PillarNeXt
PillarNeXt: Rethinking Network Designs for 3D Object Detection in LiDAR Point Clouds
基于LiDAR点云的3D目标检测网络设计
论文网址:PillarNeXt
代码:PillarNeXt
论文简读
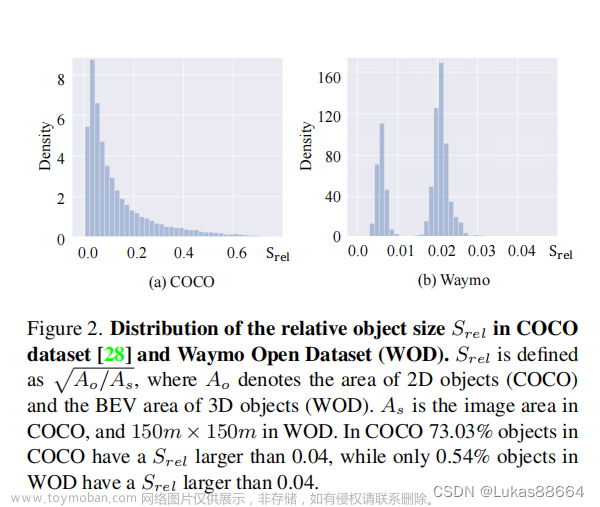
![[论文阅读]PillarNeXt——基于LiDAR点云的3D目标检测网络设计,基于点云的三维目标检测,论文阅读,3d,目标检测,人工智能,深度学习,计算机视觉](https://imgs.yssmx.com/Uploads/2023/10/715798-1.png)
这篇论文"PillarNeXt: Rethinking Network Designs for 3D Object Detection in LiDAR Point Clouds"重新思考了用于激光雷达点云3D目标检测的网络设计。主要的贡献如下:
-
从计算预算的角度比较了不同的局部点聚合器(pillar, voxel, multi-view fusion),发现简单的pillar聚合器在准确率和推理速度上都优于voxel和multi-view fusion。这挑战了一般认为需要更细粒度的局部几何建模的想法。
-
借鉴2D目标检测的成功经验,发现适当增大感受野对3D目标检测非常重要,基于单尺度特征而不是多尺度特征聚合可以获得更好的性能。这表明3D目标检测可以很好地继承2D域的成功实践。
-
在两个大规模基准测试上,作者提出的简单有效的pillar网络PillarNeXt取得了state-of-the-art的结果。作者还开发了不同的模型权衡检测精度和推理速度。
方法概览:
-
比较了pillar, voxel, multi-view fusion三种点云编码方式,发现pillar编码器在类似计算预算下性能优异。
-
采用了ASPP模块增大感受野,取代了多尺度特征融合。ASPP模块的主要目的是在不引入额外参数和计算复杂度的情况下,增加网络对不同尺度信息的感知能力。它通过在不同的空洞率下应用卷积操作来实现这一目标。空洞率(也称为扩张率)决定了卷积核在输入特征图上的采样间隔。通过使用不同空洞率的卷积核,ASPP模块可以获取不同尺度的感受野。具体来说,ASPP模块由多个并行的卷积分支组成,每个分支使用不同的空洞率。这些分支的输出特征图被级联在一起,并通过适当的池化操作进行融合。这样,ASPP模块可以捕捉到不同尺度的上下文信息,从而提高目标检测的准确性。
-
借鉴CenterPoint,使用中心预测代替anchor,并进行了预测头的优化。
-
在Waymo和nuScenes数据集上,该方法在精度和速度上都优于复杂的方法。
总结:
- pillar编码器在适当的训练下可以达到与voxel编码器可比的精度
- 增大感受野比多尺度特征更重要
- 3D目标检测可以继承2D目标检测的成功设计
- 简单有效的PillarNeXt网络取得了state-of-the-art的结果
该工作的发现可为点云3D目标检测研究提供实用且有效的baseline。
摘要
为了处理稀疏且非结构化的原始点云,基于 LiDAR 的 3D 目标检测研究主要集中于设计用于细粒度几何建模的专用局部点聚合器。本文从分配计算资源的角度重新审视本地点聚合器。发现,考虑到准确性和延迟,最简单的基于Pillars的模型表现得非常好。此外,本文还表明,二维目标检测的成功所带来的最小调整(例如扩大感受野)可以显着提高性能。大量的实验表明,本文的基于pillars的网络在架构和训练方面具有现代化的设计,在两个流行的基准测试上呈现出最先进的性能:Waymo 和 nuScenes 开放数据集。本文的结果挑战了人们的普遍直觉,即详细的几何建模对于实现 3D 物体检测的高性能至关重要。
引言
LiDAR 点云中的 3D 目标检测是自动驾驶系统中的一项重要任务,因为它为后续的车载模块提供了关键信息,包括感知 [Exploring simple 3d multi-object tracking for autonomous driving-2021, Selfsupervised pillar motion learning for autonomous driving-2021]、预测和规划。人们在开发专门用于处理该领域点云的复杂网络方面进行了广泛的研究工作[ PointPillars, PillarNet, PV-RCNN++, Pillar-based object detection for autonomous driving, VoxelNet]。
由于点云的稀疏性和不规则性,大多数现有工作采用基于网格的方法,将点云转换为规则网格,例如Pillars[PointPillars],体素[VoxelNet]和范围视图[LaserNet],使得规则算子可以应用。然而,人们普遍认为基于网格的方法(尤其是Pillars)不可避免地会导致信息丢失,从而导致结果较差,特别是对于小物体(例如行人)。最近的研究[PV-RCNN++]提出了细粒度几何建模的混合设计,以结合基于点和网格的表示。本文将上述所有运算符命名为局部点聚合器,因为它们的目的是聚合某个邻域中的点特征。本文观察到,当前 3D 目标检测的主流是为点云开发更专业的算子,而网络架构几乎未被探索。大多数现有作品仍然建立在 SECOND 或 PointPillars 的原始架构之上,缺乏现代化的设计。
与此同时,在一个密切相关的领域,图像中的二维目标检测取得了显著的进步,这在很大程度上归功于架构和训练的进步。其中,强大的主干(例如,ResNet 和 Swin Transformers )、有效的颈部(例如,BiFPN 和 YOLOF )以及改进的训练(例如,bag of freebies [YOLOv4, Bag of freebies for training object detection neural networks])尤其值得注意。因此,2D目标检测的研究重点与3D目标检测的研究重点有很大不同。
根据上述观察,本文重新思考 LiDAR 点云中 3D 目标检测的重点应该是什么。具体来说,重新审视设计 3D 目标检测模型时的两个基本问题:本地点聚合器和网络架构。
首先,本文从一个新的角度(即计算成本)比较局部点聚合器。细粒度聚合器通常比粗粒度聚合器需要更广泛的计算资源。例如,基于Voxel的聚合器采用 3D 卷积,这需要更多的网络参数,并且运行速度比 2D 卷积慢得多。这就提出了如何有效分配计算预算或网络容量的问题。研究者们应该将资源花在细粒度结构上还是将它们分配给粗网格?令人惊讶的是,当在可比预算和增强策略下进行训练时,更简单的基于Pillars的模型可以实现优于基于Voxel的模型或同等的性能,即使对于行人等小物体也是如此,同时显著优于基于体素的模型。基于多视图融合的模型。这对实际性能增益和细粒度局部 3D 结构的必要性提出了挑战。本文的发现也与一般点云分析中的最新工作[ A closer look at local aggregation operators in point cloud analysis-2020, PointNeXt]一致,表明不同的本地点聚合器在强大的网络下表现相似。
其次,对于网络架构,本文的目的并不是为点云提出任何特定领域的设计,相反,本文对 2D 目标检测的成功进行了最小程度的调整,并表明它们优于大多数具有点云专用架构的现有网络。例如,一项重要发现是,适当扩大感受野可以带来显著的改善。与之前依赖多尺度特征融合的研究[PillarNet, VoxelNet]不同,本文表明,具有足够感受野的最后阶段的单一尺度可以获得更好的性能。这些有希望的结果表明 3D 目标检测可以继承 2D 领域成熟的成功实践。
利用上述发现,本文提出了一个基于Pillars的网络,称为 PillarNeXt,它在两个流行的基准测试上取得了最先进的结果。本文的方法简单而有效,并且具有很强的可扩展性和通用性。通过调整网络参数的数量,开发了一系列在检测精度和推理延迟之间进行不同权衡的网络,这些网络可用于自动驾驶中的车载和车外应用。
本文的主要贡献可总结如下。
(1)据本文所知,这是第一个从计算预算分配的角度比较不同局部点聚合器(Pillars、体素和多视图融合)的工作。本文的研究结果挑战了普遍的看法,表明与体素相比,Pillar 可以实现更好的 3D mAP 和更好的鸟瞰 (BEV) mAP,并且在 3D 和 BEV mAP 方面都远远优于多视图融合。
(2)受2D目标检测成功的启发,发现扩大感受野对于3D目标检测至关重要。通过最小的调整,本文的探测器通过复杂的点云设计超越了现有的方法。
(3) 经过适当训练的网络在两个大型基准测试中取得了优异的结果。
相关工作
LiDAR based 3D Object Detection. : 根据局部点聚合器,现有方法可以大致分为基于点、Voxel和混合的表示。作为一种基于点的方法,PointRCNN 使用 [PointNet++] 生成提案,然后通过 RoI 池化细化每个提案。然而,在此类方法中进行邻近点聚合的成本极其昂贵,因此它们不适合在自动驾驶中处理大规模点云。另一方面,基于Voxel的方法将点云离散化为结构化网格,其中可以应用 2D 或 3D 卷积。在 VoxelNet 中将 3D 空间划分为体素,并聚合每个体素内的点特征,然后使用密集 3D 卷积进行上下文建模。 SECOND通过引入稀疏 3D 卷积来提高效率。 PointPillars 将点云组织为垂直列并采用 2D 卷积。另一种基于网格的表示是范围视图 [LaserNet],它也可以通过 2D 卷积进行有效处理。多视图融合方法 [Pillar-based object detection for autonomous driving , End-to-end multi-view fusion for 3D object detection in LiDAR point clouds] 利用基于Pillars/体素和范围视图的表示。
尽管效率很高,但人们普遍直观地认为基于网格的方法会导致细粒度的信息丢失。因此,提出了混合方法将点特征合并到网格表示中[PVNAS, PV-RCNN]。在这项工作中,转而关注基本网络架构和相关训练,并表明细粒度局部几何建模被高估了。
Feature Fusion and Receptive Field. : 多尺度特征融合从特征金字塔网络(FPN)开始,以自上而下的方式聚合层次特征。它广泛用于 2D 目标检测,将高级语义与低级空间线索相结合。在[Path aggregation network for instance segmentation]中,PANet进一步指出自下而上的融合也很重要。两者都是通过直接将特征图相加来进行融合。 BiFPN表明不同尺度的特征贡献不均,并采用可学习的权重来调整重要性。感受野作为特征融合的一个相互关联的因素,在二维检测和分割中也得到了广泛的研究和验证。在[DeepLab]中,提出了空洞空间金字塔池化(ASPP)来对具有多个有效感受野的特征进行采样。 TridentNet 应用三个具有不同膨胀因子的卷积来使感受野范围与对象尺度范围相匹配。 YOLOF中也引入了类似的策略,采用扩张残差块来扩大感受野,同时保持原始感受野。
尽管这些关于特征融合和感受野的技术已在 2D 领域得到广泛采用,但在 3D 领域却很少讨论。该领域现有的大多数网络仍然遵循或基于VoxelNet的架构进行修改。在这项工作中,目标是将最新的设计集成到 3D 目标检测网络中。
Model Scaling. : 这方面在图像领域已经得到了很好的研究,包括分类、检测和分割任务。据观察,联合增加深度、宽度和分辨率可以提高精度。EfficientNet提出了一种用于分类的复合缩放规则,该规则后来扩展到目标检测[Fast and accurate model scaling, EfficientDet]。人们普遍认为模型容量影响模型性能。因此,不同方法的比较应在考虑模型容量的情况下才能得到合理的结论。
据我们所知,只有一项工作 [Cost-aware comparison of lidar-based 3D object detectors] 研究 3D 目标检测中的模型缩放。它缩放 SECOND 的深度、宽度和分辨率,以找出每个组件的重要性。然而,它只关注单一类型的模型,而本文在各种模型规模的相似计算预算下系统地比较不同的局部点聚合器。
Network Architecture Overview
网络架构概述
由于运行时效率和接近 2D 目标检测,本文专注于基于网格的模型。通常,基于网格的网络由以下部分组成:(i)网格编码器,用于将原始点云转换为结构化特征图,(ii)用于一般特征提取的主干,(iii)用于多尺度特征融合的颈部,以及(iv)用于特定任务输出的检测头。现有网络通常将所有这些组件耦合在一起。在本节中,将它们解耦并简要回顾每个部分
Grid Encoder
网格编码器
网格编码器用于将点云离散化为结构化网格,然后将每个网格内的点转换并聚合为初步特征表示。在这项工作中,针对以下三种网格编码器。
- Pillar:基于Pillar的网格编码器将点排列在垂直列中,并应用多层感知器(MLP),然后进行最大池化来提取柱特征,这些特征表示为伪图像[PointPillars]。
- Voxel:与Pillar类似,基于体素的网格编码器组织体素中的点并获得相应的特征[VoxelNet]。与Pillar相比,体素编码器保留了沿高度维度的细节。
- Multi-View Fusion (MVF):基于 MVF 的网格编码器结合了Pillar/Voxel和基于范围视图的表示。在这里,按照[Pillar-based object detection for autonomous driving]将柱Pillar编码器与基于柱面视图的编码器结合起来,该编码器将柱坐标中的点分组。
Backbone and Neck
骨干和颈部
主干网根据网格编码器提取的初步特征执行进一步的特征抽象。为了公平比较,使用 ResNet-18 作为主干,因为它在之前的作品中常用[PillarNet]。具体来说,在主干中使用基于Pillar或 MVF 的编码器的稀疏 2D 卷积,并在主干中使用基于体素的编码器的稀疏 3D 卷积。然后可以利用颈部聚合来自主干的特征,以扩大感受野并融合多尺度上下文。然而,与图像相比,如何设计有效的颈部来进行点云中的目标检测还没有得到很好的探索。本文的目标是通过将 2D 目标检测中的先进颈部设计集成到模型中来缩小这一差距,例如使用改进的多级特征融合的 BiFPN 或在单个特征级别上使用具有多个扩张率的卷积的 ASPP 3D 目标检测的架构。
Detection Head
检测头
在 SECOND 和 PointPillars 的开创性工作中,采用基于锚的检测头来预先定义头部输入特征图上每个位置的轴对齐锚。 CenterPoint 通过其中心点来表示每个对象,并预测中心热图,其中在每个中心位置实现边界框的回归。由于其简单性和卓越的性能,本文在所有网络中均采用基于中心的检测头。本文在 head 中展示了一组简单的修改,例如特征上采样、多分组和 IoU 分支,显著提高了性能。文章来源:https://www.toymoban.com/news/detail-715798.html
结论
本文挑战了高性能 3D 目标检测模型需要细粒度局部几何建模的普遍看法。系统地研究了三个局部点聚合器,发现具有增强策略的最简单的Pillar编码器在准确性和延迟方面表现最好。证明扩大感受野和操纵分辨率起着关键作用。文章来源地址https://www.toymoban.com/news/detail-715798.html
到了这里,关于[论文阅读]PillarNeXt——基于LiDAR点云的3D目标检测网络设计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文阅读]H3DNet——基于混合几何基元的3D目标检测](https://imgs.yssmx.com/Uploads/2024/02/725646-1.png)
![[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测](https://imgs.yssmx.com/Uploads/2024/02/731110-1.png)
![[arxiv论文阅读] LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding](https://imgs.yssmx.com/Uploads/2024/02/785864-1.png)

![[论文阅读]MV3D——用于自动驾驶的多视角3D目标检测网络](https://imgs.yssmx.com/Uploads/2024/02/721503-1.png)