目录
一 . K-近邻算法(KNN)概述
二、KNN算法实现
三、 MATLAB实现
四、 实战

一 . K-近邻算法(KNN)概述
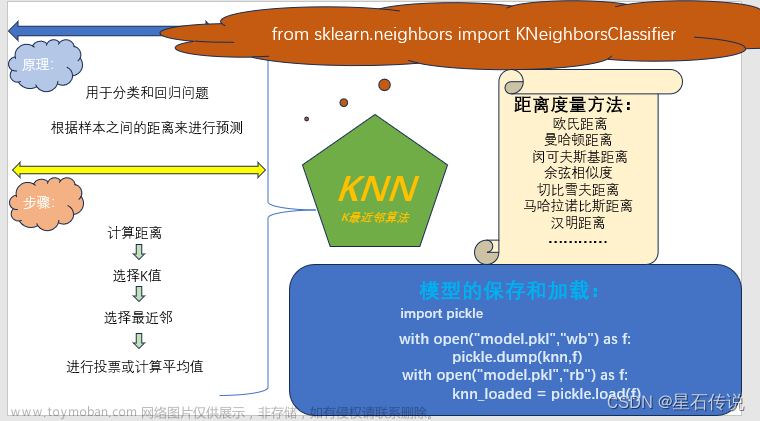
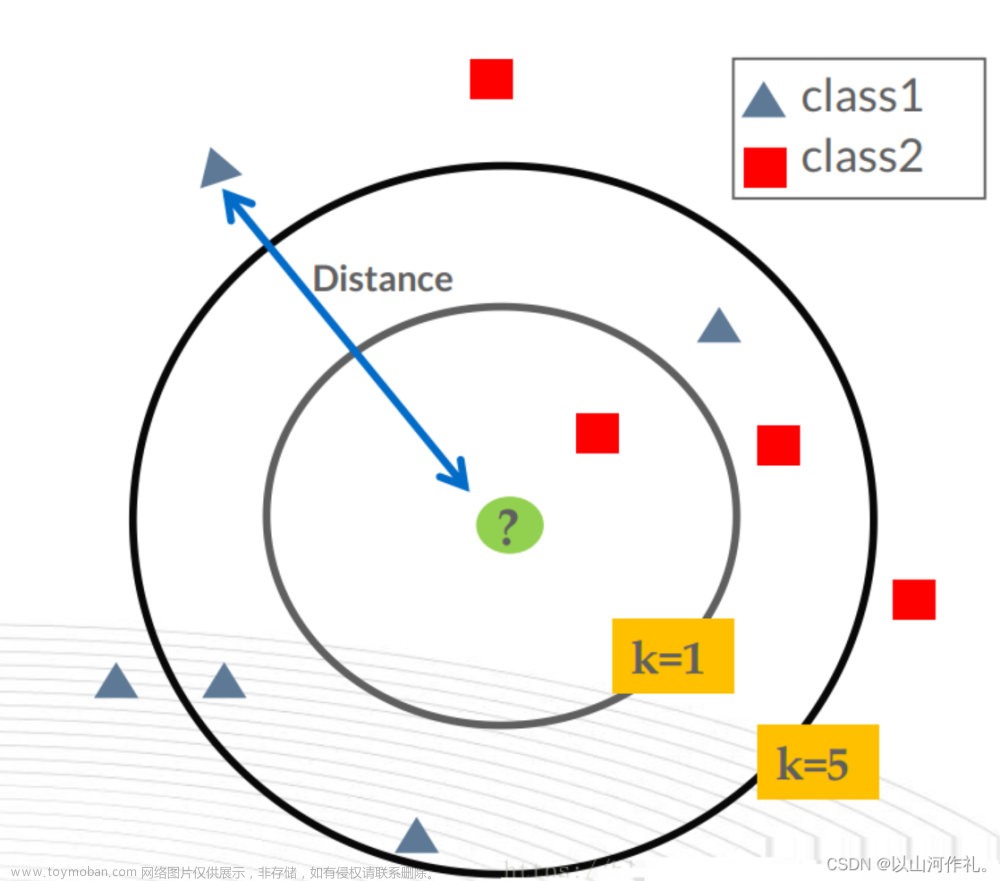
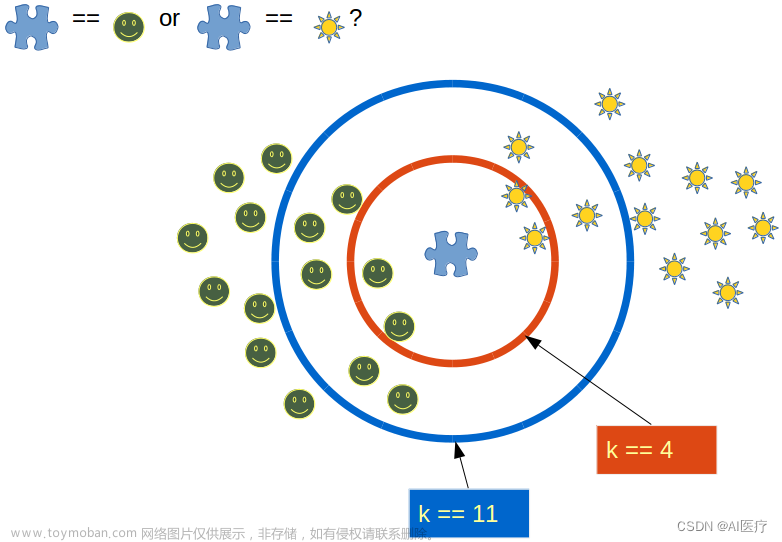
K-近邻算法(KNN)是一种基本的分类算法,它通过计算数据点之间的距离来进行分类。在KNN算法中,当我们需要对一个未知数据点进行分类时,它会与训练集中的各个数据点进行特征比较,并找到与之最相似的前K个数据点。然后根据这K个数据点的类别来确定未知数据点所属的类别。
KNN算法的步骤非常简单: 1)计算未知数据点与训练集中各个数据点之间的距离。常用的距离度量包括欧氏距离和曼哈顿距离。 2)按照距离递增的顺序对数据点进行排序。 3)选择距离最小的K个数据点。 4)根据这K个数据点的类别来确定未知数据点的类别。通常采用多数表决的方式,即统计K个数据点中各个类别出现的次数,将出现次数最多的类别作为未知数据点的预测类别。
KNN算法的特点是简单易懂,容易实现。它没有显式的训练过程,仅依赖于已有的训练数据。然而,KNN算法的计算复杂度较高,尤其是当训练集很大时。此外,KNN算法还对训练样本的质量和数量敏感,需要合理地选择K值和距离度量方法。

在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
首先需要收集足够的带有标签的训练数据,这些数据包含了输入特征和相应的输出标签。
对于输入的测试数据,需要计算它与每个训练数据之间的距离(如欧氏距离、曼哈顿距离等)。
选取距离测试数据最近的K个训练数据,并统计它们中出现最多的标签类别。
将测试数据归类为出现次数最多的标签类别。
二、KNN算法实现
KNN算法的实现通常可以使用Python等编程语言进行实现
import numpy as np
class KNN():
def __init__(self, k=3, distance='euclidean'):
self.k = k
self.distance = distance
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
y_pred = []
for x in X:
distances = []
for i, x_train in enumerate(self.X_train):
if self.distance == 'euclidean':
dist = np.linalg.norm(x - x_train)
elif self.distance == 'manhattan':
dist = np.sum(np.abs(x - x_train))
distances.append((dist, self.y_train[i]))
distances.sort()
neighbors = distances[:self.k]
classes = {}
for neighbor in neighbors:
if neighbor[1] in classes:
classes[neighbor[1]] += 1
else:
classes[neighbor[1]] = 1
max_class = max(classes, key=classes.get)
y_pred.append(max_class)
return y_pred
这段代码实现了基本的KNN分类算法,包括fit函数进行训练集拟合,predict函数进行预测。其中k参数表示要选择的最近邻居数,distance参数为距离度量方法。在上述示例代码中,欧氏距离和曼哈顿距离两种距离度量方法均已实现。
通过选择不同的数据集和参数,可以验证KNN算法的分类性能。在实现KNN算法时,还可以采用更加高效的数据结构(如kd树、球树)和距离度量方法等技巧,来对算法进行优化和改进。
三、 MATLAB实现
使用pdist2函数计算欧氏距离,而不是手动计算,可以极大地提高计算速度。
在计算距离之后,直接利用sort函数进行排序,并选择前k个最近邻。这样可以简化代码,并且使用向量化计算,计算速度更快。
使用mode函数求取邻居中出现次数最多的类别作为预测结果,并且使用2维输入方式保证正确性。
function y_pred = knn(X_train, y_train, X_test, k)
n_train = size(X_train, 1);
n_test = size(X_test, 1);
y_pred = zeros(n_test, 1);
% 计算欧氏距离
distances = pdist2(X_train, X_test);
% 选择前k个最近邻
[~, indices] = sort(distances);
neighbors = y_train(indices(1:k,:));
% 使用投票法预测标签
y_pred = mode(neighbors, 1)';
end
四、 实战
在这里根据一个人收集的约会数据,根据主要的样本特征以及得到的分类,对一些未知类别的数据进行分类,大致就是这样。
我使用的是python 3.4.3,首先建立一个文件,例如date.py,具体的代码如下:
#coding:utf-8
from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt
###导入特征数据
def file2matrix(filename):
fr = open(filename)
contain = fr.readlines()###读取文件的所有内容
count = len(contain)
returnMat = zeros((count,3))
classLabelVector = []
index = 0
for line in contain:
line = line.strip() ###截取所有的回车字符
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]###选取前三个元素,存储在特征矩阵中
classLabelVector.append(listFromLine[-1])###将列表的最后一列存储到向量classLabelVector中
index += 1
##将列表的最后一列由字符串转化为数字,便于以后的计算
dictClassLabel = Counter(classLabelVector)
classLabel = []
kind = list(dictClassLabel)
for item in classLabelVector:
if item == kind[0]:
item = 1
elif item == kind[1]:
item = 2
else:
item = 3
classLabel.append(item)
return returnMat,classLabel#####将文本中的数据导入到列表
##绘图(可以直观的表示出各特征对分类结果的影响程度)
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()
## 归一化数据,保证特征等权重
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))##建立与dataSet结构一样的矩阵
m = dataSet.shape[0]
for i in range(1,m):
normDataSet[i,:] = (dataSet[i,:] - minVals) / ranges
return normDataSet,ranges,minVals
##KNN算法
def classify(input,dataSet,label,k):
dataSize = dataSet.shape[0]
####计算欧式距离
diff = tile(input,(dataSize,1)) - dataSet
sqdiff = diff ** 2
squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量
dist = squareDist ** 0.5
##对距离进行排序
sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标
classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
##测试(选取10%测试)
def datingTest():
rate = 0.10
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
testNum = int(m * rate)
errorCount = 0.0
for i in range(1,testNum):
classifyResult = classify(normMat[i,:],normMat[testNum:m,:],datingLabels[testNum:m],3)
print("分类后的结果为:,", classifyResult)
print("原结果为:",datingLabels[i])
if(classifyResult != datingLabels[i]):
errorCount += 1.0
print("误分率为:",(errorCount/float(testNum)))
###预测函数
def classifyPerson():
resultList = ['一点也不喜欢','有一丢丢喜欢','灰常喜欢']
percentTats = float(input("玩视频所占的时间比?"))
miles = float(input("每年获得的飞行常客里程数?"))
iceCream = float(input("每周所消费的冰淇淋公升数?"))
datingDataMat,datingLabels = file2matrix('D:\python\Mechine learing in Action\KNN\datingTestSet2.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
inArr = array([miles,percentTats,iceCream])
classifierResult = classify((inArr-minVals)/ranges,normMat,datingLabels,3)
print("你对这个人的喜欢程度:",resultList[classifierResult - 1])新建test.py文件了解程序的运行结果,代码:
#coding:utf-8
from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt
import sys
sys.path.append("D:\python\Mechine learing in Action\KNN")
import date
date.classifyPerson()五、文末送书
 文章来源:https://www.toymoban.com/news/detail-715008.html
文章来源:https://www.toymoban.com/news/detail-715008.html
内容简介
《精通Go语言 (第2版)》详细阐述了与Go语言相关的基本解决方案,主要包括Go语言和操作系统,理解Go语言的内部机制,处理Go语言中的基本数据类型,组合类型的使用,利用数据结构改进Go代码,Go包和函数,反射和接口,UNIX系统编程,Go语言中的并发编程一协程、通道和管道,Go语言的并发性一高级话题,代码测试、优化和分析,网络编程基础知识,网络编程一构建自己的服务器和客户端,Go语言中的机器学习等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。文章来源地址https://www.toymoban.com/news/detail-715008.html
到了这里,关于【Python】机器学习-K-近邻(KNN)算法【文末送书】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!