各位同学们好,我们之前已经发布了第一问的思路视频,然后我们现在会详细的进行代码和结果的一个讲解,然后同时我们之后还会录制其他小问更详细的思路以及代码的手把手教学。
大家我们先看一下代码这一部分,我们采用的软件是Jupyter,大家可以下载Anaconda,然后选择 Jupyter 进行一个我们代码的运行。之所以选用这个软件是因为可以更好展示我们的图表,然后大家也可以看得更直观一点。如果这些库发现安装的有问题的话,可以自己输入 conda install 什么什么库或者 pip install 什么什么库,然后第一问需要我们使用的数据是表 1 到表4,我们先把这个表格进行一个读取,就是用 PD.read_Excel 进行一个读取,这个是相对路径,大家只要把数据包和代码放在一个文件夹下面就可以了。
问题一 :使用附件 1-4 中的数据 ,预测出各商家在各仓库的商品 2023-05- 16 至 2023-05-30 的需求量,请将预测结果填写在结果表 1 并上传竞赛平台,并对你们模型的预测性能进行评价。另外请讨论:根据数据 分析及建模过程,这些由商家、仓库、商品形成的时间序列如何分类,使同一类别在需求上的特征最为相似? 思路:
首先我们讲第一问,首先问题一需要我们同时使,就是使用附件 1- 4 的数据进行一个需求量的预测,然后预测之后进行一个性能的评价,同时考察如何使这些类别在需求的特征上最为相似。
我们首先来观察一下数据形式,就首先这是表格一,然后表格依靠的是 product name, product number 来和表 2 相连,同时表一依靠 seller number 和表 3 相连,然后通过 Warehouse number 来跟表 4 来相连。然后我们想要把表 1234 进行一个合并,我们想要把表 1234 进行一个相连,合成一个大表。然后最直观想到的就是用 Python 中的 PD merge 这个函数,那我们后续会在代码中进行展现,然后展示给大家,然后你合并完之后,这个表格就变成一个这样子的大表,这里就是我们要预测的标签,然后剩下的是它的特征,然后处理完数据之后我进行一个预测。
第一步就是合并表,然后是预处理,首先你观察数据有没有为零或者是明显错误的值,然后你再进行一个相关性的分析,就是用,这个函数来观察一下它的相关性,然后输出相关性高的作为特征来进行后续的一个预测的函数。如果我们主要是考察这是一个时间上的一个预测,然后可以采用有典型的时序预测的 Arima 或者是用 LSTM 这样子的。当然最简单的就是线性回归这种句都是可以采取的。然后性能界限提一个评价,我们可以输出预测的那个结果图和实际的增值的一个两个图线的一个图片,或者是输出我们的那个精确度,然后这一问它是好,就是问我们如何分类,可以使用它们作为相似分类。
和前对基本使用聚类分析,那当然后续更详细的一个介绍,我们会根据代码,然后还有结果图标来跟大家介绍,okay,我们就先详细的分析到一个问题一,然后问题 2 和问题 3 我们后续会进行展开,然后欢迎大家点点关注,我们会持续分享的。
我们把表 2 也输入,表 3 也进行一个输入,然后表 4 输入进去之后,我们需要将表进行一个合并,我们可以发现表一和表 2 通过 product 的 number 进行一个合并,然后表一和表 3 是 sale number,表一和表 4 是 warehouse number,我们直接采用这个关键字段,然后调通过调取 Python 中的 PD.merge 这个包就可以直接进行合并。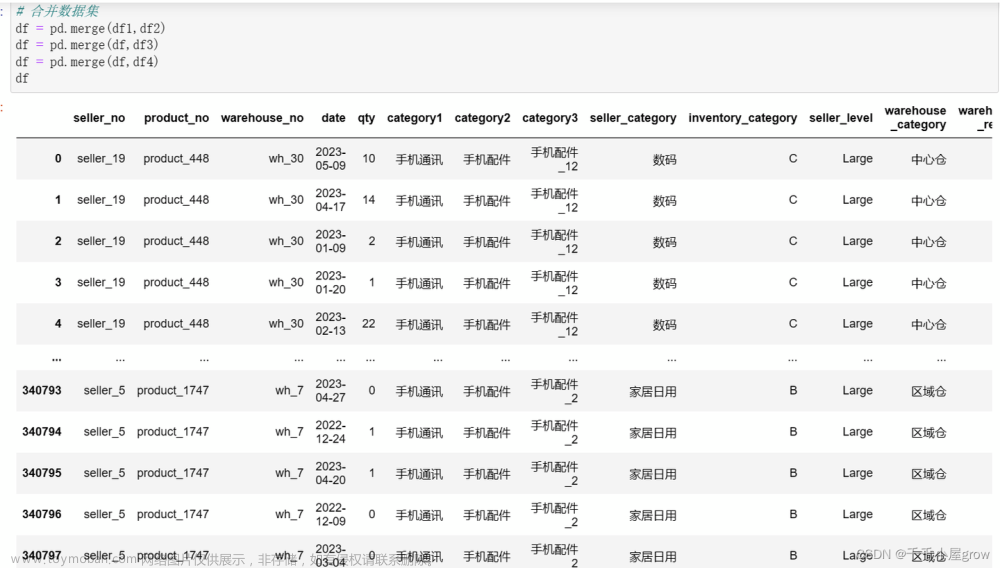

可以看一下我们合并或者大表是这个样子的,四个表的特征完全已经在一个表里了。好的,我们接下来输出一下各个列名的数据类型,还有它们的数量是这个图,但是这个数字我们还需要进行一个预处理,因为它有一些,比如像这个东西,它是文本型数据,不能进行后续特征的一个输入,我们要把这些全部的文本数据,还有这个手机通讯、手续配件这种类别全部转化为数值,所以就调用了这个建立列表,构建一个字典,然后将这些特征全部转化为了,这就是右边的一列,就是左边那一列是我们调取的值,然后右边是我们转化后的值。
当之后下面也是统领用 replace 的方法来替换这些值,那可以看到我们替换之后的结果都已经给到了大家,当然大家也可以直接用 one hot 这个函数,或者是就是直接特征转化这个函数,把这些类别转化为123456,这个,这个你可以搜一下自己去解决。然后实在不行的话也可以用我们给到大家这个东西,然后我们结果图表也会给到大家。

接下来我们处理好数据之后,就进行一个相关性的分析,这个是数相关性分析的一个数值,然后相关性分析的结果图是这个样子的,看到这些地方是颜色比较深的,然后我们分析完之后,接下来你可以通过相关性筛选一些特征,也可以不筛选保留所有的特征,进行一个后续的模型输入。

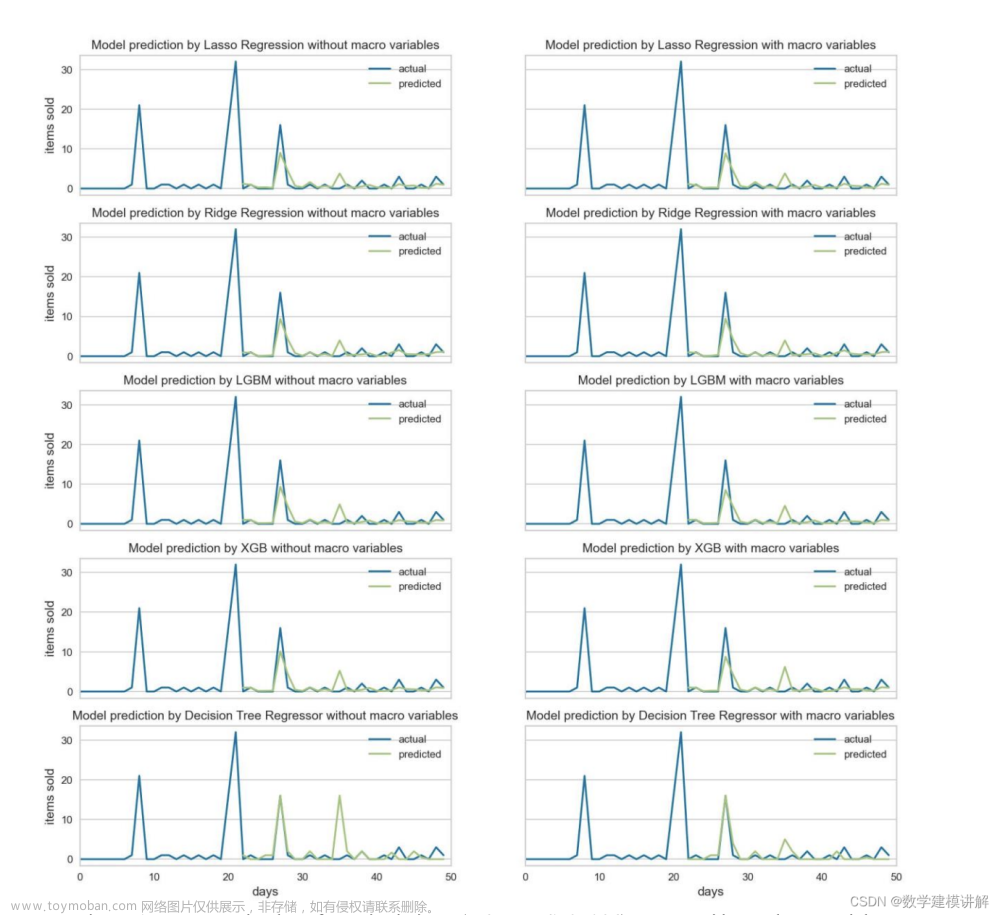
在我们处理好数据,然后分析好模型之后,就是分析好这个相关性之后,我们就需要输入到模型里进行一个计算,然后模型经典的时序模型就是 Arima 模型,我们也进行了一个跑,就是给大家看一下儿曼的效果,然后发现它效果其实并不是特别好,原因在哪里?因为大家可以看一下这个二维码数据,是单纯的根据时间和每个时间对应的需求来进行一个后续十几天的预测。我们觉得这个样子做效果不好,一个是因为它直接是用一步来预测未来的 15 步,这个样子是有问题的。然后第二个是因为在后面这段时间里,他我们用了预测数据,基本上数值都非常小,就是0,然后这也造成了一个问题,所以我们后来会去进行模型进行一个调整。
同时还采用了其他的模型,比如LSTM,我们 LSTM 是构建了就是用调取 Tensorflow 的keras 包,然后来进行一个训练,然后训练后的结果我们也会给到大家,然后接下来就是下一个视频,然后我们就是边做然后边给大家分析,希望大家持续关注。文章来源:https://www.toymoban.com/news/detail-714445.html
问题二:现有一些新出现的商家+仓库+ 商品维度(附件 5),导致这种 情况出现的原因可能是新上市的商品,或是改变了某些商品所存放的仓库。 请讨论这些新出现的预测维度如何通过历史附件 1 中的数据进行参考,找 到相似序列并完成这些维度在 2023-05- 16 至 2023-05-30 的预测值。请把预测结果填写在结果表 2 ,并上传至竞赛平台。
思路:
问题二要求讨论如何处理新出现的商家、仓库、商品维度,以实现精准预测。对于新出现的商家、仓库、商品维度,可以通过附件中的数据进行参考,找到相似序列并完成这些维度的预测值。具体来说,可以采用基于相似度的算法,如KNN算法、聚类算法等,对历史数据进行分析和处理,找出与新出现维度相似的历史数据,从而预测未来的需求量。
问题三:每年 6 月会出现规律性的大型促销,为需求量的精准预测以 及履约带来了很大的挑战。附件 6 给出了附件 1 对应的商家+仓库+ 商品维 度在去年双十一期间的需求量数据,请参考这些数据,给出 2023-06-01 2023-06-20 的预测值。请把预测结果填写在结果表 3 ,并上传至竞赛平台。
思路:
问题三要求根据历史数据,预测每年6月份的需求量。在实际的电商供应链预测任务中,每年6月份会出现规律性的大型促销,为需求量的精准预测以及履约带来了很大的挑战。 问题三中给出了附件6,该附件给出了附件1对应的商家+仓库+商品维度在去年双十一期间的需求量数据。可以根据这些历史数据,采用时间序列分析、回归分析、神经网络等算法,预测2023年6月1日至6月20日的需求量。
本次将全程提供B题题完整解题思路、代码和完整文字,同时共享一些论文模板等资料,需要的小伙伴可以关注一下,持续更新!完整解题代码可点击此处获取文章来源地址https://www.toymoban.com/news/detail-714445.html
#https://
#mbd.pub/o/bread/mbd-ZZWalpty
到了这里,关于【代码思路】2023mathorcup 大数据数学建模B题 电商零售商家需求预测及库存优化问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!