大家好呀,mathorcup大数据赛今天下午六点开赛了,我先给大家带来一个初步的选题建议及思路哈,需要后续完整成品的可以直接点击本文章最下面的卡片哈。
OK废话不多说,本次mathorcup大数据赛时间跨度是很长的,一共一个月时间。
先定下主基调,本次难度上B<A,A题只建议数理基础比较扎实,队伍内有优化问题数学建模解决经验的同学选择,否则只建议选B,至于小白队伍,更不用说,直接无脑选B就行。
A题:

主要是解决一个优化问题:

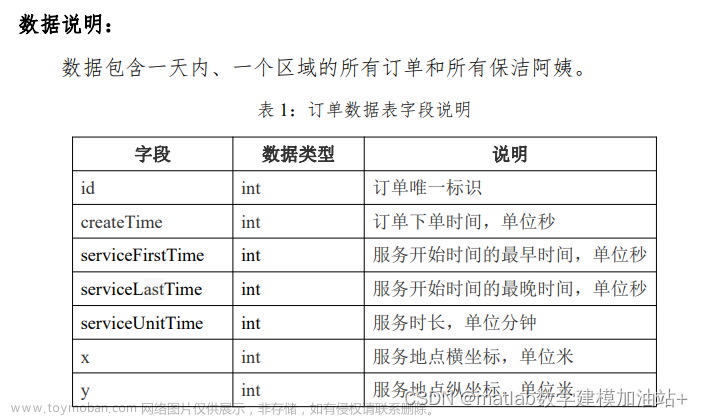
约束条件和优化目标都给的很清楚了,另外题目给的数据说明也很详细,那么直接规划求解就行,需要注意的是,最好和模拟退火或者遗传算法等启发式算法结合。
B题:

题目背景就不多说了,直接看题目:

问题一只是让我们给出一个权重大小,进而判别主要因素而已,注意,人家说的是:

所以不要只是筛出最大的因素,而是每个因素权重都要有。
看一下数据吧,这是语音满意度:

这是上网满意度:

其实就是研究剩下这么多项每一项对于这个满意度的影响权重大小而已。
而上网满意度的影响因素是要比语音满意度多很多的。
本问两种思路:
第一种就是通过熵值法或者主成分分析给出权重大小就行,这是比较简单的,
第二种也就是我更推荐的思路,是决策树预测,为什么这么说呢,看一下第二问:

附件三四本质上就是去除掉了满意度的,只包含有影响因素的一些数据:


所以本质上就是用附件1和2做训练集,3和4做测试集,再直白点也就是说,你要给出一个模型,能只通过这些影响因素去计算满意度大小,然后用附件1和2的真实满意度大小进行对比,如果说相差很小,那就说明预测精度很高,那就直接用来计算3和4就行。
为了照顾小白我一直都说得非常接地气哈。。。
好,那么用决策树预测的好处就是,我们可以直接在预测的训练过程中获得权重大小。
这些大家能理解了吧,等于我一个模型直接一二问全包了。
因为人家说了:

如果说只用第一种思路也就是熵值法这些,第二问是不太好做的。
大概就先说到这里吧,虽然这次的B我自己做起来难度没那么大,估计一天就能训练完,但是由于这次时间跨度很长,所以我会一直进行调参以提高训练精度,争取达到训练精度很高,预计3-4天内完成我的B题完整参考成品的书写,之后可能再写A,B题写完之后我也会更新手把手教大家去做的一个完整成品讲解。文章来源:https://www.toymoban.com/news/detail-714570.html
需要完整成品的直接点击下方卡片即可:文章来源地址https://www.toymoban.com/news/detail-714570.html
到了这里,关于2022mathorcup数学建模大数据竞赛选题建议及初步思路来啦!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!