序言
心若有阳光,你便会看见这个世界有那么多美好值得期待和向往。
决定开一个算法专栏,希望能帮助大家很好的了解算法。主要深入解析每个算法,从概念到示例。
我们一起努力,成为更好的自己!
今天第9讲,讲一下查找算法的哈希表查找
1 基础介绍
查找算法是计算机科学中的一类算法,用于在数据集中寻找特定值或数据项。
查找算法的目标是确定数据是否存在于给定的数据结构中,并找到数据项的位置(索引)或其他相关信息。
不同的查找算法适用于不同类型的数据结构,数据有序性,以及数据规模。以下是一些常见的查找算法
以下是一些常见的查找算法及其应用场景:
- 布隆过滤器(Bloom Filter):适用于判断一个元素是否存在于一个大规模的数据集中,时间复杂度为O(1),但有一定的误判率。
- 二分查找(Binary Search):适用于有序数组中查找元素,时间复杂度为O(log n);
- 哈希表查找(Hash Table):适用于快速查找和插入元素,时间复杂度为O(1),但需要额外的存储空间;
- 线性查找(Linear Search):适用于无序数组中查找元素,时间复杂度为O(n);
- 插值查找(Interpolation Search):适用于有序数组中查找元素,时间复杂度为O(log log n),但是对于分布不均匀的数据集效果不佳;
- 斐波那契查找(Fibonacci Search):适用于有序数组中查找元素,时间复杂度为O(log n),但需要额外的存储空间;
- 树表查找(Tree Search):适用于快速查找和插入元素,时间复杂度为O(log n),但需要额外的存储空间;
- B树查找(B-Tree):适用于大规模数据存储和查找,时间复杂度为O(log n),但需要额外的存储空间;
一、哈希表查找介绍
哈希表查找算法是一种基于哈希表数据结构的数据查找方法,用于高效地检索特定数据项
1.1 原理介绍
1.1.1原理详情
哈希表结构:
- 哈希表通常由一个数组(Bucket)组成,数组的每个位置称为一个桶,用于存储键-值对。
- 为了查找数据项,我们使用一个哈希函数来将键映射到数组中的一个特定位置(索引)。
哈希函数:
- 哈希函数接受键作为输入,并返回一个固定大小的哈希码(Hash Code)。
- 哈希函数的目标是将不同的键映射到不同的索引位置,同时尽量减少哈希冲突。
插入数据:
- 当需要插入一对键-值对时,首先通过哈希函数计算键的哈希码。
- 然后,根据哈希码确定要存储该数据的桶的位置。
- 将键-值对存储在相应的桶中。如果多个数据项映射到同一个桶,通常使用链表或其他数据结构来处理冲突。
查找数据:
- 当需要查找特定键的值时,再次使用哈希函数计算键的哈希码。
- 根据哈希码确定数据所在的桶的位置。
- 如果有哈希冲突,可以遍历链表或其他数据结构,直到找到目标数据项。
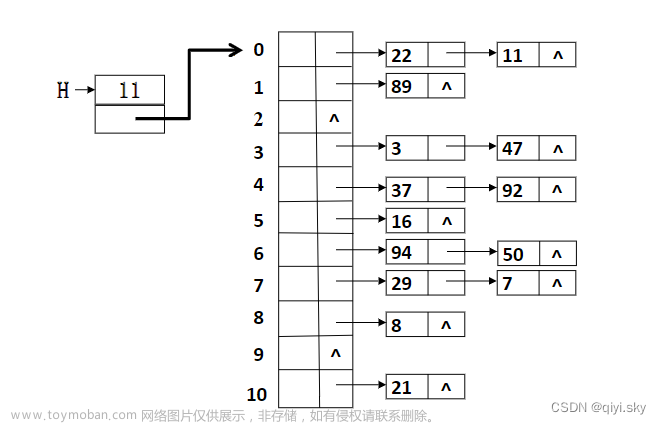
下面是一个哈希表查找算法原理简化图示说明:

- 每个桶中可以存储一个或多个键-值对,如Bucket 1中的(Key1, Value1)和(Key2, Value2)。
- 哈希函数确定了键将存储在哪个桶中,例如,Key1的哈希码可能决定了它存储在Bucket 1中。
- 查找时,通过哈希函数找到正确的桶,然后遍历该桶以找到特定键对应的值。
这个图示简要说明了哈希表查找算法的基本原理。哈希表的高效性来自于哈希函数的正确选择以及冲突处理方法的有效性。
1.1.2 拓展:
哈希表:
- 哈希表是一个数组,其每个元素通常被称为桶(Bucket)或槽(Slot)。
- 哈希表使用哈希函数将数据项的键映射到特定的索引位置,这个索引位置通常通过哈希码来确定。
- 当要查找一个数据项时,哈希表会使用相同的哈希函数来计算数据项的哈希码,然后定位到对应的桶。
哈希冲突处理:
- 哈希表中可能会出现哈希冲突,即多个数据项映射到相同的桶。常见的冲突解决方法包括链地址法(Chaining)和线性探测法(Linear Probing)。
- 使用链地址法时,每个桶维护一个链表,哈希冲突的数据项被插入到链表中。查找时,遍历链表以查找目标数据项。
- 使用线性探测法时,如果一个桶已经被占用,算法会线性地探测下一个可用的桶,直到找到目标数据项或空桶。这种方法需要特别处理删除操作。
1.2 算法执行过程
初始化哈希表:创建一个固定大小的数组,将每个元素的值设置为其索引。
插入元素:根据要插入的元素计算其哈希值,然后将该元素插入到对应索引的位置。如果发生哈希冲突(即两个不同的元素具有相同的哈希值),则在相应索引位置存储一个链表,链表中存储具有相同哈希值的所有元素。
查找元素:首先计算要查找元素的哈希值,然后根据哈希值找到对应的索引位置。如果该位置没有其他元素,说明找到了目标元素;否则,在对应索引位置的链表中继续查找。
删除元素:如果要删除的元素恰好等于目标元素,那么直接删除即可;否则,需要找到该元素所在的链表,并从链表中删除该元素。
扩容:当哈希表的大小超过了数组的最大容量时,需要对数组进行扩容,即创建一个新的更大的数组,并将原数组中的元素重新插入到新数组中。同时,还需要重新计算所有元素的哈希值,并将它们插入到新数组的相应位置。
1.3 优缺点
1.3.1 优点:
快速查找:
- 哈希表查找操作通常具有O(1)的平均时间复杂度,这意味着查找所需的时间与数据集的大小无关。在理想情况下,哈希表允许常数时间的查找操作。
高效的插入和删除:
- 哈希表对插入和删除操作同样高效,通常具有O(1)的时间复杂度。
- 插入和删除操作不会导致数据项的整体重新排序,这使得哈希表非常适合需要频繁插入和删除操作的应用。
灵活性:
- 哈希表可以用于多种数据类型,不仅限于整数键,还可以使用自定义对象作为键。
快速索引计算:
- 哈希函数可以通过哈希码迅速计算数据项的索引位置,而不需要遍历整个数据集。
适用于大数据集:
- 哈希表适用于大规模数据集,因为查找操作的性能不受数据集大小的影响,只与哈希函数和冲突解决方法有关。
1.3.2 缺点:
哈希冲突:
- 哈希表中可能会出现哈希冲突,即多个不同的数据项映射到同一个索引位置。冲突会降低查找性能。
- 解决冲突需要额外的开销,如链地址法或线性探测法,这会增加代码的复杂性。
不保留顺序:
- 哈希表不保留数据项的顺序,因此不适合需要有序数据集的应用。如果需要按顺序访问数据,哈希表可能不是最佳选择。
依赖于哈希函数:
- 哈希表的性能直接依赖于哈希函数的质量。低质量的哈希函数可能会导致冲突增加,从而降低性能。
内存消耗:
- 哈希表可能需要分配较大的内存以容纳哈希表和数据项。这可能成为内存消耗方面的问题,尤其是在大规模数据集上。
不适合部分匹配查找:
- 哈希表不适用于部分匹配查找,只能用于查找完全匹配的数据项。
1.4 复杂度
哈希表查找算法具有一些重要的复杂度,包括平均情况和最坏情况下的时间复杂度,以及空间复杂度。
以下是详细介绍哈希表查找算法的各种复杂度:
平均情况时间复杂度:
- 在哈希表中进行查找操作的平均时间复杂度通常是O(1)。
- 这意味着无论数据集的大小如何,平均查找时间都是常数级的,因为哈希表的哈希函数通常能够将数据项均匀地分布到桶中。
- 这是哈希表查找算法的一个关键优势,使其在大型数据集中表现出色。
最坏情况时间复杂度:
- 在最坏情况下,哈希表查找操作的时间复杂度可能是O(n),其中n是哈希表中的数据项数量。
- 最坏情况通常发生在哈希冲突较为频繁的情况下,这导致了多个数据项映射到同一个桶中,需要遍历这些数据项以查找目标项。
- 尽管在最坏情况下哈希表的性能较差,但出现最坏情况的概率通常很低,因此平均情况下哈希表仍然具有O(1)的查找时间。
空间复杂度:
- 哈希表的空间复杂度主要取决于其存储数据项的大小和哈希表的大小。
- 哈希表的存储空间主要用于存储数据项本身,以及用于桶(Bucket)的内存空间。
- 空间复杂度通常被认为是O(n),其中n是数据项的数量,但可以受到哈希表的负载因子和实现细节的影响。
哈希函数的复杂度:
- 哈希函数的性能和复杂度对哈希表查找算法非常重要。
- 一个好的哈希函数应该具有较低的冲突概率,以减少最坏情况下的时间复杂度。在设计哈希函数时,需要考虑均匀性和散列性。
1.5 使用场景
哈希表查找算法在各种应用中都有广泛的用途,特别是在需要快速查找和数据存储的情况下。
选择哈希表作为解决方案时,需要考虑数据的性质、哈希函数的选择以及冲突处理方法,以确保性能和可扩展性
以下是一些常见的哈希表查找算法的使用场景:
字典和关联数组:哈希表常用于实现字典和关联数组,其中键映射到值。这样可以快速查找特定键对应的值。
缓存:哈希表用于数据缓存,允许快速访问已经检索的数据,以减少对慢速存储介质(如磁盘)的访问。
数据库索引:在数据库管理系统中,哈希表用于构建索引,以便快速检索和访问数据库中的数据。这在大型数据库中非常有用。
散列集合:编程语言中的集合(Set)和散列集合(HashSet)通常使用哈希表来实现,以便快速查找成员。
数据去重:哈希表可用于检测和删除重复数据项。通过将数据插入哈希表并检查是否已经存在,可以有效去重。
认证和授权:哈希表可用于存储用户凭据(如用户名和密码)或授权令牌,以便快速验证用户身份。
编译器符号表:编程语言编译器使用哈希表来管理符号表,以便快速查找变量、函数和其他符号的定义和引用。
数据分布:在分布式计算中,哈希表用于确定数据项应该存储在哪个节点或分片,以实现均匀的数据分布。
缓存管理:缓存管理系统通常使用哈希表来跟踪缓存的内容,以加速数据检索。
路由表:网络路由器使用哈希表来管理路由表,以确定数据包的转发路径。
文件系统索引:文件系统通常使用哈希表来维护文件索引,以加速文件查找和访问。
编码查找表:在编码和解码中,哈希表可用于存储查找表,以实现快速的字符或编码查找。
二、代码实现
2.1 Java代码实现
以下是一个简单的示例,使用Java实现一个哈希表查找算法。
2.1.1 代码示例
public class HashTable {
private int size;
private String[] keys;
private String[] values;
public HashTable(int size) {
this.size = size;
keys = new String[size];
values = new String[size];
}
private int hash(String key) {
int hash = key.hashCode();
return Math.abs(hash % size);
}
public void put(String key, String value) {
int index = hash(key);
while (keys[index] != null) {
if (keys[index].equals(key)) {
values[index] = value;
return;
}
index = (index + 1) % size;
}
keys[index] = key;
values[index] = value;
}
public String get(String key) {
int index = hash(key);
while (keys[index] != null) {
if (keys[index].equals(key)) {
return values[index];
}
index = (index + 1) % size;
}
return null;
}
public static void main(String[] args) {
HashTable hashTable = new HashTable(10);
// 插入数据
hashTable.put("Alice", "123-456-7890");
hashTable.put("Bob", "456-789-0123");
hashTable.put("Charlie", "789-012-3456");
// 查找数据
System.out.println("Alice's phone number: " + hashTable.get("Alice"));
System.out.println("Bob's phone number: " + hashTable.get("Bob"));
System.out.println("Charlie's phone number: " + hashTable.get("Charlie"));
System.out.println("Dave's phone number: " + hashTable.get("Dave"));
}
}
2.1.2 代码讲解
在这个示例中,我首先创建了一个哈希表对象,然后使用
put方法插入一些键值对,使用get方法查找特定键对应的值。使用了一个基本的哈希函数来计算键的哈希值,然后使用线性探测法来处理冲突。
2.1.3 执行结果
执行这个代码示例后,将看到以下输出:
Alice's phone number: 123-456-7890
Bob's phone number: 456-789-0123
Charlie's phone number: 789-012-3456
Dave's phone number: null
2.2 Python 代码实现
以下是一个使用Python实现的简单哈希表查找算法示例
2.1.1 代码示例
class HashTable:
def __init__(self, size):
self.size = size
self.table = [[] for _ in range(size)]
def _hash(self, key):
return hash(key) % self.size
def put(self, key, value):
index = self._hash(key)
for pair in self.table[index]:
if pair[0] == key:
pair[1] = value
return
self.table[index].append([key, value])
def get(self, key):
index = self._hash(key)
for pair in self.table[index]:
if pair[0] == key:
return pair[1]
return None
if __name__ == "__main__":
hash_table = HashTable(10)
# 插入数据
hash_table.put("Alice", "123-456-7890")
hash_table.put("Bob", "456-789-0123")
hash_table.put("Charlie", "789-012-3456")
# 查找数据
print("Alice's phone number:", hash_table.get("Alice"))
print("Bob's phone number:", hash_table.get("Bob"))
print("Charlie's phone number:", hash_table.get("Charlie"))
print("Dave's phone number:", hash_table.get("Dave"))
2.1.2 代码讲解
在这个示例中,首先创建了一个哈希表对象,然后使用
put方法插入一些键值对,使用get方法查找特定键对应的值。使用了Python的内置
hash函数来计算键的哈希值,并使用链地址法来处理冲突。
2.1.3 执行结果
执行这个代码示例后,将看到以下输出:
Alice's phone number: 123-456-7890
Bob's phone number: 456-789-0123
Charlie's phone number: 789-012-3456
Dave's phone number: None
哈希表成功地插入和查找了键值对,并且在找不到键时返回了
None。这个示例演示了哈希表的基本原理和使用方式。
三、总结
哈希表查找算法在许多应用中具有高效的性能,但它也有一些限制,如哈希冲突和不适合有序数据。
选择哈希表作为查找数据结构时,需要权衡其优点和缺点,并确保选择合适的哈希函数和冲突解决方法。
四、图书推荐
4.1 图书名称

《Python数据挖掘:入门、进阶与实用案例分析 》
4.2 图书介绍
《Python数据挖掘:入门、进阶与实用案例分析》是一本以项目实战案例为驱动的数据挖掘著作,它能帮助完全没有Python编程基础和数据挖掘基础的读者快速掌握Python数据挖掘的技术、流程与方法。
在写作方式上,与传统的“理论与实践结合”的入门书不同,它以数据挖掘领域的知名赛事“泰迪杯”数据挖掘挑战赛(已举办10届)和“泰迪杯”数据分析技能赛(已举办5届)(累计1500余所高校的10余万师生参赛)为依托,精选了11个经典赛题,将Python编程知识、数据挖掘知识和行业知识三者融合,让读者在实践中快速掌握电商、教育、交通、传媒、电力、旅游、制造等7大行业的数据挖掘方法。

本书不仅适用于零基础的读者自学,还适用于教师教学,为了帮助读者更加高效地掌握本书的内容,本书提供了以下10项附加价值:
- (1)建模平台:提供一站式大数据挖掘建模平台,免配置,包含大量案例工程,边练边学,告别纸上谈兵
- (2)视频讲解:提供不少于600分钟Python编程和数据挖掘相关教学视频,边看边学,快速收获经验值
- (3)精选习题:精心挑选不少于60道数据挖掘练习题,并提供详细解答,边学边练,检查知识盲区
- (4)作者答疑:学习过程中有任何问题,通过“树洞”小程序,纸书拍照,一键发给作者,边问边学,事半功倍
- (5)数据文件:提供各个案例配套的数据文件,与工程实践结合,开箱即用,增强实操性
- (6)程序代码:提供书中代码的电子文件及相关工具的安装包,代码导入平台即可运行,学习效果立竿见影
- (7)教学课件:提供配套的PPT课件,使用本书作为教材的老师可以申请,节省备课时间
- (8)模型服务:提供不少于10个数据挖掘模型,模型提供完整的案例实现过程,助力提升数据挖掘实践能力
- (9)教学平台:泰迪科技为本书提供的附加资源提供一站式数据化教学平台,附有详细操作指南,边看边学边练,节省时间
- (10)就业推荐:提供大量就业推荐机会,与1500+企业合作,包含华为、京东、美的等知名企业
通过学习本书,可以理解数据挖掘的原理,迅速掌握大数据技术的相关操作,为后续数据分析、数据挖掘、深度学习的实践及竞赛打下良好的技术基础。
4.3 参与方式
图书数量:本次送出 4 本 !!!⭐️⭐️⭐️
活动时间:截止到 2023-10-16 12:00:00抽奖方式:
- 评论区随机抽取小伙伴!
留言内容,以下方式都可以:
- 根据文章内容进行高质量评论
参与方式:关注博主、点赞、收藏,评论区留言
4.4 中奖名单
🍓🍓 获奖名单🍓🍓
中奖名单:请关注博主动态文章来源:https://www.toymoban.com/news/detail-715372.html
名单公布时间:2023-10-16 下午文章来源地址https://www.toymoban.com/news/detail-715372.html
到了这里,关于【算法系列 | 9】深入解析查找算法之—哈希表查找的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!