一、Gridworld
Gridworld是一个用于教授强化学习概念的简化的电子游戏环境。它具有一个简单的二维网格,智能体可以在其中执行动作并获得奖励。这个环境是有限的,因为它有一个明确的开始和结束状态,以及一组确定的动作和奖励。
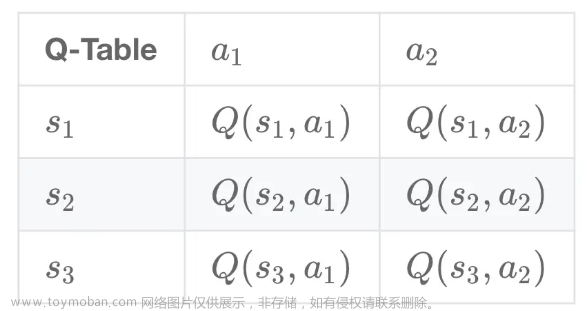
在Gridworld中,每个单元格代表一个状态,智能体可以在该状态执行四个可能的动作:向北、向南、向东或向西移动一个单元格。如果智能体执行的动作将它们移动到网格之外,它们的位置将保持不变,但它们将获得一个奖励1。另一方面,如果智能体从特殊状态A或B开始执行动作,它们将获得不同的奖励。
从状态A开始,智能体执行的动作将使它们获得奖励+10,并将它们移动到A0单元格。类似地,从状态B开始,智能体执行的动作将使它们获得奖励+5,并将它们移动到B0单元格。
通过这个简单的环境,学生可以学习强化学习的基本概念,如值函数、策略和最优解。此外,Gridworld还提供了用于评估和比较不同策略的工具,使学生能够更好地理解这些概念并应用它们来解决实际问题。
在Gridworld图1中,使用了一个矩形网格来描绘一个简单的有限MDP(马尔可夫决策过程)的值函数。网格的每个单元格都对应于环境的一个状态。在每个单元格,有四个可能的动作:北、南、东、西,这些动作将确定性地将智能体移动到相应方向的一个单元格。如果动作会使智能体离开网格,那么其位置将保持不变,但也会获得一个奖励1。其他动作的奖励为0,除非它们将智能体从特殊状态A和B中移出。从状态A开始,所有四个动作都会产生奖励+10并将智能体移动到A0。从状态B开始,所有动作都会产生奖励+5并将智能体移动到B0。

图1
假设智能体在所有状态下以相等的概率选择所有四个动作。图b显示了对于这个策略的值函数vπ,对于带折扣的奖励情况,折扣因子γ = 0.9。该值函数是通过求解方程计算得出的。请注意,靠近下边缘的负值是由于在该随机策略下,那里有很大可能性会撞到网格的边缘。状态A在该策略下是最好的状态,但其期望回报小于10,即其即时奖励,因为从A状态开始,智能体将被带到A0状态,从那里很可能会撞到网格的边缘。另一方面,状态B的估值超过5,即其即时奖励,因为从B状态开始,智能体将被带到B0状态,该状态具有正价值。从B0状态开始,由于可能撞到边缘而产生的预期惩罚(负奖励)超过了因可能撞到A或B而产生的预期收益。
二、高尔夫
将打高尔夫球的过程表述为强化学习任务,我们会对每一击都施加一个惩罚(负面奖励),直到球进入洞中。状态为球的位置,一个状态的价值是,从此位置到球洞的击球次数。我们的行动是针对如何瞄准和挥动球杆的动作,当然,还包括选择哪种球杆。让我们假设这些都是给定的,只需要考虑球杆的选择,我们假设只能是推杆或驱动器。图2的上半部分显示了对于始终使用推杆的策略可能的状态值函数vputt(s)。在洞中的终端状态的价值为0。我们假设无论在球场的哪个位置,我们都可以推杆;这些状态的价值为e1。如果我们在绿地之外的位置,就无法通过推杆到达洞穴,因此其价值更大。如果我们可以通过推杆从某个状态到达绿地,那么该状态的价值必须比绿地的价值少1,即2。为了简化问题,我们假设可以非常精确和确定性地进行推杆,但范围有限。这给我们提供了图中标记为d2的尖锐等高线;位于该线与绿地之间的所有位置都需要恰好两次击球来完成这个洞。同样地,位于e2等高线以内的任何位置都必须具有价值3,依此类推,得到图中所示的所有等高线。推杆无法让我们从沙陷阱中脱身,因此沙陷阱的价值为负无穷大。总体而言,我们需要六次击球才能从发球台到达洞穴。
 文章来源:https://www.toymoban.com/news/detail-715617.html
文章来源:https://www.toymoban.com/news/detail-715617.html
图2文章来源地址https://www.toymoban.com/news/detail-715617.html
到了这里,关于强化学习中值函数应用示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!