变量与可变性
变量与可变性
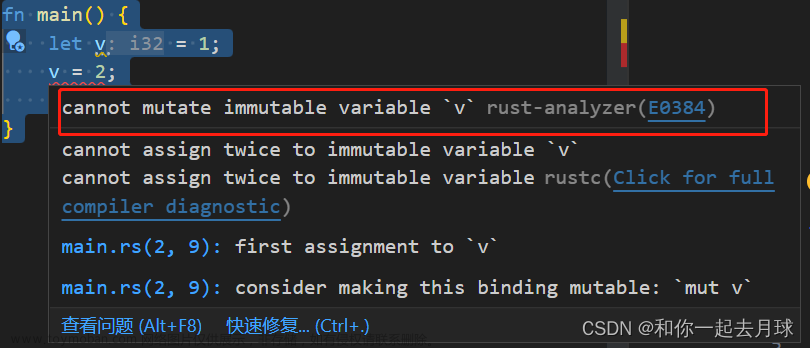
在Rust中,声明变量使用let关键字,并且默认情况下,声明的变量是不可变的,要使变量可变需要在声明变量时,在变量前面加上mut关键字。如下:
fn main() {
let mut x = 10;
println!("x = {}", x); //x = 10
x = 20;
println!("x = {}", x); //x = 20
}
如果将上述代码中的mut关键字去掉,那么在编译代码时就会报错,报错结果就是不能对不可变的变量进行二次赋值,也就是不能对不可变的变量进行修改。如下:

常量
- 常量(constant)与不可变的变量一样,在绑定值以后也是不可变的。
- 在程序在运行期间,常量在其声明的作用域内一直有效。
需要注意的是,Rust里常量使用全大写字母,每个单词之间用下划线分开。如下:
const MAX_POINTS: u32 = 100_000;
常量与不可变的变量的区别:
- 常量不可以使用mut关键字,因为常量永远都是不可变的。
- 声明常量使用const关键字,并且常量的类型必须被显示标注。
- 常量可以在任何作用域内进行声明,包括全局作用域。
- 常量只能绑定到常量表达式,无法绑定到函数的调用结果或只能在运行时才能计算出的值。
注:可以在数字字面值中插入下划线来增强可读性。
隐藏(Shadowing)
在Rust中,可以使用相同的名字声明新的变量,新的变量会隐藏之前声明的同名变量,在后续的代码中这个变量名代表的就是新的变量。如下:
fn main() {
let x = 10;
let x = x + 1;
println!("x = {}", x); //x = 11
}
此外,使用mut关键字声明变量x也可以达到上述效果。如下:
fn main() {
let mut x = 10;
x = x + 1;
println!("x = {}", x); //x = 11
}
但隐藏和把变量声明为mut是不同的:
- 在第一份代码中,使用let声明的同名新变量是不可变的,而第二份代码中变量x是可变的。
- 对于隐藏来说,使用let声明的同名新变量的类型可以与之前的类型不同。
比较常见的使用场景就是数字字符串解析,隐藏可以让解析后的整型复用之前数字字符串的变量名。如下:
fn main() {
let spaces = " ";
let spaces = spaces.len();
println!("spaces = {}", spaces); //spaces = 4
}
如果Rust没有隐藏这个特性,那么我们就需要重新取一个变量名来避免命名冲突。如下:
fn main() {
let spaces_str = " ";
let spaces_num = spaces_str.len();
println!("spaces_num = {}", spaces_num); //spaces_num = 4
}
数据类型
数据类型
- Rust是静态编程语言,在编译时必须知道所有变量的类型,而基于变量使用的值,编译器通常能够推断出变量的具体类型。
- 如果变量可能的类型比较多,就必须显示标注出变量的类型,否则编译器就会报错。
例如将字符串类型转换成整型的parse方法,就必须添加类型的标注,因为parse方法的解析结果可以是多种数值类型。如下:
fn main() {
let year: u32 = "2023".parse().expect("无法解析为整数类型!"); //显示标注变量类型
println!("year = {}", year); //year = 2023
}
标量类型
标量类型
- 标量类型代表一个单独的值。
- Rust有四种基本的变量类型:整数类型、浮点类型、布尔类型、字符类型。
整数类型
整数类型
Rust中的整数类型如下:
| 长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
说明一下:
- 无符号整数类型以u开头,有符号整数类型以i开头,u或i后面的数字表示整数的长度。
- 有符号整数的取值范围: − 2 n − 1 -2^{n-1} −2n−1 到 2 n − 1 − 1 2^{n-1}-1 2n−1−1,无符号整数的取值范围:0 到 2 n − 1 2^n-1 2n−1 。
isize和usize类型
isize和usize类型的位数由程序运行的计算机的架构所决定:
- 如果是64位计算机,那么isize和usize就相当于i64和u64。
- 如果是32为计算机,那么isize和usize就相当于i32和u32。
注:isize和usize通常用于对集合进行索引操作。
整数字面值
- 除了byte类型外,所有的字面值都允许使用类型后缀。例如57u8。
- 如果不太清楚应该使用哪种类型,可以使用Rust相应的默认类型。
- 整数类型的默认类型就是i32,该类型在大部分情形下都是运算速度最快的,即使是在64位系统中。
整数字面量的表示形式:
| 整数字面量 | 示例 |
|---|---|
| Decimal(十进制) | 98_222 |
| Hex(十六进制) | 0xff |
| Octal(八进制) | 0o77 |
| Binary(二进制) | 0b1111_0000 |
| Byte(单字节字符)(仅限于u8) | b’A’ |
可以尝试将以上示例的值进行打印,结果如下:
fn main() {
let a = 98_222;
let b = 0xff;
let c = 0o77;
let d = 0b1111_0000;
let e = b'A';
let f = 12f64;
println!("a = {}", a); //a = 98222
println!("b = {}", b); //b = 255
println!("c = {}", c); //c = 63
println!("d = {}", d); //d = 240
println!("e = {}", e); //e = 65
}
注:可以在整数字面量中添加下划线来增强可读性。
整数溢出
- 由于整数是保存在内存中一个固定长度的空间的,因此它能存储的最大值和最小值是固定的,如果我们尝试存储一个数,而这个数又大于该整数类型所能存储的最大值,那么就会导致整数溢出。
- 在调试模式下编译,Rust会检查整数溢出,如果发生溢出,程序在运行时就会触发panic;在发布模式下编译,Rust不会检查可能触发panic的整数溢出,而会进行二进制补码环绕。
例如u8类型的范围是0-255,如果将u8变量的值更新为256,那么就会导致整数溢出。如下:
fn main() {
let a: u8 = 255;
let b: u8 = 1;
println!("a = {:?}, b = {:?}", a, b);
println!("a + b = {:?}", a + b); //a + b = 0
}
上述代码在debug模式和release模式下均能成功编译。如下:

由于该代码会导致整数溢出,因此在debug模式生成的可执行程序在运行时会触发panic,而release模式生成的可执行程序会进行二进制补码环绕,使得256变成了0。如下:

浮点类型
浮点类型
- Rust中有两种基础的浮点类型,分别是f32(单精度浮点数)和f64(双精度浮点数)。
- Rust中的浮点数类型采用IEEE-754标准来表述,其中f64是默认的浮点数类型,因为在现代CPU上f64和f32的运行效率差不多,但f64的精度更高。
例如下面声明的x变量默认是f64类型,而y变量则是我们标注的f32类型。如下:
fn main() {
let x = 0.2; //f64
let y: f32 = 0.3; //f32
}
数值运算
对于所有的数值类型,Rust都支持常见的加、减、乘、除、余等数值运算。如下:
fn main() {
let sum = 10 + 20;
let dif = 10.1 - 20.2;
let mul = 10 * 20;
let div = 10.1 / 20.2;
let rem = 10 % 20;
}
布尔类型
布尔类型
Rust中的布尔类型可以是true或false,占据单个字节大小。如下:
fn main() {
let a = true; //bool
let b: bool = false; //bool
}
字符类型
字符类型
- Rust语言中的char类型被用来描述语言中最基础的单个字符,字符类型的字面值使用单引号。
- Rust中的字符类型占用4字节大小,是Unicode标量值,可以表示比ASCII更多的字符内容,比如拼音、中日韩文、emoji表情等。
例如下面的英文字母、中文汉字以及emoji表情都是字符类型。如下:
fn main() {
let x = 'a'; //char
let y: char = 'ℤ'; //char
let z = '😁'; //char
println!("{} {} {}", x, y, z);
}
注:Unicode标量值范围为U+0000到U+D7FF,以及U+E000到U+10FFFF。
复合类型
复合类型
- 复合类型可以将多个不同类型的值组合为一个类型。
- Rust提供了两种内置的复合类型:元组(tuple)、数组(array)。
元组
元组
- 元组可以将多个不同类型的多个值组合进一个复合类型中。
- 元组的长度是固定的,一旦声明就无法改变。
声明元组时将一系列值使用逗号分隔后,放置到一对圆括号中即可。如下:
fn main() {
let tup: (i32, f64, u8) = (32, 6.4, 8);
}
说明一下:
- 声明元组时也可以标注类型,标注时使用一个圆括号,在圆括号中依次标注元组中对应位置的元素类型即可。
- 不带任何值的元组叫做单元(unit)元组,这种值以及对应的类型都写作
(),表示空值或空的返回类型。(如果表达式不返回任何其他值,则会隐式返回单元值)
访问元组元素
访问元组中的元素使用点标记法,在点的后面指明元素的索引号即可。如下:
fn main() {
let tup: (i32, f64, u8) = (32, 6.4, 8);
println!("{} {} {}", tup.0, tup.1, tup.2); //32 6.4 8
}
此外,还可以使用模式匹配对元组进行解构(destructuring),从而获取元组中的元素值。如下:
fn main() {
let tup: (i32, f64, u8) = (32, 6.4, 8);
let (x, y, z) = tup;
println!("x = {}, y = {}, z = {}", x, y, z); //x = 32, y = 6.4, z = 8
}
数组
数组
- 数组也可以将多个值组合在一起,但数组中每个元素的类型必须相同。
- 数组的长度也是固定的,一旦声明就无法改变。
声明元组时将一系列值使用逗号分隔后,放置到一对中括号中即可。如下:
fn main() {
let a = [1, 2, 3, 4, 5];
}
说明一下:
- 数组的类型表示为
[type; len],比如上述代码中数组a的类型为[i32; 5]。
此外,如果数组中每个元素的值相同,那么可以以[val; len]的方式声明数组,表示声明的数组中有len个元素,每个元素的值都是val。如下:
fn main() {
let a = [3; 5]; //等价于let a = [3, 3, 3, 3, 3];
}
访问数组元素
访问数组中的元素使用索引的方式,在中括号中指明元素的索引号即可。如下:
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0]; //1
let second = a[1]; //2
}
访问数组元素时,指明的索引值如果超出了数组的范围。如下:
fn main() {
let a = [1, 2, 3, 4, 5];
let index = 6;
let num = a[index]; //error
println!("num = {}", num);
}
对于上面这种简单的代码逻辑,编译时会检查出越界并产生报错。如下:

但如果让用户输入一个数字,作为访问数组元素时的索引值。如下:
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("请输入一个索引:");
let mut index = String::new();
io::stdin().read_line(&mut index).expect("无法读取行!");
let index: usize = index.trim().parse().expect("无法解析为整数类型!");
let num = a[index];
println!("num = {}", num);
}
那么在编译时是不会产生报错的,因为我们不知道程序运行后用户输入的数字是多少,但在运行程序后如果发现索引值越界,那么就会触发panic。如下:

函数
函数声明
- 声明函数使用fn关键字,fn关键字后面是函数名。
- 函数名后是一个小括号,小括号里面可以声明函数的参数。
- 用一对花括号来标识函数体的开始和结尾。
下面的代码中定义了主函数和一个名为another_function的函数,并在主函数中调用了another_function函数。如下:
fn main() {
println!("main function");
another_function();
}
fn another_function() {
println!("another function");
}
说明一下:
- 在Rust中,函数名和变量名均使用snack case命名规范,即以小写字母命名,多个单词之间使用下划线分开。
- another_function函数的声明不用在main函数之前,只要another_function的定义对于使用区域是可见的即可。
函数参数
- 如果函数有参数,那么在函数签名里必须声明每个参数的类型。
- 函数签名中声明的参数叫做parameter,调用函数时传递的参数叫做argument。
下面给another_function定义了两个参数,并在main函数中对其进行了调用。如下:
fn main() {
another_function(10, 20); //argument
}
fn another_function(x: i32, y: i32) { //parameter
println!("x = {}, y = {}", x, y);
}
语句与表达式
- Rust是一个基于表达式的语言,所以它将语句(statement)与表达式(expression)区别为两个不同的概念。
- 语句是指那些执行操作但不返回值的指令,而表达式则是指会进行计算并产生一个值作为结果的指令。
- 函数体由若干条语句组成,并可以以一个表达式作为结尾。
例如下面声明变量时使用的代码就是一条语句,甚至下面整个例子本身也是一条语句。如下:
fn main() {
let x = 10;
}
由于语句是不会返回值的,因此不能一条语句赋值给另一个变量。如下:
fn main() {
let y = (let x = 10); //error
}
实际我们应该将一个表达式赋值给其他变量,因此编译上述代码你会看到如下报错:

此外,Rust中的代码块也是一个表达式,表达式的值就是代码块中最后一个表达式的值。如下:
fn main() {
let y = {
let x = 1;
x + 3
};
println!("y = {}", y); //y = 4
}
注意:
- 代码中的
x+3后面不能加分号,因为加了分号后x+3;就变成了一个语句,此时该代码块不会返回任何值,或者说代码块返回的是一个单元元组()。
函数返回值
- 在
->符号后面可以声明函数的返回值类型,但是不可以为返回值命名。 - 在Rust中,函数的返回值就是函数体中最后一个表达式的值。
- 可以使用return关键字,并指定一个值来提前从函数中返回。
下面声明了一个plus_five函数,该函数接收一个i32类型的参数,并将该参数的值加5后进行返回。如下:
fn plus_five(val: i32) -> i32 {
val + 5
}
fn main() {
let x = plus_five(10);
println!("x = {}", x); //15
}
注释
注释
Rust中可以通过//和/**/进行单行或多行注释。如下:
/*
这是一个多行注释
...
...
*/
fn main() {
//这是一个多行注释
//...
//...
/*这是一个单行注释*/
println!("Hello World"); //这是一个单行注释
}
注:Rust中还有一种注释叫做文档注释,后续再介绍。
控制流
if表达式
if表达式
- if表达式允许你根据条件来执行不同的代码分支,但注意这个条件必须是bool类型的。
- 在if表达式后面可以追加若干个else if表达式,最后还可以追加一个else表达式。
下面的代码中通过if表达式判断一个分数的等级。如下:
fn main() {
let score = 95;
if score >= 0 && score < 60 {
println!("不及格");
} else if score >= 60 && score < 80{
println!("良好");
} else if score >= 80 && score <= 100{
println!("优秀");
} else {
println!("成绩出错");
}
}
当else if表达式过多时,为了增加代码的可读性,最好使用match表达式对代码进行重构。如下:
fn main() {
let score = 95;
match score {
0..=59 => println!("不及格"),
60..=79 => println!("良好"),
80..=100 => println!("优秀"),
_ => println!("成绩出错"),
}
}
在let语句中使用if
由于if是一个表达式,因此可以将其放在等号右边用于给其他变量赋值。如下:
fn main() {
let cond = true;
let number = if cond { 10 } else { 20 };
println!("number = {}", number); //number = 10
}
注意:
- if表达式后面如果跟有else if表达式或else表达式,那么这些代码块的返回值类型必须相同,因为Rust在编译时必须知道接收if表达式结果的变量的类型。
循环
loop循环
- 使用loop关键字可以让Rust反复执行某一块代码。
- 与其他语言类似,在loop循环中也可以使用continue和break关键字。
- loop循环可以返回值,当使用break关键字跳出循环时,在break后面指明返回值即可。
下面代码中,当counter累加到10时,将counter乘2的值作为loop循环的返回值,并用result变量接收了这个返回值。如下:
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2; //loop循环的返回值
}
};
println!("result = {}", result); //result = 20
}
while循环
- while循环能够在每次执行循环体之前都判断依次条件,如果条件满足则执行循环体。
- 与其他语言类似,在while循环中也可以使用continue和break关键字。
下面代码中,当number的值减为0时便不再执行循环体。如下:
fn main() {
let mut number = 3;
while number != 0 {
println!("{}!", number);
number -= 1;
}
println!("LIFTOFF!!!");
}
for循环
- 使用loop和while可以用来遍历集合,这时需要我们对索引进行控制,比较容易出错并且低效。
- for循环更简洁紧凑,它可以针对集合中的每个元素来执行一些代码。
- for循环的安全性和间接性,使它成为了Rust中最常用的循环结构。
下面使用for循环对数组中的元素进行了一次遍历。如下:
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a.iter() {
println!("value: {}", element);
}
}
说明一下:
- 数组的iter方法会返回该数组的只读迭代器,for循环则是依次获取数组中每个元素的迭代器,然后以借用的方式获取元素的值,使得我们可以通过element在循环体中对数组中的元素进行访问。
此外,for循环可以搭配Range来对某个数字序列进行遍历。如下:文章来源:https://www.toymoban.com/news/detail-715602.html
fn main() {
for number in (1..4).rev() {
println!("{}!", number);
}
println!("LIFTOFF!!!");
}
说明一下:文章来源地址https://www.toymoban.com/news/detail-715602.html
- Range是标准库提供的,用来生成从一个数字开始到另一个数字结束之前的所有数字序列。
- Range中的rev方法可以对Range生成的数字序列进行反转。
到了这里,关于Rust通用编程概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!