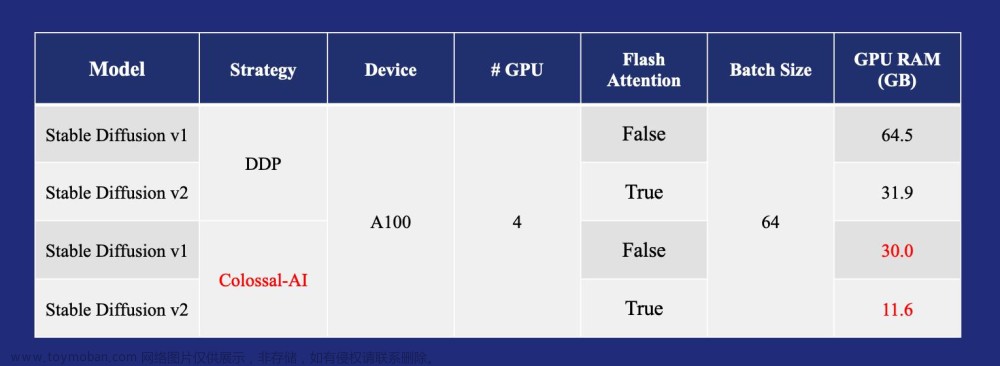
Colossal-AI框架主要特色在于对模型进行并行训练与推理(多GPU),从而提升模型训练效率,可快速实现分布式训练与推理。目前,该框架已集成很多计算机视觉(CV)和自然语言处理(NLP)方向的算法模型,特别是包括GPT和Stable Diffusion等系列大模型的训练和推理。
本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。相关AIGC模型体验会在RdFast小程序中同步上线。文章来源地址https://www.toymoban.com/news/detail-715611.html

1 Colossal-AI安装
Colossal-AI项目地址为“https://github.com/hpcaitech/ColossalAI”。
1.1 环境要求
Colossal-AI环境要求如下,注意CUDA驱动版本应不小于CUDA套件版本,驱动更新请参考博文《Docker AIGC等大模型深度学习环境搭建(完整详细版)》,地址为“https://blog.csdn.net/suiyingy/article/details/130285920”。
PyTorch >= 1.11 (PyTorch 2.x 正在适配中)
Python >= 3.7
CUDA >= 11.0
NVIDIA GPU Compute Capability >= 7.0 (V100/RTX20 and higher)
Linux OS1.2 环境安装
创建一个名称为clai的Python环境(Python3.8),并安装torch 1.12.1。“ -i https://pypi.tuna.tsinghua.edu.cn/simple”表示使用清华镜像进行安装,通常可提高pip install的安装速度。下面示例所使用的是CUDA 11.3版本对应的Pytorch。用户可前往官网选择相应CUDA版本的安装命令,地址为“https://pytorch.org/get-started/previous-versions/”。
conda create -n clai python=3.8
conda activate clai
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 -i https://pypi.tuna.tsinghua.edu.cn/simple1.3 Colossal-AI安装
Colossal-AI可以通过pip install直接安装,例如“pip install colossalai -i https://pypi.tuna.tsinghua.edu.cn/simple”;也可以下载工程后进行编译安装,步骤如下所示:
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install dependency
pip install -r requirements/requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# install colossalai
pip install .2 例程验证
Colossal-AI的教程地址为“https://colossalai.org/docs/get_started/run_demo”,模型示例工程为“https://github.com/hpcaitech/ColossalAI-Examples”。示例工程安装步骤如下所示:
git clone https://github.com/hpcaitech/ColossalAI-Examples.git
cd ColossalAI-Examples
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple2.1 ResNet模型训练
ResNet模型位于ColossalAI-Examples/image/resnet,进入该文件夹下运行如下命令即可开始训练。
cd image/resnet/
# with engine
colossalai run --nproc_per_node 1 train.py
# with trainer
colossalai run --nproc_per_node 1 train.py --use_trainer 
程序会默认自动下载CIFAR10手写数字数据集到当前文件夹下的data文件夹,并基于该数据集进行模型训练。如果系统中设置了DATA环境变量,那么数据集将下载至DATA指定目录。
export DATA=/path/to/data
DATA_ROOT = Path(os.environ.get('DATA', './data')) 
参数nproc_per_node用于设置GPU的数量,并且可在config.py文件中修改学习率和batch size,通常学习率和batch size的比值保持固定。
new_global_batch_size / new_learning_rate = old_global_batch_size / old_learning rate
如果训练过程报错“ModuleNotFoundError: No module named 'colossalai._analyzer'”,其解决方式为“cp -r _analyzer/ /path/to/site-packages/colossalai/”,例如“cp -r _analyzer ~/miniconda3/envs/clai/lib/python3.8/site-packages/colossalai/_analyzer”,具体可参考“https://github.com/hpcaitech/ColossalAI/issues/3540”。文章来源:https://www.toymoban.com/news/detail-715611.html
本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。相关AIGC模型体验会在RdFast小程序中同步上线。
到了这里,关于GPT系列训练与部署——Colossal-AI环境配置与测试验证的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!