数据结构介绍
- 什么是数据结构?
- 什么是算法?
- 数据结构和算法的重要性
数据结构定义
数据结构是计算机科学中研究数据组织、存储和管理的一门学科。数据结构描述了数据对象之间的关系,以及对数据对象进行操作的方法和规则。
常见的数据结构
数组(Array):连续存储相同类型的数据元素。 链表(Linked
List):通过指针链接的节点组成,每个节点包含数据和指向下一个节点的指针。 栈(Stack):遵循后进先出(LIFO)原则的数据结构。
队列(Queue):遵循先进先出(FIFO)原则的数据结构。 树(Tree):由节点和边组成的层次结构,如二叉树、二叉搜索树等。
图(Graph):由节点和边组成的非线性数据结构,用于表示对象之间的关系。 哈希表(Hash
Table):使用哈希函数将键映射到存储位置的数据结构。 堆(Heap):特殊的树形数据结构,具有优先级队列的特性。
集合(Set):存储唯一元素的无序集合。 字典(Dictionary):存储键-值对的数据结构,也被称为映射或关联数组。
每种数据结构都有其特定的用途和适用场景。选择合适的数据结构可以提高算法的效率和性能。在实际应用中,通常会根据问题的需求选择合适的数据结构进行数据的组织和管理。
算法定义
算法是一组解决问题步骤的有限序列,它是为解决一个或多个计算问题而设计的明确指令集。简单来说,算法就是解决问题的方法和步骤。
算法由若干基本操作组成,包括数学运算、比较、赋值、条件分支和循环等,可以用自然语言、流程图、伪代码或编程语言来描述。
算法的设计和分析是计算机科学中的重要问题。有效的算法可以使问题的解决更为高效、精确和可靠。算法的时间复杂度和空间复杂度是评估算法效率和性能的主要指标,通常使用大 O 表示法来表示。
除了计算、搜索、排序和存储等常见的算法领域,还有许多其他领域,如人工智能、机器学习、图像处理和自然语言处理等,都使用了不同类型的算法来解决不同类型的问题。
总之,算法是计算机科学中不可或缺的组成部分,它们已经在各行各业中得到了广泛的应用。
算法特性
算法的特性包括以下几个方面:
有限性:任何一个算法都必须在有限的时间内停止。也就是说,算法的执行时间必须是有限的,否则算法就不能被执行。
确定性:算法的每个步骤必须被精确定义。也就是说,给定一个输入,程序每一次运行的结果是一样的。
可行性:算法必须可以在计算机或其他计算设备上实现。也就是说,算法中用到的所有操作都可以被计算机执行。
输入:算法必须有零个或多个输入,这些输入是要为问题提供解决方案的数据。
输出:算法必须有一个或多个输出,这些输出是算法为解决问题创建的解决方案。
可读性:算法必须易于理解和实现,可读性是评估算法质量的重要标准之一。
高效性:算法的执行结果必须是准确的,同时也要在可接受的时间内获得结果。算法的时间复杂度和空间复杂度通常用于评估算法的效率。
总之,算法是计算机科学中非常重要的概念和实践,对于计算机科学专业的学生和从事计算机编程工作的人员来说,掌握算法的设计和分析是非常必要的。
数据结构的重要性
数据结构和算法是计算机科学中最基础和最重要的两个领域。它们的作用体现在以下几个方面:
提高程序效率和性能:数据结构和算法可以有效地提高程序的效率和性能,使程序更加快速、可靠和节省资源。对于大量处理数据和计算密集型任务的程序,优秀的数据结构和算法非常重要。
最优解决方案:数据结构和算法是解决计算机科学中一系列问题的关键工具,例如搜索、排序、图形处理、人工智能和机器学习等各个领域。通过使用最优算法和数据结构,可以得到最优解决方案,从而提高计算机程序的效率和准确性。
简化复杂问题:许多计算机科学问题都是很复杂的,但是如果正确地应用数据结构和算法,可以使这些复杂问题变得更加简单。通过抽象和组织问题,使用正确的算法和数据结构,可以将问题简化为较小的子问题,从而更容易地解决问题。
促进创新:数据结构和算法的不断发展推动了计算机科学领域的创新,为各种领域提供了新的技术和工具。例如,人工智能、机器学习和大数据等领域的发展都离不开优秀的数据结构和算法的支持。
增强竞争力:掌握数据结构和算法对于计算机科学专业的学生和从事编程工作的人员来说非常重要,这是增强个人竞争力和就业竞争力的基础。人才市场对于掌握数据结构和算法方面的专业人才的需求量日益增大。
因此,学习和掌握数据结构和算法,对于计算机科学相关领域的学生和从业人员来说都非常重要,这是进入计算机行业、提高个人技能水平的基础。
时间复杂度
1.算法效率
2.时间复杂度
算法效率
如何衡量一个算法的好坏呢?
比如对于以下斐波那契数列:
long long Fib(int N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
我们可以知道这样用递归的方式实现斐波那契数列十分的简单,但是一旦数值稍微大了起来,就会因为递归开辟了许多函数空间,超过某一定值就会导致栈区溢出,对于该代码函数的实现和释放其实十分像古代帝位传承(嫡长子继承制)。
上面可以抽象成以递归方式实现的斐波那契数列,作者个人觉得还是十分像古代帝位的传承
斐波那契数列的递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?
算法的复杂度
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
时间复杂度
时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
// 请计算一下Func1中++count语句总共执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
可以很简单的知道fun1中++count被执行了:n^2+2*n+10次。
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们使用大O的渐进表示法。
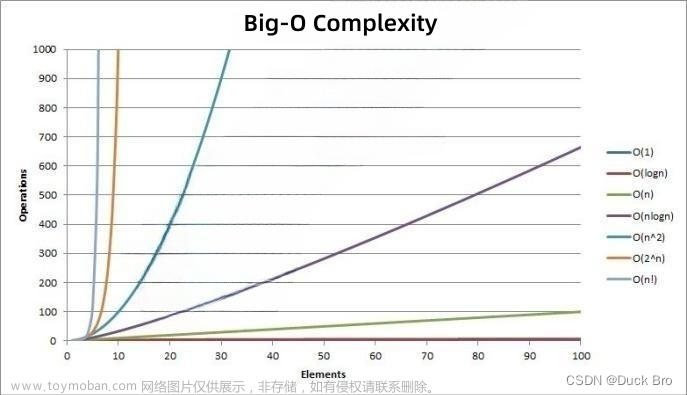
大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
使用大O的渐进表示法以后,Func1的时间复杂度为:
N = 10 F(N) = 100
N = 100 F(N) = 10000
N = 1000 F(N) = 1000000
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况: 任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)。
所以,Func1的时间复杂度为:O(n^2)。
空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。文章来源:https://www.toymoban.com/news/detail-714383.html
常见复杂度表


本篇内容到此为止,带大家简单认识了数据结构以及数据结构中时间、空间复杂度的理解,谢谢大家。文章来源地址https://www.toymoban.com/news/detail-714383.html
到了这里,关于数据结构介绍与时间、空间复杂度的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!