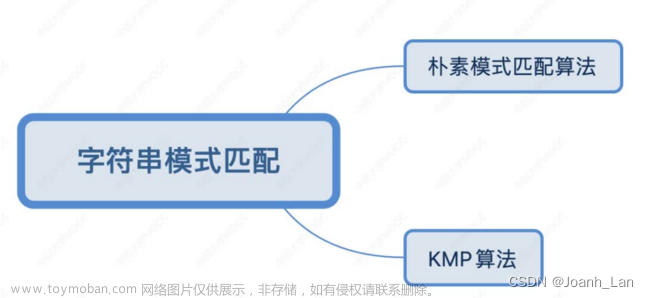
目录
前言
1.串的定义
相关类型
2.串的储存结构
顺序储存表示
堆分配储存表示
块链储存表示
3.串的操作方式
4.串的匹配算法
(1)BF算法
过程原理
代码实现(C/C++)
算法分析
(2)KMP算法
过程原理
匹配过程:
获取next数组:
代码实现(C/C++)
算法分析
前言
前面我们学习了顺序表和线性表,这两种数据结构的储存数据域可以是一个任意类型,比如:整形、字符串类型、含有多种类型的结构体等等……那今天我们学习新的数据结构--串,其数据域的类型只能是字符类型,下面就一起来看看吧!
1.串的定义
- 串是由零个或多个字符数组组成的有限序列。
- 串中字符的个数称为串的长度,含有零个元素的叫空串。
- 串是限定了元素为字符的线性表
(注:串与一般的线性表操作有很大区别,线性表主要针对表内的某个元素,而串操作主要针对子串)
相关类型
- 串:0个或多个字符组成的有限序列。S=′a1a2...an′(n>=0)。
- 串的长度:串中字符的个数
- 空串:长度为0的串
- 空格串:0个或多个空格字符组成的串
- 子串:串中任意连续字符组成的子序列
- 主串:包含子串的串
- 位置:字符在串中的序号。ps:子串在主串中的位置是其第一个字符在主串中的位置。
- 串的相等:长度和对应位置字符都相等
2.串的储存结构
顺序储存表示
顺序储存结构是通过用一个连续地址的区域去储存字符数据,实际上就是数组的形式去储存。顺序储存方式必须去规定好最大储存值,储存的数量不能超过规定的最大值,超过的部分就要被舍去。顺序储存结构如下所示:
#define Maxsize 256//定义最大容量
//顺序储存
typedef struct string {
char ch[Maxsize];//储存字符串
int length; //当前串的长度
}String;堆分配储存表示
堆分配储存方式是通过空间的动态分配内存来去储存数据的,然后通过指针域把堆里面分配好的不连续空间给链接到一起,形成链表。虽然是动态分配可以根据实际情况去分配容量,但是由于指针域占用4个字节的空间,然而数据域仅仅只占用1个字节空间,这就会有点浪费空间,所以很多时候我们会去用顺序储存方式来去实现一个串。堆分配储存结构如下所示:
typedef struct string {
char ch; //数据域
struct string* next;//指针域
}String;块链储存表示
块链的储存结构是对堆分配储存方式的改进,就是提高了数据域的空间占用比,提高空间的利用率,一个节点可以去存放多个字符,如下所示:

3.串的操作方式
以下就是对字符串的操作方法,跟我们前面所学的顺序表和链表的操作方法基本上没有太大区别,这里我就不去一一详细讲了,有兴趣的小伙伴可以去自己把代码写完整实现这些功能。
StrAssign(&T, chars);// 赋值操作。把串T赋值为 chars
Strcopy(&T, S);// 复制操作。把串S复制得到串T。
StrEmpty(S);// 判空操作。若S为空串, 则返回TRUE, 否则返回 FALSE
Replace(&S, T, V);//串的替换操作,把T替换为V
StrCompare(S, T);// 串比较操作。若S > T, 则返回值 > 0; 若S = T, 则返回值 = 0; 若S < T, 则返回值 < 0。
StrEngth(S);// 求串长。返回串S的元素个数
Substring(&Sub, S, pos, 1en);// 求子串。用Sub返回串S的第pos个字符起长度为len的子串。
Concat(&T, S1, S2);// 串联接。用T返回由S1和S2联接而成的新串。
StrInsert(&S, pos, T);//串的插入操作。把T插入到S的pos位置上
Index(S, T);// 子串的定位操作。若主串S中存在与串T值相同的子串, 则返回它在主串S中第一次出现的位置; 否则函数值为0
Clearstring(&S);// 清空操作。将S清为空串
Destroystring(&S);// 销毁串。将串S销毁
下面我要重点讲的是字符串的查找匹配,也就是在一个主串中匹配里面是否有满足条件的子串,下面就来看看吧!
4.串的匹配算法
(1)BF算法
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法
过程原理

代码实现(C/C++)
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#define Maxsize 256
//顺序储存
typedef struct string {
char ch[Maxsize];//储存字符串
int length; //当前串的长度
}String;
//01---串的模式匹配算法 暴力查找法
int Index_BF(String* S, String* T) {
assert(S);
assert(T);
int i = 0, j = 0;
while (i < S->length && j < T->length) {
if (S->ch[i] == S->ch[i]) //当匹配到相同的时候
{
i++; //主串和模式串的指针指向 依次+1
j++;
}
else
{
i = i - j + 1;//主串回溯到后面一个字符
j = 0; //模式串回溯到第一个字符
}
}
if (j == T->length)
return i-j+2; //返回匹配成功主串的位置
return -1;
}算法分析
可以看出BF算法确实很暴力,一个一个去一一匹配,直到成功为止,所以时间复杂度为O(mn),m是主串的长度,n是模式串的长度
(2)KMP算法
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。
过程原理
KMP算法可以很大限度减少匹配的次数,也就是说主串不需要去执行回溯的操作,从而提高匹配的效率,但是KMP算法还是有点难去理解的,需要用到一个next数组(可能失配位置),下面我会去详细说明的。
匹配过程:
假设
主串: a b c d a b e a b c d a b
模式串:a b c d a b d
第一次匹配
a b c d a b e a b c d a b d
a b c d a b d
很明显第六个(d和e)出现了不同,在此之前前面出现相同的字符最大个数是2(分别是a、b)。
第二次匹配
前面我们知道模式串出现相同字符最大个数为2,此时直接把子串相同字符的位置移动到以下位置:
a b c d a b e a b c d a b d
a b c d a b d
这里我们可以发现主串跟模式串中的第三个字符不相匹配,所以此时要把模式串的第一个位置与 e 进行比较
第三次匹配
a b c d a b e a b c d a b d
a b c d a b d
很显然此时模式串的第一个字符与主串不匹配,所以需要将主串的比较位置往后移动一位,模式串也是一样往后移动一位,再次比较
第四次匹配
a b c d a b e a b c d a b d
a b c d a b d
此时匹配成功,返回主串匹配成功第一个字符的位置(主串中 a 的位置
获取next数组:
对于模式串: a b c d a b d
1.首位字符 a 前面是没有字符的,故没有前缀也没有后缀,那么其next数组值为-1,即next[ 0 ]=-1
2.对于第二个字符b 其前面的前缀和后缀都是字符a都是同一个,所以不能表示前缀与后缀相等,故其next数组值为0,即next[1]=0
3.对于第三个字符c其前面前缀a , b不相等,所以没有前缀与后缀相等,故next[2]=0
4.对于第四个字符d其前缀有a,ab,后缀有bc,c,故前缀与后缀都不相等,所以next[3]=0
5.对于第五个字符a其前缀有a,ab,abc后缀有bcd,cd,c同样也是不相等,所以next[4]=0
6.对于第六个字符b其前缀有a,ab,abc,abcd,后缀有bcda,cda,da,a,这里我们发现有一个前缀与后缀相等那就是 a 所以next[5]=1
7.对于第七个字符d其前缀有a,ab,abc,abcd,abcda,后缀有bcdab,cdab,dab,ab,a其相等的前缀和后缀一共有两个,所以next[6]=2
a b c d a b d
next[0] next[1] next[2] next[3] next[4] next[5] next[6]
next数组的值: -1 0 0 0 0 1 2
注意:next数组的值只跟模式串有关,与主串无关
下面给大家一个其他模式串的示例,你们也可以试着看怎么去求得next数组

代码实现(C/C++)
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#define Maxsize 256
//顺序储存
typedef struct string {
char ch[Maxsize];//储存字符串
int length; //当前串的长度
}String;
//02---串的模式匹配算法 KMP算法
//next 数组获取
int* Next(String* S) {
assert(S);
int* next = (int*)malloc(sizeof(int) * S->length);//开辟一个跟模式串一样长度的数组next
int j = -1, i = 0; //初始化
next[0] = -1; //初始化
while (i < S->length-1) {
if (j == -1 || S->ch[i] == S->ch[j]) { //当j为-1时候,也就是主串和模式串字符不匹配时;或者主串和模式串字符匹配的时候,进行next 数组赋值操作
i++;
j++;
next[i] = j; //如果不匹配的话,此时next数组当前的位置赋值为0,如果匹配的话就依次+1
}
else {
j = next[j];
}
}
return next;
}
//算法接口
int Index_KMP(String* S, String* T) {
assert(S);
assert(T);
int i = 0, j = 0;
int* next = Next(&T);
while (i < S->length && j < T->length) {
if (S->ch[i] == S->ch[i])
{
i++;
j++;
}
else
{
//这里对比与BF算法,就少了主串i的回溯
j = next[j]; //模式串j就直接移到next数组当前的位置
}
}
if (j == T->length)
return i - j + 2;
return -1;
}算法分析
可以看出相较于BF算法,KMP算法大大提高了匹配效率,时间复杂度为O(m+n),m为主串长度,n为模式串长度
以上就是本期的全部内容,你们学会了吗?我们下一期再见咯!文章来源:https://www.toymoban.com/news/detail-714468.html
分享一张壁纸: 文章来源地址https://www.toymoban.com/news/detail-714468.html
文章来源地址https://www.toymoban.com/news/detail-714468.html
到了这里,关于数据结构-----串(String)详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!