+\lambda)w_j^2\right]+\gamma T \\[2ex] &=arg\ min\ \sum\limits_{j=1}\limits^T\left[G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2\right]+\gamma T\qquad\qquad(8) \end{align}
obj=arg min j=1∑T
i∈Ij∑giwj+21(i∈Ij∑hi+λ)wj2
+γT=arg min j=1∑T[Gjwj+21(Hj+λ)wj2]+γT(8)
可以看出,若一棵树的结构已经确定,则各个节点内的样本
(
x
i
,
y
i
,
g
i
,
h
i
)
(x_i,y_i,g_i,h_i)
(xi,yi,gi,hi) 也是确定的,即
G
j
G_j
Gj,
H
j
H_j
Hj 、
T
T
T 被确定,每个叶节点输出的回归值应该使得上式最小,由二次函数极值点:
w
j
∗
=
−
G
j
H
j
+
λ
w^*_j=-\frac{G_j}{H_j+\lambda}
wj∗=−Hj+λGj
按此规则输出回归值后,目标函数值也就是树的评分如下公式,其值越小代表树的结构越好。观察下式,树的评分也可以理解成所有叶节点的评分之和:
o
b
j
∗
=
−
1
2
∑
j
=
1
T
G
j
2
H
j
+
λ
+
γ
T
(
9
)
obj^*= -\frac{1}{2}\sum\limits_{j=1}\limits^T\frac{G_j^2}{H_j+\lambda}+\gamma T\qquad\qquad(9)
obj∗=−21j=1∑THj+λGj2+γT(9)
2.4 如何去寻找最优的树结构?
目标:寻找最优树的形状,这是一个暴力搜索的问题。如果树的结构已知的情况下,可以算出 o b j ∗ obj^* obj∗ 最小的树。通常来说不可能枚举出所有的树结构 q q q,而是用贪心算法,从一个叶子开始分裂,反复给树添加分支。决策树建立的过程就是一个不确定性减小的过程。
现有样本
{
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
}
\{1,2,3,4,5,6,7,8\}
{1,2,3,4,5,6,7,8},建立一棵树。对于某个特征
f
1
f_1
f1, 那么如何计算
f
1
(
s
c
o
r
e
)
f_1(score)
f1(score) ?
f
1
(
s
c
o
r
e
)
=
原来的不确定性
(
o
b
j
)
−
之后的不确定性
(
o
b
j
)
f_1(score) = 原来的不确定性(obj)-之后的不确定性(obj)
f1(score)=原来的不确定性(obj)−之后的不确定性(obj)
特征:
s
c
o
r
e
=
o
b
j
k
∗
(
o
l
d
)
−
o
b
j
k
∗
(
n
e
w
)
score = obj^*_k(old)-obj^*_k(new)
score=objk∗(old)−objk∗(new)
由上述的结果可得:
o
b
j
∗
=
−
1
2
∑
j
=
1
T
G
j
2
H
j
+
λ
+
γ
T
obj^*= -\frac{1}{2}\sum\limits_{j=1}\limits^T\frac{G_j^2}{H_j+\lambda}+\gamma T
obj∗=−21j=1∑THj+λGj2+γT
o b j ∗ ( o l d ) = − 1 2 [ ( G 7 + G 8 ) 2 H 7 + H 8 + λ + ( G 1 + G 2 + ⋯ + G 6 ) 2 H 1 + H 2 + ⋯ + H 6 + λ ] + γ ∗ 2 o b j ∗ ( n e w ) = − 1 2 [ ( G 7 + G 8 ) 2 H 7 + H 8 + λ + ( G 1 + G 3 + G 5 ) 2 H 1 + H 3 + H 5 + λ + ( G 2 + G 4 + G 6 ) 2 H 2 + H 4 + H 6 + λ ] + γ ∗ 3 o b j ∗ ( o l d ) − o b j ∗ ( n e w ) = 1 2 [ G L 2 H L + λ + G R 2 H R + λ + ( G L + G R ) 2 H L + H R + λ ] − γ G L = G 1 + G 3 + G 5 G R = G 2 + G 4 + G 6 H L = H 1 + H 3 + H 5 H R = H 2 + H 4 + H 6 \begin{align} & obj^*(old)=-\frac{1}{2}\left[\frac{(G_7+G_8)^2}{H_7+H_8+\lambda}+\frac{(G_1+G_2+\cdots+G_6)^2}{H_1+H_2+\cdots+H_6+\lambda}\right]+\gamma * 2 \\[2ex] & obj^*(new)=-\frac{1}{2}\left[\frac{(G_7+G_8)^2}{H_7+H_8+\lambda}+\frac{(G_1+G_3+G_5)^2}{H_1+H_3+H_5+\lambda}+\frac{(G_2+G_4+G_6)^2}{H_2+H_4+H_6+\lambda}\right]+\gamma * 3 \\[2ex] & obj^*(old)-obj^*(new)=\frac{1}{2}\left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}+\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right]-\gamma \\[2ex] & G_L= G_1+G_3+G_5 \qquad G_R= G_2+G_4+G_6 \\[2ex] & H_L= H_1+H_3+H_5 \qquad H_R= H_2+H_4+H_6 \end{align} obj∗(old)=−21[H7+H8+λ(G7+G8)2+H1+H2+⋯+H6+λ(G1+G2+⋯+G6)2]+γ∗2obj∗(new)=−21[H7+H8+λ(G7+G8)2+H1+H3+H5+λ(G1+G3+G5)2+H2+H4+H6+λ(G2+G4+G6)2]+γ∗3obj∗(old)−obj∗(new)=21[HL+λGL2+HR+λGR2+HL+HR+λ(GL+GR)2]−γGL=G1+G3+G5GR=G2+G4+G6HL=H1+H3+H5HR=H2+H4+H6
因此分裂收益的表达式为:
G
a
i
n
=
1
2
[
(
∑
i
∈
I
L
g
i
)
2
∑
i
∈
I
L
h
i
+
λ
+
(
∑
i
∈
I
R
g
i
)
2
∑
i
∈
I
R
h
i
+
λ
−
(
∑
i
∈
I
I
g
i
)
2
∑
i
∈
I
I
h
i
+
λ
]
−
γ
(
10
)
Gain= \frac{1}{2}\Big[\frac{(\sum_{i\in I_L} gi)^2}{\sum_{i\in I_L}h_i+\lambda} + \frac{(\sum_{i\in I_R} gi)^2}{\sum_{i\in I_R}h_i+\lambda}-\frac{(\sum_{i\in I_I} gi)^2}{\sum_{i\in I_I}h_i+\lambda}\Big] - \gamma \qquad\qquad (10)
Gain=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈IIhi+λ(∑i∈IIgi)2]−γ(10)
G a i n Gain Gain 值越大,说明分裂之后能使得目标函数减小的越多,也就是越好。
3.分裂查找算法
3.1 贪心准则
XGBoost 会对特征值排序后遍历划分点,将其中最优的分裂收益作为该特征的分裂收益,选取具有最优分裂收益的特征作为当前节点的划分特征,按其最优划分点进行二叉划分,得到左右子树。 分裂收益的表达式为:
G
a
i
n
=
1
2
[
(
∑
i
∈
I
L
g
i
)
2
∑
i
∈
I
L
h
i
+
λ
+
(
∑
i
∈
I
R
g
i
)
2
∑
i
∈
I
R
h
i
+
λ
−
(
∑
i
∈
I
I
g
i
)
2
∑
i
∈
I
I
h
i
+
λ
]
−
γ
Gain= \frac{1}{2}\Big[\frac{(\sum_{i\in I_L} gi)^2}{\sum_{i\in I_L}h_i+\lambda} + \frac{(\sum_{i\in I_R} gi)^2}{\sum_{i\in I_R}h_i+\lambda}-\frac{(\sum_{i\in I_I} gi)^2}{\sum_{i\in I_I}h_i+\lambda}\Big] - \gamma
Gain=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈IIhi+λ(∑i∈IIgi)2]−γ

上图是一次节点分裂过程,很自然地,分裂收益是树A的评分减去树B的评分。由(4),虚线框外的叶节点,即非分裂节点的评分均被抵消,只留下分裂后的LR节点和分裂前的S节点进行比较,因此分裂收益的表达式为:
G
a
i
n
=
1
2
[
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
−
(
G
L
+
G
R
)
2
H
L
+
H
R
+
λ
]
−
γ
Gain= \frac{1}{2}\Big[\frac{G_L^2}{H_L+\lambda} + \frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\Big] - \gamma
Gain=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
假设枚举年龄特征 x j x_j xj,考虑划分点 a a a,计算枚举 x j < a x_j \lt a xj<a 和 x j ≥ a x_j \ge a xj≥a的导数和:

对于一个特征,对特征取值排完序后,枚举所有的分裂点 a a a, 只要从左到右so面就可以枚举出所有分割的梯度 G L G_L GL 和 G R G_R GR,计算增益。假设树的高度为 H H H,特征数为 d d d,则复杂度为 O ( H d n l o g n ) O(Hdnlogn) O(Hdnlogn)。其中排序为 O ( n l o g n ) O(nlogn) O(nlogn),每个特征都要排序乘以 d d d,每一层都要重复一遍操作,故要乘以高度 H H H。
3.2 近似算法
当数据量过大时,贪婪算法就不好用,因为要遍历每个分割点, 甚至内存都放不下, XGBoost总结了一个近似框架
-
近似算法的做法:
- 根据特征分布的百分位数提出可能的候选分裂点
- 将连续特征值映射到候选分割点分割出的箱子中
- 计算出每个箱子中数据的统计量,根据统计量找到最佳的分割点
-
全局选择vs局部选择
- 全局选择:建树之前求出所有特征可能的分裂点
- 局部选择:在每次split之后求解特征的分裂点
- 全局选择步骤少,但是需要足够的分裂点,因为每次split不更新分裂点

展开来看,特征分位数的选取还有 global 和 local 两种可选策略:
- global 在全体样本上的特征值中选取,在根节点分裂之前进行一次即可;
- local 则是在待分裂节点包含的样本特征值上选取,每个节点分裂前都要进行。
这两种情况里,由于global只能划分一次,其划分粒度需要更细
上面就是等频和等宽分桶的思路了 ,但是存在一个问题: 这样划分没有啥依据,缺乏可解释性
作者这里采用了一种对loss的影响权重的等值percentiles(百分比分位数)划分算法(Weight Quantile Sketch)。
3.3 加权分位数
近似算法中很重要的一步是列出候选的分割点。通常特征的百分位数作为候选分割点的分布会比较均匀。作者进行候选点选取的时候,考虑的是想让loss在左右子树上分布的均匀一些,而不是样本数量的均匀,因为每个样本对降低loss的贡献可能不一样,按样本均分会导致分开之后左子树和右子树loss分布不均匀,取到的分位点会有偏差。
可以把公式(6)重写为:
∑
i
=
1
n
1
2
h
i
(
f
t
(
x
i
)
+
g
i
h
i
)
2
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
\sum^n_{i=1} \frac{1}{2}h_i(f_t(\bold x_i) + \frac{g_i}{h_i})^2+ \Omega(f_t)+constant
i=1∑n21hi(ft(xi)+higi)2+Ω(ft)+constant
第一个就是 h i h_i hi是啥?它为啥就能代表样本对降低loss的贡献程度?
h i h_i hi 上面已经说过了,损失函数在样本处的二阶导数啊!
O b j ( t ) ≈ ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + ∑ i = 1 t Ω ( f i ) Obj^{(t)} \approx \sum^n_{i=1}\Big[g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)\Big]+\sum^t_{i=1} \Omega(f_i) Obj(t)≈i=1∑n[gift(xi)+21hift2(xi)]+i=1∑tΩ(fi)
为啥它就能代表第 i i i个样本的权值啊?
L ( t ) ≃ ∑ i = 1 n [ l ( y i , y ^ i ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) = ∑ i = 1 n [ 1 2 h i ⋅ 2 ⋅ g i f t ( x i ) h i + 1 2 h i ⋅ f t 2 ( x i ) ] + Ω ( f t ) = ∑ i = 1 n 1 2 h i [ 2 ⋅ g i h i ⋅ f t ( x i ) + f t 2 ( x i ) ] + Ω ( f t ) = ∑ i = 1 n 1 2 h i [ ( 2 ⋅ g i h i ⋅ f t ( x i ) + f t 2 ( x i ) + ( g i h i ) 2 ) − ( g i h i ) 2 ] + Ω ( f t ) = ∑ i = 1 n 1 2 h i [ ( f t ( x i ) + g i h i ) 2 ] + Ω ( f t ) + C o n s t a n t = ∑ i = 1 n 1 2 h i [ ( f t ( x i ) − ( − g i h i ) ) 2 ] + Ω ( f t ) + C o n s t a n t \begin{aligned} L^{(t)} & \simeq \sum^n_{i=1}\Big [l(y_i, \hat y_i^{(t-1)}) + g_if_t(\bold x_i) + \frac{1}{2}h_if^2_t(x_i)\Big]+ \Omega(f_t)\\ &=\sum^n_{i=1}\Big[\frac{1}{2}h_i·\frac{2·g_if_t(\bold x_i)}{h_i}+\frac{1}{2}h_i·f^2_t(x_i)\Big]+ \Omega(f_t)\\ &=\sum^n_{i=1}\frac{1}{2}h_i\Big[2·\frac{g_i}{h_i}·f_t(\bold x_i)+f^2_t(x_i)\Big]+ \Omega(f_t)\\ &=\sum^n_{i=1}\frac{1}{2}h_i\Big[\Big(2·\frac{g_i}{h_i}·f_t(\bold x_i)+f^2_t(x_i)+(\frac{g_i}{h_i})^2\Big)-\Big(\frac{g_i}{h_i}\Big)^2\Big]+ \Omega(f_t)\\ &=\sum^n_{i=1}\frac{1}{2}h_i\Big[\Big(f_t(\bold x_i)+\frac{g_i}{h_i}\Big)^2\Big]+\Omega(f_t)+Constant\\ &=\sum^n_{i=1}\frac{1}{2}h_i\Big[\Big(f_t(\bold x_i)-\big(-\frac{g_i}{h_i}\big)\Big)^2\Big]+\Omega(f_t)+Constant \end{aligned} L(t)≃i=1∑n[l(yi,y^i(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)=i=1∑n[21hi⋅hi2⋅gift(xi)+21hi⋅ft2(xi)]+Ω(ft)=i=1∑n21hi[2⋅higi⋅ft(xi)+ft2(xi)]+Ω(ft)=i=1∑n21hi[(2⋅higi⋅ft(xi)+ft2(xi)+(higi)2)−(higi)2]+Ω(ft)=i=1∑n21hi[(ft(xi)+higi)2]+Ω(ft)+Constant=i=1∑n21hi[(ft(xi)−(−higi))2]+Ω(ft)+Constant
后面的每一个分类器都是在拟合每个样本的一个残差 − g i h i -\frac{g_i}{h_i} −higi, 其实把上面化简的平方损失函数拿过来就一目了然了。而前面的 h i h_i hi可以看做计算残差时某个样本的重要性,即每个样本对降低loss的贡献程度。
第二个问题就是这个bin是怎么分的,为啥是0.6一个箱?
定义一个数据集 D k = ( x 1 k , h 1 ) , ( x 2 k , h 2 ) . . . ( x n k , h n ) D_k={(x_{1k},h_1),(x_{2k},h_2)...(x_{nk},h_n)} Dk=(x1k,h1),(x2k,h2)...(xnk,hn) ,示样本的第 k k k 个特征的取值和其二阶梯度统计量。 可以定义一个排序方程 r k : R → [ 0 , + ∞ ) r_k: \mathbb{R}→[0,+∞) rk:R→[0,+∞):
r k ( z ) = 1 ∑ ( x , h ) ∈ D k h ∑ ( x , h ) ∈ D k , x < z h r_k(z)=\frac{1}{\sum_{(x,h)\in D_k}h} \sum_{(x,h)\in D_k, x<z}h rk(z)=∑(x,h)∈Dkh1(x,h)∈Dk,x<z∑h
这里 z z z的代表特征值小于 z z z的那些样本。这个排名函数表示特征值小于 z z z的样本的贡献度比例。假设 , z z z是第一个候选点 ,那么 r k ( z ) = 1 3 r_k(z)=\frac{1}{3} rk(z)=31,目标是找到相对准确候选的分割节点 { s k 1 , s k 2 , ⋯ s k l } \{s_{k1},s_{k2},⋯s_{kl}\} {sk1,sk2,⋯skl},此处的 s k 1 = m i n i x i k , s k l = m a x i x i k s_{k1}=\underset {i}{min}\bold x_{ik}, s_{kl}=\underset {i}{max}\bold x_{ik} sk1=iminxik,skl=imaxxik,且 相邻两个桶之间样本贡献度的差距应满足下面这个函数:
∣ r k ( s k , j ) − r k ( s k , j + 1 ) ∣ < ϵ , s k 1 = m i n i x i k , s k l = m a x i x i k \left| r_k(s_{k,j})-r_k(s_{k,j+1})\right|< \epsilon, s_{k1}=\underset {i}{min}\bold x_{ik}, s_{kl}=\underset {i}{max}\bold x_{ik} ∣rk(sk,j)−rk(sk,j+1)∣<ϵ,sk1=iminxik,skl=imaxxik
ϵ \epsilon ϵ 控制每个桶中样本贡献度比例的大小 , 其实就是贡献度的分位点。 比如在上面图中我们设置了 ϵ = 1 3 \epsilon=\frac{1}{3} ϵ=31, 这意味着每个桶样本贡献度的比例是 1 3 \frac{1}{3} 31(贡献度的 1 3 \frac{1}{3} 31 分位点), 而所有的样本贡献度总和是 1.8 1.8 1.8, 那么每个箱贡献度是 0.6 0.6 0.6 ( 1.8 ∗ ϵ 1.8*\epsilon 1.8∗ϵ),分为 3 3 3( 1 ϵ \frac{1}{\epsilon} ϵ1)个箱, 上面这些公式看起来挺复杂,可以计算起来很简单,就是计算一下总的贡献度, 然后指定 ϵ \epsilon ϵ, 两者相乘得到每个桶的贡献度进行分桶即可。这样我们就可以确定合理的候选切分点,然后进行分箱了 。
3.4 列采样与学习率
XGBoost为了进一步优化效果,在以下2个方面进行了进一步设计:
-
列采样(按层随机与按树随机)
- 和随机森林做法一致,每次节点分裂并不是用全部特征作为候选集,而是一个子集。
- 这么做能更好地控制过拟合,还能减少计算开销。
- 按层随机:在每次分裂一个结点时,对同一层内的每个结点分裂之前,随机选择一部分特征,此时只需要遍历一部分特征,来确定最后分割点。
- 按树随机:在建树之前就随机选择特征,之后所有的叶子结点均只使用这部分特征。
-
学习率
- 也叫步长、shrinkage,具体的操作是在每个子模型前(即每个叶节点的回归值上)乘上该系数,不让单颗树太激进地拟合,留有一定空间,使迭代更稳定。XGBoost默认设定为 0.3 0.3 0.3。
3.5 特征缺失与稀疏性
XGBoost模型的一个优点就是允许特征存在缺失值。对缺失值的处理方式如下:
-
在特征k上寻找最佳 split point 时,不会对该列特征 missing 的样本进行遍历,而只对该列特征值为 non-missing 的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找 split point 的时间开销。
-
在逻辑实现上,为了保证完备性,会将该特征值missing的样本分别分配到左叶子结点和右叶子结点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。
-
训练阶段:
在训练过程中,如果特征 f 0 f_0 f0出现了缺失值,处理步骤如下:
-
首先对于 f 0 f_0 f0非缺失的数据,计算出 L s p l i t L_{split} Lsplit 并比较大小,选出最大的 L s p l i t L_{split} Lsplit,确定其为分裂节点(即选取某个特征的某个阈值);
-
然后对于** f 0 f_0 f0缺失的数据**,将缺失值分别划分到左子树和右子树,分别计算出左子树和右子树的 L s p l i t L_{split} Lsplit,选出更大的 L s p l i t L_{split} Lsplit,将该方向作为缺失值的分裂方向(记录下来,预测阶段将会使用)。
L s p l i t = 1 2 [ ( ∑ i ∈ I L g i ) 2 ∑ i ∈ I L h i + λ + ( ∑ i ∈ I R g i ) 2 ∑ i ∈ I R h i + λ − ( ∑ i ∈ I I g i ) 2 ∑ i ∈ I I h i + λ ] − γ L_{split}= \frac{1}{2}\Big[\frac{(\sum_{i\in I_L} gi)^2}{\sum_{i\in I_L}h_i+\lambda} + \frac{(\sum_{i\in I_R} gi)^2}{\sum_{i\in I_R}h_i+\lambda}-\frac{(\sum_{i\in I_I} gi)^2}{\sum_{i\in I_I}h_i+\lambda}\Big] - \gamma Lsplit=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈IIhi+λ(∑i∈IIgi)2]−γ
-
-
预测阶段:
在预测阶段,如果特征 f 0 f_0 f0出现了缺失值,则可以分为以下两种情况:
- 如果训练过程中, f 0 f_0 f0出现过缺失值,则按照训练过程中缺失值划分的方向(left or right),进行划分;
- 如果训练过程中, f 0 f_0 f0没有出现过缺失值,将缺失值的划分到默认方向(左子树)。
4.工程优化
4.1 并行列块设计
在建树的过程中,最耗时的部分是寻找最优的切分点,而在这个过程中,最耗时的部分是将数据排序。为了减少排序时间,提出了Block结构存储数据。
XGBoost 将每一列特征提前进行排序,以块(Block)的形式储存在缓存中,并以索引将特征值和梯度统计量对应起来,每次节点分裂时会重复调用排好序的块。而且不同特征会分布在独立的块中,因此可以进行分布式或多线程的计算。

- Block中的数据以稀疏格式 CSC 进行存储。
- Block中的特征进行排序(不对缺失值排序)。
- Block中特征还需要存储指向样本的索引,这样才能根据特征的值来取梯度。
- 一个Block中存储一个或者多个特征值。
4.2 缓存访问优化
特征值排序后通过索引来取梯度 g i g_i gi, h i h_i hi 会导致访问的内存空间不一致(梯度信息是根据特征值排序存储的),进而降低缓存的命中率,影响算法效率。

为解决这个问题,在精确贪心算法中,XGBoost为每个线程分配一个单独的连续缓存区(buffer),用来存放梯度信息(非连续–>连续),然后计算梯度信息。在近似算法中,对 Block 的大小进行合理的设置。定义 Block 的大小为 Block 中最多的样本数。设置合适的大小是很重要的,设置过大容易导致命中率过低,过小容易导致并行化效率不高。文章来源:https://www.toymoban.com/news/detail-714228.html
4.3 核外块计算
数据量非常大的情形下,无法同时全部载入内存。XGBoost 将数据分为多个 blocks 储存在硬盘中,使用一个独立的线程专门从磁盘中读取数据到内存中,实现计算和读取数据的同时进行。
为了进一步提高磁盘读取数据性能,XGBoost 还使用了两种方法:文章来源地址https://www.toymoban.com/news/detail-714228.html
- 压缩 block,用解压缩的开销换取磁盘读取的开销。
- 将 block 分散储存在多个磁盘中,提高磁盘吞吐量。
5.XGBoost vs GBDT
- GBDT 是机器学习算法,XGBoost 在算法基础上还有一些工程实现方面的优化。
- GBDT 使用的是损失函数一阶导数,相当于函数空间中的梯度下降;XGBoost 还使用了损失函数二阶导数,相当于函数空间中的牛顿法。
- 正则化:XGBoost 显式地加入了正则项来控制模型的复杂度,能有效防止过拟合。
- 列采样:XGBoost 采用了随机森林中的做法,每次节点分裂前进行列随机采样。
- 缺失值:XGBoost 运用稀疏感知策略处理缺失值,GBDT无缺失值处理策略。
- 并行高效:XGBoost 的列块设计能有效支持并行运算,效率更优。
6.总结
- XGBoost是一种基于boosting增强策略的加法模型,训练时使用前项分布算法贪婪地学习一棵 cart树拟合前 t − 1 t-1 t−1 棵树的预测值与真实值之间的残差。使用二阶泰勒展开,目标函数加入正则化项、支持并行以及默认缺失值处理等优化。
- XGBoost的核心原理:如何构建目标函数–>如何优化目标函数–>如何引入树结构到目标函数?–>如何找到最优的树结构?
- XGBoost 的分裂查找算法:
- 基本的贪心算法:先将特征值进行排序, 枚举出了所有特征上的所有可能的分裂节点,按顺序访问数据
- 近似算法:解决数据量巨大时贪婪算法失效的问题。提出可能的候选分裂点(百分位数)–连续值映射到bin中–统计bin中的样本数量–筛选出最佳分裂点(分裂点给出时机:全局与局部)
- 加权分位数: 通常特征的百分位数作为候选分割点的分布会比较均匀(理解)。(不同样本对loss的降低贡献的程度不同)
-
稀疏性感知分裂查找: 稀疏感知算法处理缺失值,当特征值缺失时, 样本会被分类为默认方向。 最优的默认方向是从数据中学习出来
心原理:如何构建目标函数–>如何优化目标函数–>如何引入树结构到目标函数?–>如何找到最优的树结构?
到了这里,关于XGBoost模型详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!