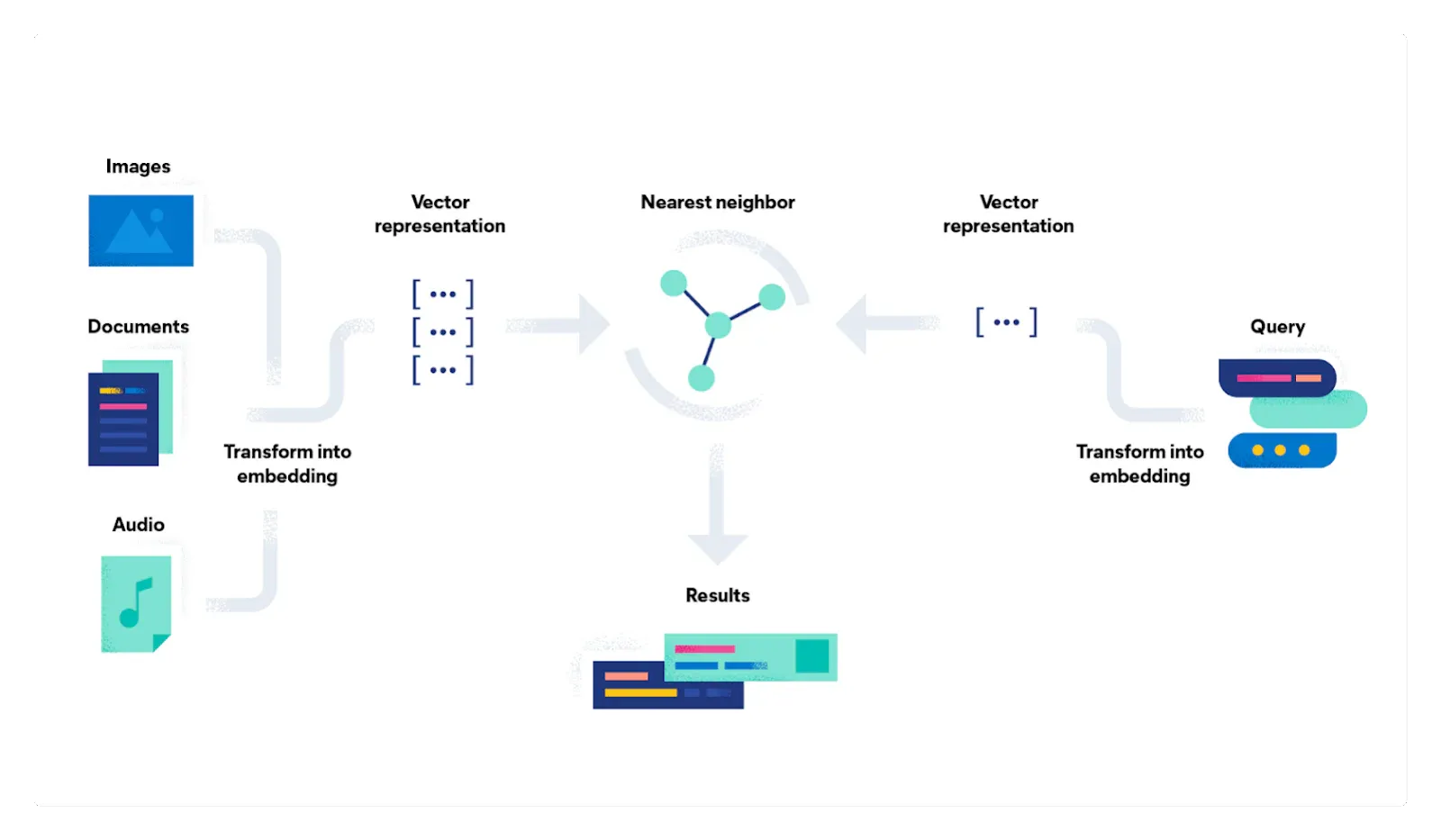
在本教程中,我将引导您使用 Elasticsearch、OpenAI、LangChain 和 FastAPI 构建语义搜索服务。
LangChain 是这个领域的新酷孩子。 它是一个旨在帮助你与大型语言模型 (LLM) 交互的库。 LangChain 简化了与 LLMs 相关的许多日常任务,例如从文档中提取文本或在向量数据库中对它们建立索引。 如果你现在正在与 LLMs 一起工作,LangChain 可以节省你的工作时间。
然而,它的一个缺点是,尽管它的文档很广泛,但可能比较分散,对于新手来说很难理解。 此外,大多数在线内容都集中在最新一代的向量数据库上。 由于许多组织仍在使用 Elasticsearch 这样经过实战考验的技术,我决定使用它编写一个教程。
我将 LangChain 和 Elasticsearch 结合到了最常见的 LLM 应用之一:语义搜索。 在本教程中,我将引导你使用 Elasticsearch、OpenAI、LangChain 和 FastAPI 构建语义搜索服务。 你将创建一个应用程序,让用户可以提出有关马可·奥勒留《沉思录》的问题,并通过从书中提取最相关的内容为他们提供简洁的答案。
让我们深入了解吧!
前提条件
你应该熟悉这些主题才能充分利用本教程:
-
Elasticsearch:语义搜索、知识图和向量数据库概述
-
Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x
此外,你必须安装 Docker 并在 OpenAI 上创建一个帐户。
设计语义搜索服务
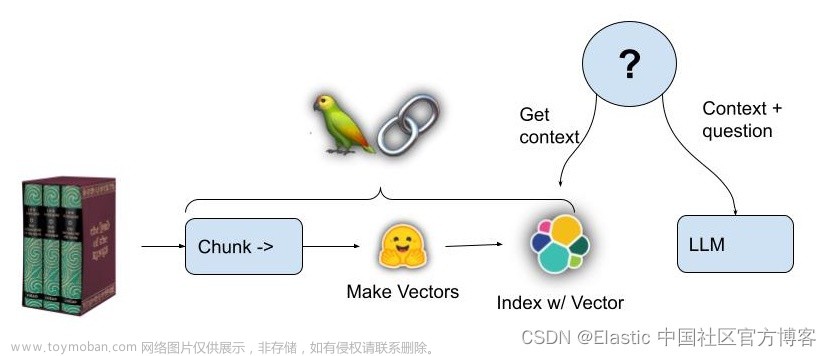
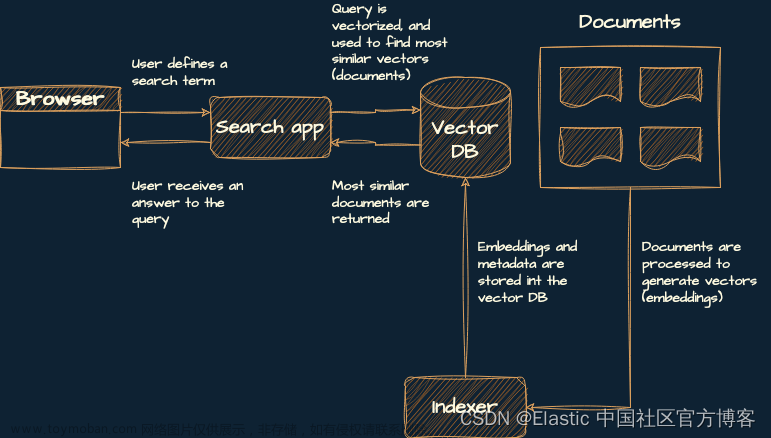
你将构建一个包含三个组件的服务:
- 索引器:这将创建索引,生成嵌入和元数据(在本例中为书籍的来源和标题),并将它们添加到向量数据库中。
- 矢量数据库:这是一个用于存储和检索生成的嵌入的数据库。
- 搜索应用程序:这是一个后端服务,它使用用户的搜索词,从中生成嵌入,然后在矢量数据库中查找最相似的嵌入。
这是该架构的示意图:
接下来,你将设置本地环境。
设置你的本地环境
请按照以下步骤设置您的本地环境:
1)安装 Python 3.10。
2)安装 Poetry。 它是可选的,但强烈推荐。
sudo pip install poetry
3) 克隆项目的存储库:
git clone https://github.com/liu-xiao-guo/semantic-search-elasticsearch-openai-langchain4)从项目的根文件夹中,安装依赖项:
- 使用 Poetry:在项目同目录下创建虚拟环境并安装依赖:
poetry config virtualenvs.in-project true
poetry install- 使用 venv 和 pip:创建虚拟环境并安装 requirements.txt 中列出的依赖项:
python3.10 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt5)打开 src/.env-example,添加你的 OpenAI 密钥,并将文件另存为 .env。
(.venv) $ pwd
/Users/liuxg/python/semantic-search-elasticsearch-openai-langchain/src
(.venv) $ ls -al
total 32
drwxr-xr-x 7 liuxg staff 224 Sep 17 17:27 .
drwxr-xr-x 13 liuxg staff 416 Sep 17 21:23 ..
-rw-r--r-- 1 liuxg staff 41 Sep 17 17:27 .env-example
-rw-r--r-- 1 liuxg staff 870 Sep 17 17:27 app.py
-rw-r--r-- 1 liuxg staff 384 Sep 17 17:27 config.py
drwxr-xr-x 3 liuxg staff 96 Sep 17 17:27 data
-rw-r--r-- 1 liuxg staff 840 Sep 17 17:27 indexer.py
(.venv) $ mv .env-example .env
(.venv) $ vi .env到目前为止,你将设置一个包含所需库和存储库的本地副本的虚拟环境。 你的项目结构应该如下所示:
.
├── LICENSE
├── README.md
├── docker-compose.yml
├── .env
├── poetry.lock
├── pyproject.toml
├── requirements.txt
└── src
├── app.py
├── config.py
├── .env
├── .env-example
├── data
│ └── Marcus_Aurelius_Antoninus_-_His_Meditations_concerning_himselfe
└── indexer.py
请注意:在上面的文件结构中,有两个 .env 文件。根目录下的 .env 文件是为 docker-compose.yml 文件所使用,而 src 目录里的文件是为应用所示使用。我们可以在根目录里的 .env 文件中定义想要的 Elastic Stack 版本号。
这些是项目中最相关的文件和目录:
- poetry.lock 和 pyproject.toml:这些文件包含项目的规范和依赖项,被 Poetry 用来创建虚拟环境。
- requirements.txt:该文件包含项目所需的 Python 包列表。
- docker-compose.yml:此文件包含用于在本地运行 Elasticsearch 集群及 Kibana。
- src/app.py:该文件包含搜索应用程序的代码。
- src/config.py:此文件包含项目配置规范,例如 OpenAI 的 API 密钥(从 .env 文件读取)、数据路径和索引名称。
- src/data/:该目录包含最初从维基文库下载的 Meditations 。 你将使用它作为本教程的文本语料库。
- src/indexer.py:此文件包含用于创建索引并将文档插入 Elasticsearch 的代码。
- .env-example:此文件通常用于环境变量。 在本例中,你可以使用它将 OpenAI 的 API 密钥传递给您的应用程序。
- .venv/:该目录包含项目的虚拟环境。
全做完了! 我们继续向下进行吧。
启动本地 Elasticsearch 集群
在我们进入代码之前,你应该启动一个本地 Elasticsearch 集群。 打开一个新终端,导航到项目的根文件夹,然后运行:
docker-compose up
在上面的部署中,出于方便,我们使用了没有带安全的 Elastic Stack 的安装以方便进行开发。具体的安装步骤,请参阅另外一篇文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发”。如果一切顺利,我们可以使用如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a2866c0356a2 kibana:8.9.2 "/bin/tini -- /usr/l…" 4 minutes ago Up 4 minutes 0.0.0.0:5601->5601/tcp kibana
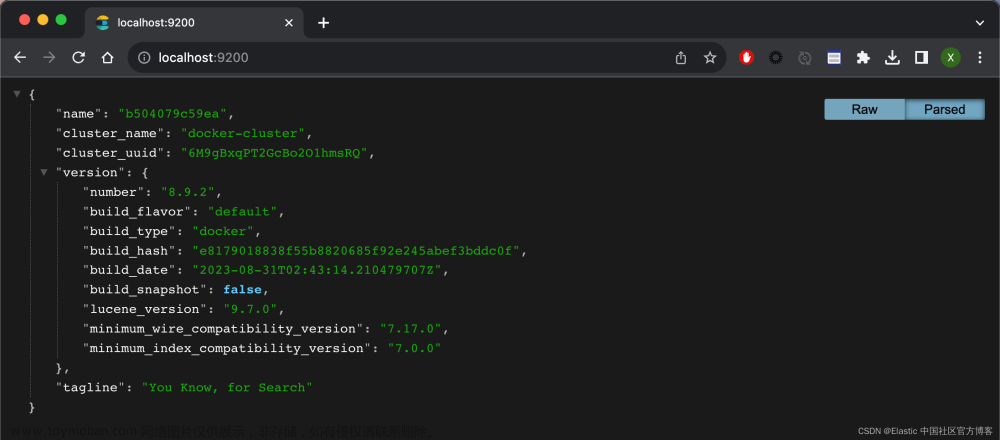
b504079c59ea elasticsearch:8.9.2 "/bin/tini -- /usr/l…" 4 minutes ago Up 4 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch我们可以在浏览器中针对 Elasticsearch 进行访问:
我们还可以在 localhost:5601 上访问 Kibana:
拆分书籍并为其建立索引


在此步骤中,你将执行两件事:
- 通过将书中的文本拆分为 1,000 个 token 的块来处理该文本。
- 对你在 Elasticsearch 集群中生成的文本块(从现在开始称为文档)建立索引。
看一下 src/indexer.py:
from langchain.document_loaders import BSHTMLLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import ElasticVectorSearch
from config import Paths, openai_api_key
def main():
loader = BSHTMLLoader(str(Paths.book))
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
documents = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
db = ElasticVectorSearch.from_documents(
documents,
embeddings,
elasticsearch_url="http://localhost:9200",
index_name="elastic-index",
)
print(db.client.info())
if __name__ == "__main__":
main()此代码采用 Meditations(书),将其拆分为 1,000 个 token 的文本块,然后在 Elasticsearch 集群中为这些块建立索引。 以下是详细的细分:
- 第 1 行到第 4 行从 langchain 导入所需的组件:
- BSHTMLLoader:此 Loader 使用 BeautifulSoup4 来解析文档。
- OpenAIembeddings:该组件是 OpenAI 嵌入的包装器。 它可以帮助你生成文档和查询的嵌入。
- RecursiveCharacterTextSplitter:此实用程序函数通过尝试按旨在保持语义相似内容邻近的顺序尝试各种字符来分割输入文本。 用于分割的字符按以下顺序排列为:“\n\n”、“\n”、“ ”、“”。
- ElasticSearchVector:这是 Elasticsearch 客户端的包装器,可简化与集群的交互。
- 第 6 行从 config.py 导入相关配置
- 第 11 行和第 12 行使用 BSHTMLLoader 提取书籍的文本。
- 第 13 至 16 行初始化文本拆分器,并将文本拆分为不超过 1,000 个标记的块。 在这种情况下,你可以使用 tiktoken 来计算 token,但你也可以使用不同长度的函数,例如计算字符数而不是 token 或不同的 token 化函数。
- 第 18 至 25 行初始化嵌入函数,创建新索引,并对文本拆分器生成的文档建立索引。 在 elasticsearch_url 中,你指定应用程序在本地运行的端口,在index_name 中指定你将使用的索引的名称。 最后,打印 Elasticsearch 客户端信息。
要运行此脚本,请打开终端,激活虚拟环境,然后从项目的 src 文件夹中运行以下命令:
# ../src/
export export OPENAI_API_KEY=your_open_ai_token
python indexer.py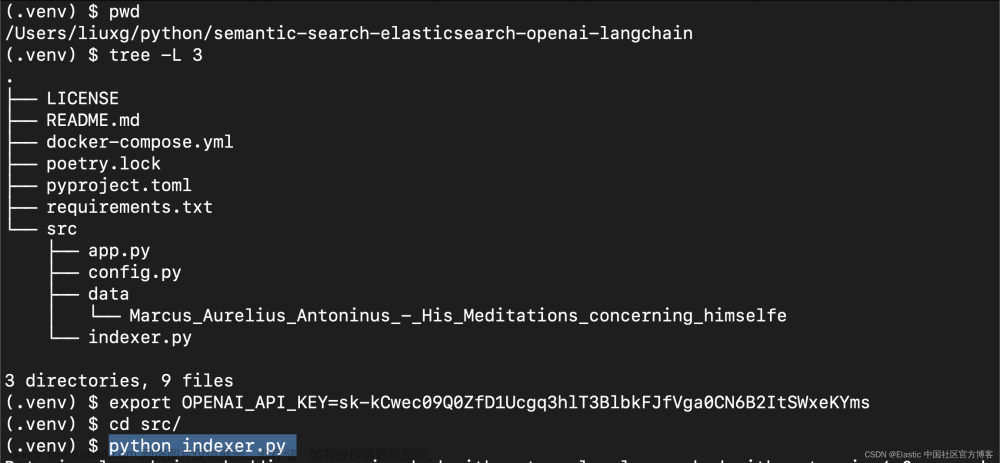
注意:你如果使用 OpenAI 来进行矢量化,那么你需要在你的账号中有充分的钱来支付这种费用,否则你可能得到如下的错误信息:
Retrying langchain.embeddings.openai.embed_with_retry.<locals>._embed_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
如果一切顺利,你应该得到与此类似的输出:
{'name': '0e1113eb2915', 'cluster_name': 'docker-cluster', 'cluster_uuid': 'og6mFMqwQtaJiv_3E_q2YQ', 'version': {'number': '8.9.2', 'build_flavor': 'default', 'build_type': 'docker', 'build_hash': '09520b59b6bc1057340b55750186466ea715e30e', 'build_date': '2023-03-27T16:31:09.816451435Z', 'build_snapshot': False, 'lucene_version': '9.5.0', 'minimum_wire_compatibility_version': '7.17.0', 'minimum_index_compatibility_version': '7.0.0'}, 'tagline': 'You Know, for Search'}接下来,让我们创建一个简单的 FastAPI 应用程序,以与你的集群进行交互。
创建搜索应用程序
在此步骤中,你将创建一个简单的应用程序来与 Meditations 交互。 你将连接到 Elasticsearch 集群,始化检索提问/应答 Chain,并创建一个 /ask 端点以允许用户与应用程序交互。
看一下 src/app.py 的代码:
from fastapi import FastAPI
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import ElasticVectorSearch
from config import openai_api_key
embedding = OpenAIEmbeddings(openai_api_key=openai_api_key)
db = ElasticVectorSearch(
elasticsearch_url="http://localhost:9200",
index_name="elastic-index",
embedding=embedding,
)
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=db.as_retriever(),
)
app = FastAPI()
@app.get("/")
def index():
return {
"message": "Make a post request to /ask to ask questions about Meditations by Marcus Aurelius"
}
@app.post("/ask")
def ask(query: str):
response = qa.run(query)
return {
"response": response,
}
此代码允许用户提出有关马库斯·奥勒留《沉思录》的问题,并向用户提供答案。 让我向你展示它是如何工作的:
- 第 1 至 5 行导入所需的库:
- FastAPI:此类初始化应用程序。
- RetrievalQA:这是一个允许你询问有关向量数据库中文档的问题的 Chain。 它根据你的问题找到最相关的文档并从中生成答案。
- ChatOpenAI:这是 OpenAI 聊天模型的包装。
- OpenAIembeddings 和 ElasticVectorSearch:这些是上一节中讨论的相同包装器。
- 第 7 行导入 OpenAI 密钥。
- 第 9 至 15 行使用 OpenAI 嵌入初始化 Elasticsearch 集群。
- 第 16 至 20 行使用以下参数初始化 RetrievalQA Chain:
- llm:指定用于运行链中定义的提示的 LLM。
- chain_type:定义如何从向量数据库检索和处理文档。 通过指定内容,将检索文档并将其传递到链以按原样回答问题。 或者,你可以在回答问题之前使用 map_reduce 或 map_rerank 进行额外处理,但这些方法使用更多的 API 调用。 有关更多信息,请参阅 langchain 文档。
- retrieve:指定链用于检索文档的向量数据库。
- 第 22 至 36 行初始化 FastAPI 应用程序并定义两个端点。 / 端点为用户提供有关如何使用应用程序的信息。 /ask 端点接受用户的问题(查询参数)并使用先前初始化的链返回答案。
最后,你可以从终端运行该应用程序(使用你的虚拟环境):
uvicorn app:app --reload然后,访问 http://127.0.0.1:8000/docs,并通过询问有关这本书的问题来测试 /ask:
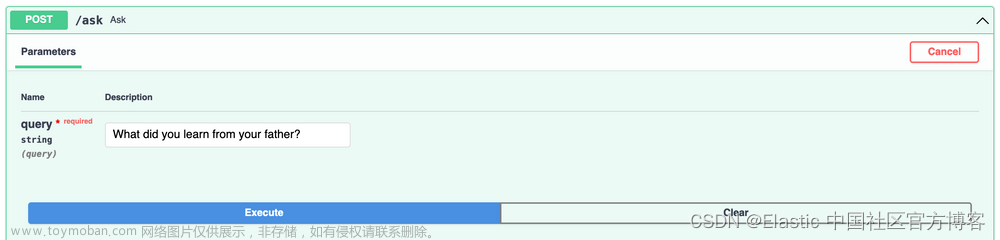
如果一切顺利,你应该得到这样的结果:

就是这样! 您现在已经启动并运行了自己的基于 Elasticsearch、OpenAI、Langchain 和 FastAPI 的语义搜索服务。
结论
干得好! 在本教程中,你学习了如何使用 Elasticsearch、OpenAI 和 Langchain 构建语义搜索引擎。
特别是,你已经了解到:文章来源:https://www.toymoban.com/news/detail-715242.html
- 如何构建语义搜索服务。
- 如何使用 LangChain 对文档进行拆分和索引。
- 如何使用 Elasticsearch 作为向量数据库与 LangChain 一起使用。
- 如何使用检索问答链通过向量数据库回答问题。
- 产品化此类应用程序时应考虑什么。
希望您觉得本教程有用。 如果你有任何疑问,请参入讨论!文章来源地址https://www.toymoban.com/news/detail-715242.html
到了这里,关于使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!