背景
近两个月转到了计算引擎领域, 为公司开发兼容PG的新的向量化计算引擎, 所以一直处于高强度的学习以及开发过程,也没有来得及做一些总结.
之前的背景都是存储, 包括NoSQL存储(Rocksdb/FoundationDB)以及做了一年半的数据库内核存储(PostgreSQL), 这个过程对于存储相关的知识也有了较为系统的积累并且对相关的工业界产品也有了一些全新的理解.
公司内部转到计算引擎的背景还是起源于 解决PostgreSQL JIT 内存上涨问题以及 修复 GreenPlum JIT bug时的一些计算相关的探索, 发现计算领域更为抽象, 要解决的问题也更为有趣且通用. 而且公司内部也提供了这样兴趣驱动的机会,所以毅然投入到了数据库领域中又一个新的领域 查询执行(计算引擎). 当然, 查询优化则更为抽象、更独立. 按照个人的规划, 在当下的计算引擎的项目未完全落地前并不会考虑新的方向了.
目前公司做的产品方向也是跟随主流的数据库发展方向: 分析型数据库. 当然查询执行器也是需要支持分析型的计算引擎. 这个过程的本质是在列存储的存储格式上尽可能高效得完成数据分析, AP场景对数据的操作更多得是 AGG(聚合操作: sum/count/avg等等). 这样的一个计算引擎涉及到的技术栈主要包括:
- 向量化. 对于单次 数据处理尽可能得利用CPU缓存 进行批量操作, 这里面会需要列存 、 Push 形态的执行器 以及 SIMD 架构的支持 来达成全链路向量化节点操作的目的.
- Pipeline 调度. 这里面涉及对向量化 计算节点的调度,如何让每一个节点之间执行连路上的多线程调度更为高效合理, 更能利用好CPU.
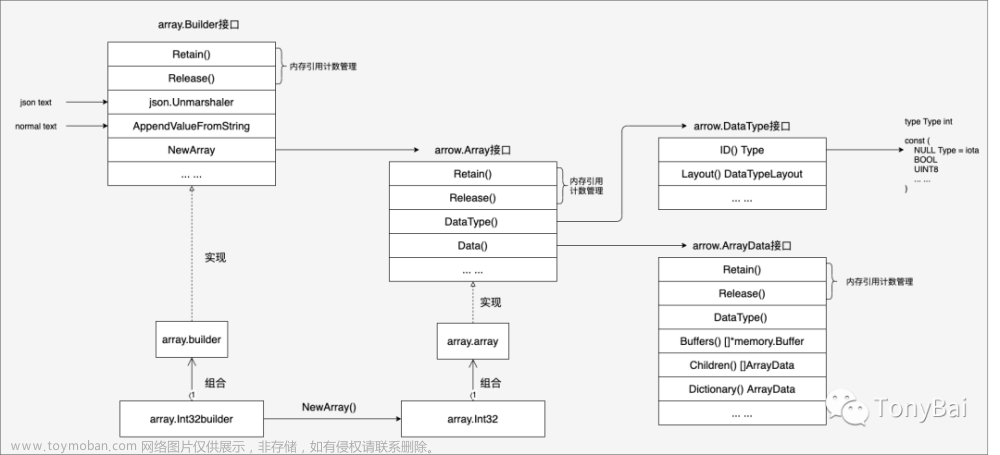
- 数据的组织管理. 数据库系统为了支持多种多样的查询场景,也支持了各种各样的数据类型,包括:int8/int16/int32/int64/uint/char/vary-char/fixed-char/binary/decimal… 不乏很多复杂类型数据的处理:比如decimal, 这一些数据如何用一套足够抽象且拥有高度可扩展性的类型系统来管理起来是一个复杂工程. 当然, 业界已经有足够多的工业级系统落地了这一些(arrow/velox/duckdb…)
- JIT (Just In-Time Compilation) 能够利用编译器的能力多消耗一些CPU 来 完成 query 表达式的执行做更进一步得分支裁剪和常量折叠等优化, 进一步提升查询性能.
- 资源管理以及可观测性.包括对执行过程中的计算、内存资源的 query级别的管理(线程池、内存池) 以及 执行链路的metrics和trace等可观测性能力的建设.
最主要的是如果要在一个成熟的TP系统支持一个AP的计算引擎, 意味着这个全新的 AP 引擎需要兼容所有的TP语法,这个工作量以及工业细节可就多了,当然这个过程也会非常得有趣.
本文将以 PostgreSQL 执行器中的 HashJoin 实现 以及 Arrow Acero执行器的HashJoin 实现为基础做一个 Pull 和 Push 两种执行器的差异分享.
Arrow 的作者Wes McKinney 对计算领域可以说是有前瞻性的眼光, 在pandas 作为开源型公益项目成为数据分析领域的明珠之后为了解决pandas 遇到的一些问题而和 parquet 相关的创始人一起开发了新的项目 Arrow, 而Arrow不仅完美得解决了 pandas遇到的所有的问题之后还有余力即将成为计算平台的标准. 按照目前Arrow 在计算领域的发展趋势, Wes 相信 "Future is arrow-native"的. Wes 作为Pandas/Arrow/Ibis 的创始人, 分享了很多对计算领域的深刻见解, 后续有机会会统一分享一下.
本文涉及到的相关源代码是:
PostgreSQL –REL_12_STABLE, Arrow –apache-arrow-12.0.1
PostgreSQL HashJoin实现
HashJoin 是 数据库执行引擎中 除了 AGG 算子之外最为通用的Join算子中的一种,其主要的应用场景是数据集较小等值链接.连接操作也是关系代数中的基本操作, 能够对两个数据集合按照连接类型(left outer/right outer/full outer/ innner/ semi/anti等)输出新的数据集合.
比如: select a,b from t1,t2 where t1.a=t2.b;
当然对于如上 query, 如果数据集较小且有序则planner可能会生成 merge-join的plan,因为 HashJoin 需要建hash表做hash探查, 而hash表是内存访问效率较高的一种场景,所以其最优的应用场景应该是无序数据集较小的情况.
PG 是成熟的工业级 TP数据库, 其hashjoin 的实现也会考虑 spill的情况(数据集远超内存时的需要考虑对hashjoin 过程中的临时数据落盘的操作), PG的 hashjoin实现采用的 Hybrid HashJoin.
PG 执行器架构
PG 的执行器架构是标准的火山模型(pull), 数据流的驱动方式是自顶向下的.

图中的motion节点是greenplum 做mpp分布式执行引擎时为了做数据传递而创建的一个新的节点.
最上层的节点是 hashjoin, 其要获取数据,则会调用 getnext函数从下游节点拉数据, 下游节点的Hash节点或者motion节点则会继续调用自己的下游节点拉取数据,最后直到Scan节点 通过tableam 读取实际的heap表数据返回给上游.
整个 pull 模型采用的是 once-a-tuple, 每次上游节点调用getnext时仅会返回一个tuple.
这个模型的优势:
- 应用场景更通用. 不受数据规模的限制, 每次在执行器链路的数据传递仅有一个tuple, 这样不论什么规模的数据集都可以被pull模型调度.
- 应用场景更灵活. 数据量的输出可控, 比如常用的limit节点, 获取到了足够的数据之后可以停止从下游节点拉取数据.(push模型就做不到这一点, 控制不了数据的传递)
当然也有很多不足:
- 阻塞节点对资源的消耗较大.比如 hashjoin 需要等待下层内表节点的所有数据都输入完并完成hash表的建立才能通过外表输出对应的结果. 再比如 sort节点,需要读取下游节点的所有数据进行内存排序或者外存排序之后才能输出一条数据到上游. 这种过程都需要消耗大量的系统资源.
- 函数调用开销较大以及缓存失效严重. 每条元组在节点之间流动的过程中都会涉及 大量的函数调用, 数据规模较大时则会有显著的开销,并且导致大量的缓存失效, 从而对性能有较大的影响.
这一些不足则可以被 Push 模型的执行器解决, 但push模型也会缺乏 Pull 模型具有的优势.
HashJoin 基本流程
PG 的 HashJoin 是基于以上 Push 模型实现, 采用的是Hybrid HashJoin(考虑spill的情况下 只需要一次对外表的扫描). 基本流程如下:
- 将数据集较小的table planner会设置其为 inner-table, 用于构建内存的hash表(目的是为了减少内层循环的次数).
- 数据集较大的 table planner 会设置其为 outer-table, 用于probe inner table的hash表,确认是否match 来决定当前行是否需要被输出.
对于小表 R(被选择为inner table 构建hash表) 和大表 S (被选择为 outter table做hash 探查), 整个HashJoin的执行流程分为如 数据集的划分 以及 数据集的分批处理 两个阶段.
数据集的划分 流程如下:

主要做了两件事情
- Scan R表, 并按照 Hash 函数划分为 n 个小表, 每一个小表期望可以独立装入内存. 保留 R1 到内存并构建hash表, R2-Rn 则落盘 形成 BufFiles.
- 同样的 Hash 函数划分 S 表 为 n 个小表, 对于 S1 的 tuple 则开始和 R1 进行match匹配, 匹配成功则进行后续project/filter 操作输出. S表剩下的 S2-Sn 写入存储于磁盘的 BufFiles 中.
数据集的分批处理 流程是分批处理除了 R1,S1之外的其他被spill 的表数据:

- 读取文件(i>=2) Ri 到内存,并选择hash函数构建其hash表
- 遍历文件(i>=2) Si 中的元组, 并 probe Ri, 如果匹配则继续后续的元组处理并输出
- 清空hash表, i++, 重复1,2 步骤.
HashJoin 实现细节
PG 的执行器对 PlanState 计划树的初始化、执行、终止 分别采用的是 ExecInitNode, ExecProcNode 以及 ExecEndNode. 这三个入口会根据算子节点的类型分别调用对应算子的操作函数, 比如算子类型是 T_HashJoin, 则会调用 ExecInitHashJoin,ExecHashJoin,ExecEndHashJoin.
-
ExecInitHashJoin被用于初始化一些数据结构, 比如 joinqual 表达式列表/targetlist 列表/hashqual 列表; 还有保存输出tuple 以及 nulltuple 的数据结构. -
ExecHashJoin维护了六种状态的状态机用来实现 hybrid hashjoin. -
ExecEndHashJoin释放hash表 以及 清理临时的 BufFiles.
我们重点关注的是 ExecHashJoin, 这是 hashjoin 算法实现 数据集的划分 以及 数据集的分批处理 两个阶段的主要逻辑.
Join 类型
详细介绍具体的两个阶段实现之前需要对 join 这个关系代数操作的一些类型有一些基本的理解, 才能理解HashJoin中一些 代码的具体作用对象.
如下两个表:
test=# select * from a;
c1 | c2
----+----
1 | 2
9 | 8
6 | 5
4 | 7
(4 rows)
test=# select * from b;
c1 | c2
----+----
2 | 1
8 | 9
7 | 4
6 | 5
1 | 9
(5 rows)
下文提到的左右表可以理解为
inner table和outer table, PG 实际执行之前通过 planner 会将 构建hash表代价较小的表设置为inner table并对应 righttree,outer table设置为outer table并对应 lefttree.
- JOIN_INNER, 仅输出左右表匹配的元组:
test=# select * from a inner join b on a.c1=b.c2;
c1 | c2 | c1 | c2
----+----+----+----
1 | 2 | 2 | 1
9 | 8 | 1 | 9
9 | 8 | 8 | 9
4 | 7 | 7 | 4
(4 rows)
- JOIN_LEFT, 输出左右表匹配的元组 以及 左表(outer table)不匹配的元组. 即输出左表所有的数据, 右表不匹配的行则输出null.
test=# select * from a left outer join b on a.c1=b.c2;
c1 | c2 | c1 | c2
----+----+----+----
1 | 2 | 2 | 1
9 | 8 | 1 | 9
9 | 8 | 8 | 9
6 | 5 | |
4 | 7 | 7 | 4
(5 rows)
- JOIN_RIGHT, 输出右表所有的数据, 左表不匹配的行则输出null.
test=# select * from a right outer join b on a.c1=b.c2;
c1 | c2 | c1 | c2
----+----+----+----
1 | 2 | 2 | 1
9 | 8 | 8 | 9
4 | 7 | 7 | 4
| | 6 | 5
9 | 8 | 1 | 9
(5 rows)
- JOIN_FULL, 输出左右表所有的数据, 不匹配的行各自输出null.
test=# select * from a full outer join b on a.c1=b.c2;
c1 | c2 | c1 | c2
----+----+----+----
1 | 2 | 2 | 1
9 | 8 | 1 | 9
9 | 8 | 8 | 9
6 | 5 | |
4 | 7 | 7 | 4
| | 6 | 5
(6 rows)
- JOIN_SEMI, 左右表匹配的元组中仅输出左表的元组.
test=# select * from a where exists (select 1 from b where a.c1=b.c2);
c1 | c2
----+----
1 | 2
9 | 8
4 | 7
(3 rows)
- JOIN_ANTI, 左右表不匹配的元组中仅输出左表的元组.
test=# select * from a where not exists (select 1 from b where b.c2=a.c1);
c1 | c2
----+----
6 | 5
(1 row)
PG 其实还有一些执行器内部使用的连接类型,JOIN_UNIQUE_OUTER 和 JOIN_UNIQUE_INNER 用于约束连接之后输出的结果需要unique.
HashJoin 的划分阶段
在了解了基本的连接类型之后, 我们接下来看看代码细节.
划分阶段主要涉及到的状态有下面几个:
1.HJ_BUILD_HASHTABLE 这个是处理 划分阶段中的 inner table R 的划分,保存 R 表的第一个batch构建的 hash表到内存中, R表的其他batch 则会被写入到内存中.
主要涉及到的函数是 ExecHashTableCreate 创建hash表初始数据结构 以及 MultiExecHash 调度getnext 处理innertable的数据, 并进行hash表数据的插入以及超限之后的spill.
PG 在hash表这里采用了比较标准 线性hash的实现, 并没有采用 dynamic_hash, 原因是 执行器的算子的内存大小其实是需要被控制的, 也就是构建hash表消耗的内存在初始化hash表的时候基本就知道了(work_mem相关的guc), 这样就能根据已知的内存大小预分批好足量的bucket, 并没有动态扩容的需求, 性能其实也就用标准的hash表实现就好了.
ExecHashTableCreate 中, 通过 ExecChooseHashTableSize 根据用户配置的 work_mem 计算 inner table构建hash表时需要分配的buckets 的个数以及 最后整个inner table需要被拆分成多少个 batch(或者说 BufFiles).
tupsize = HJTUPLE_OVERHEAD +
MAXALIGN(SizeofMinimalTupleHeader) +
MAXALIGN(tupwidth);
// 内表总共需要的内存大小
inner_rel_bytes = ntuples * tupsize;
// 当前算子允许分配的最大的内存
hash_table_bytes = work_mem * 1024L;
默认配置的 work_mem 是1024, 也就是1M, 也就约束了当前 HashJoin 内存hash表的大小是1M.
buckets 以及 dbbatch 的大小其实也比较简单, buckets个数的量级是 hash_table_bytes / tupsize, 只是 pg用了很多逻辑用来约束这个数值,不想太大,也不想太小; 同理 dbbatch 大小量级也是 inner_rel_bytes/hash_table_bytes.
还有一个需要关注的逻辑就是 在ExecHashTableCreate中也会通过 get_op_hash_functions 函数设置 inner-table和outer-table的 hash函数, 如果左右表的hash-cond 返回值类型一样, 则会用相同的hash函数, 否则会根据各自的hash-key的类型选择对应的hash函数.
接下来就是通过 MultiExecHash --> MultiExecPrivateHash 进行 inner table 数据插入 hashtable 的逻辑了, 其中需要关注的逻辑有两个方面:
- 对skewbucket 的处理.
- 非skewbucket 下如何判断需要spill.
SkewBucket 用于优化数据偏斜的场景, 如果 hashkey数据 经过 distinct 之后仅剩下极少的几个,这样的tuple PG中称其为MCV (most common value), 这种情况则说明这个 hashkey有大量的重复数据,这个时候如果还是用原本的逻辑则会有部分bucket的数据集极多.且因为 会有spill的情况, 这样针对这种skew-bucket会需要大量的io操作. 所以 PG 为这一些hashkey 分配了单独的 bucket 并保证这一些buckets 一定是处于第一个batch, 这样就只会被扫描一次而不用反复得从磁盘加载. 这个过程是在前面构建hash表的时候保证的, 后续在 MultiExecPrivateHash 插入时如果 tuple 经过 hash 拿到的bucket属于 skew-bucket,则会将这个 tuple 插入其中并通过 链表连接起来.
// 获取skew bucket
int
ExecHashGetSkewBucket(HashJoinTable hashtable, uint32 hashvalue)
{
...
bucket = hashvalue & (hashtable->skewBucketLen - 1);
while (hashtable->skewBucket[bucket] != NULL &&
hashtable->skewBucket[bucket]->hashvalue != hashvalue)
bucket = (bucket + 1) & (hashtable->skewBucketLen - 1);
if (hashtable->skewBucket[bucket] != NULL)
return bucket;
...
}
// 将 读取到的 tuple数据 存储到 bucketNumber 对应的skewbucket中
static void
ExecHashSkewTableInsert(HashJoinTable hashtable,
TupleTableSlot *slot,
uint32 hashvalue,
int bucketNumber)
{
...
hashTuple = (HashJoinTuple) MemoryContextAlloc(hashtable->batchCxt,
hashTupleSize);
hashTuple->hashvalue = hashvalue;
memcpy(HJTUPLE_MINTUPLE(hashTuple), tuple, tuple->t_len);
HeapTupleHeaderClearMatch(HJTUPLE_MINTUPLE(hashTuple));
// 插入链表中
hashTuple->next.unshared = hashtable->skewBucket[bucketNumber]->tuples;
hashtable->skewBucket[bucketNumber]->tuples = hashTuple;
Assert(hashTuple != hashTuple->next.unshared);
...
}
对于非skewbucket, 则通过 ExecHashTableInsert --> ExecHashGetBucketAndBatch hashvalue 获取到对应的 bucketno和batchno
*bucketno = hashvalue & (nbuckets - 1);
*batchno = pg_rotate_right32(hashvalue,
hashtable->log2_nbuckets) & (nbatch - 1);
如果拿到的 batchno 和 当前hash表正在操作的 batch相同 batchno == hashtable->curbatch, 则将 tuple 插入到当前bucket管理的tuple链表头部, 并处理当前batch 内存超限的情况.
插入逻辑如下:
hashTuple->hashvalue = hashvalue;
memcpy(HJTUPLE_MINTUPLE(hashTuple), tuple, tuple->t_len);
hashTuple->next.unshared = hashtable->buckets.unshared[bucketno];
hashtable->buckets.unshared[bucketno] = hashTuple;
处理内存超限的逻辑如下:
- batchno 翻倍, 遍历内存hash表中的每一个bucket的tuple 重新计算batch编号. 之前batchno 的计算公式是 :
pg_rotate_right32(hashvalue,hashtable->log2_nbuckets) & (nbatch - 1);, 则重新计算的batch编号只有两种可能,要么是i ,要么是 i + nbatch/2 - 将属于新的batchno 的tuple 通过
ExecHashJoinSaveTuple写入到文件, 并维护在内存中的bucket的链表的完整性.
如果 ExecHashTableInsert 拿到的 batchno 不是 hashtable->curbatch,则直接通过 ExecHashJoinSaveTuple 写tuple 到磁盘对应的 BufFile, 等待分批处理的时候从磁盘load.
回到 HJ_BUILD_HASHTABLE 状态, 后续还有 parallel的处理(PG 进程架构加速算子性能,允许开启多个进程并发执行)并不属于主体逻辑, 本文不会做过多的介绍.
接下来会进入到 第二个状态 HJ_NEED_NEW_OUTER.
2.HJ_NEED_NEW_OUTER 这个状态是划分阶段的第二个主体逻辑, 即使用相同的hash 函数 处理 outer table S的划分.
拿到一个outer table的tuple:
a. 如果这个tuple为空, 且是right-join (如果是 right-join, 则会在ExecInitHashjoin时初始化 (hjstate)->hj_NullOuterTupleSlot), 则进入 HJ_FILL_INNER_TUPLES 状态,开始填充所有的左表的数据.
b. 如果这个tuple为空 但不是right-join,说明当前batch数据处理完了,进入 HJ_NEED_NEW_BATCH 状态读取下一个batch 对应的 BufFile.
c. tuple不为空,则获取其所属的bucket 以及 batchno, 如果bucket是 skewbucket或者batch 属于当前batch,则进入 HJ_SCAN_BUCKET 状态进行probe.
d. 如果不属于当前batch, 则将当前 tuple 写入到对应的batch文件.
3. HJ_SCAN_BUCKET 这个状态是处理 outer table 的 probe tuple, 用这个tuple 通过 ExecScanHashBucket 探查 inner table内存中的hash表, 如果探查失败,则转到 HJ_FILL_OUTER_TUPLE 状态,填充所有的右表的数据.
如果探查成功, 则进行 filter 和 project 处理, 进行过滤和投影操作, 这个后面会细说.
4. HJ_FILL_OUTER_TUPLE 处理 tuple probe失败的情况, 如果是LEFT-JOIN,则输出 inner-table 和 null的连接结果.
node->hj_JoinState = HJ_NEED_NEW_OUTER; // 拿下一个outer tuple
if (!node->hj_MatchedOuter &&
HJ_FILL_OUTER(node))
{
...
econtext->ecxt_innertuple = node->hj_NullInnerTupleSlot;
if (otherqual == NULL || ExecQual(otherqual, econtext))
return ExecProject(node->js.ps.ps_ProjInfo);
...
}
5. HJ_FILL_INNER_TUPLES 处理 RIGHT-JOIN的情况, 即输出所有还没有匹配过的内表的 Tuple, 如果处理完了所有的内表数据,进入下一个阶段 分批处理阶段: HJ_NEED_NEW_BATCH .
HashJoin 的分批处理阶段
分批处理阶段 主要处理 Ri 和 Si (i>=2) 的BufFile数据, R1和S1 在划分阶段的五个状态中已经处理完并输出了, 需要加载下一批batch数据到内存, 对于 R表来说就是加载下一个batch对应的BufFile tuple 数据到内存并构建hash表, S表则是读取下一个 BufFile的tuple 尝试进行probe.
主要涉及到的状态:
1. HJ_NEED_NEW_BATCH 处理下一个batch.
// 从R 表的 BufFile文件中读取tuple 并构建内存hash表.
innerFile = hashtable->innerBatchFile[curbatch];
while ((slot = ExecHashJoinGetSavedTuple(hjstate,
innerFile,
&hashvalue,
hjstate->hj_HashTupleSlot)))
{
/*
* NOTE: some tuples may be sent to future batches. Also, it is
* possible for hashtable->nbatch to be increased here!
*/
ExecHashTableInsert(hashtable, slot, hashvalue);
}
之后的状态就回到之前划分阶段的 2,3,4,5 状态的处理过程了.
2. HJ_NEED_NEW_OUTER 读取outer table的tuple
3. HJ_SCAN_BUCKET 尝试进行probe.
4. HJ_FILL_OUTER_TUPLE 处理 LEFT-JOIN的情况
5. HJ_FILL_INNER_TUPLES 处理 RIGHT-JOIN 的情况
JOIN 类型的状态机转换
JOIN-INNER 核心是仅输出所有匹配的左右表元组

所以状态机的流转比较简单, 划分阶段和分批处理阶段没有额外处理 OUTER/INNER 输出的状态.
JOIN-LEFT 核心是输出所有的外表的元组, 对于内表不匹配的元组则输出null. 有一个细节是说如果一个外表tuple 在 HJ_SCAN_BUCKET 阶段和内表的hash表 probe成功并输出之后 下一次还会再进入这个状态, 继续 probe相同内表bucket的下一个tuple 直到 probe 失败并处理下一个 外表tuple. 即 outer join 在内表有多个相同hash-value的元组的时候允许输出多行.

JOIN-RIGHT 核心是输出所有的内表的元组, 对于外表不匹配的元组则输出null. 同上在 HJ_SCAN_BUCKET成功输出 之后下次继续进入这个状态probe.

JOIN-SEMI 半连接, 核心是在找到内表和外表匹配的tuple之后 仅输出外表的tuple. 且 输出结果是 unique的, 即不允许像 OUTER join 可以同一个tuple probe 多次内表.

JOIN-ANTI 反连接, 核心是在 内外表匹配 且 符合 ExecQual(join-filter)条件时 不输出, 仅输出不配的tuple, 同样 该连接条件的输出结果是 unique的.

HashJoin 的投影和过滤
理清楚 PG HashJoin 对于不同join 类型的处理细节之后,整个 HashJoin 的核心逻辑就算是结束了. 不过最终结果的输出从之前的代码来看, 必须要经过 ExecQual 以及 ExecProject 两个函数.
这两个函数做的事情分别是处理 joinqual 以及 targetlist, 也就是 过滤 和 投影.
如下query的执行计划:
test=# explain verbose select a.c1,b.c2 from a,b where a.c1=b.c2 and a.c1 > 2 * b.c1;
QUERY PLAN
------------------------------------------------------------------------
Hash Join (cost=60.85..1120.62 rows=8513 width=8)
Output: a.c1, b.c2
Hash Cond: (a.c1 = b.c2)
Join Filter: (a.c1 > (2 * b.c1))
-> Seq Scan on public.a (cost=0.00..32.60 rows=2260 width=4)
Output: a.c1, a.c2
-> Hash (cost=32.60..32.60 rows=2260 width=8)
Output: b.c2, b.c1
-> Seq Scan on public.b (cost=0.00..32.60 rows=2260 width=8)
Output: b.c2, b.c1
(10 rows)
其中能够看到 HashJoin 节点之下有 Output、Hash Cond 以及 Join Filter.
- Output 只有两列, 关系代数中可以理解为投影, 将两表join的结果提取其中某一些列形成新的表并输出. 这里的targetlist 仅包括两列, a.c1 以及 b.c2. 实际 targetlist 中的每一个元素都可以是表达式, 比如 2 * a.c1, sqrt(b.c2)
- Hash Cond 可以理解为是连接条件, 构建hash表的时候会在 b表的 c2列构建,用 a表的c1列去probe构建的hash表. Hash Cond 会被保存到
node->js.ps.qual链表中, HashCond 也可以是表达式. - Join Filter 则是 过滤, 只要满足某一些条件的tuple才能输出. 这个表达式则会被保存到
node->js.joinqual.
对于 output 的 targetlist 的初始化是通过 ExecInitHashJoin --> ExecAssignProjectionInfo --> ExecBuildProjectionInfo --> ExecBuildProjectionInfoExt, 走PG 的表达式初始化逻辑, 这块后面会统一介绍. 需要注意的是 output 对于当前节点来说 相当于输出了新的tuple, 其结果的TupleDesc 是保存在 planstate->ps_ResultTupleDesc, 如果我们想知道当前算子输出的tuple是什么样子的(schema, nattrs等信息), 都可以从这个 TupleDesc中提取, 这个信息对于我们想要将 PG 算子向量化来说极为重要, 一旦处理不对结果就有问题.
joinqual 以及 qual的初始化同样是在 ExecInitHashJoin --> ExecInitQual 完成, 也是走表达式初始化系统, 后续统一介绍.
因为 HashCond 已经融入到了 build hash表以及probe阶段(内表和外表都会选择 hash-cond 中自己的列作为hashkey) , 所以仅需额外处理 join-filter 和 project, 这两个操作的执行顺序是先 filter, 在project, 因为filter能提前做一个过滤, 就能避免部分逻辑再走 project了, 在 pull模型下, 某一些超级query的 project 表达式可能会非常长, 提前filter能避免极多的不必要逻辑. project 则是必须要走的逻辑.
PG 本身也有属于自己的 ProjectSet 算子, 专门做 Project, 不过在 Join或者 Agg 这样的算子中都用的是 ExecProject, 单独用算子来做这一些投影操作其实有点重, 多了不少初始化以及调度的逻辑. 所以 ProjectSet 这样专门用于 array_agg 以及 literal 的特殊语法才会使用.
到此 整个PG 的执行器架构 以及 HashJoin 算子介绍完了, 比较简单, 但是细节很多 且 需要考虑 spill 以及 支持各种 Join 类型.
接下来看看 Arrow Acero 执行引擎的整体调度框架以及 HashJoin 算子的实现, 因为其是标准的 Push模型, 且完全向量化了, 所以能看到很多相比于 Pull 模型非常有趣的差异.
Arrow Acero HashJoin实现
Acero 是 Arrow C++库中的一个向量化计算引擎, 可以像其他计算引擎一样被用于分析流式的数据. Acero 也可以算是 对Arrow 的核心设计 内存格式 计算层面的应用,包括 type-system, RecordBatch, compute, ipc … 在 Acero 中能够看到如何优雅得使用 Arrow 的核心设计.
Acero 基本框架
借用官方的一张图来看看 Acero 和其他组件之间的关系.

- Core 中的数据结构用来组织 Arrow 的内存数据, 其中 Chunked Array 和 Table 两种结构没有被 Acero 用到
- Compute 是 Arrow 服务于计算层的一套数据结构, 其和 Acero 的本质区别可以理解为 Compute 用于直接处理所有在内存中的数据, Acero 则能够处理流式数据. Acero中的计算节点 吐出的 RecordBatch 可以通过调度 Compute中的计算体系来进行处理. 后面介绍 hashjoin 的实现的时候能够看到 Acero 处理节点本身的算法实现以及pipeline 的实现之外核心的计算逻辑(各种类型的表达式计算、常量折叠 等等)都是通过 compute完成, 当然 SIMD 也是在这一部分支持的最多.
- Acero 中包含了一些定义算子 以及 调度plan 的数据结构.
本节只会粗略介绍一下 Acero, 毕竟Arrow是 Wes 大佬的设计, 且本就是抽象度足够高的计算领域, 有太多优雅的东西可以学习(借鉴–抄:));
HashJoin 基本流程
对于 如下这样的基于 Push 模型的plan:

画的是数据流的方式, 从Scan节点开始, 其本身是没有上游节点的,因为Scan节点就是数据的最上游的生产者, 生产出来的数据以 RecordBatch的方式 Push到下游接受数据的节点(比如 hashjoin), HashJoin有上游节点也有下游节点, 同样做一些处理 将数据 以 RecordBatch 的方式push到下游的 filter/project节点. 对于 Push 模型的向量化节点来说, 数据的流式处理能够充分利用 cpu 缓存以及 simd 指令集, 并且极大得减少了函数调用的开销(batch 处理). 不过问题也很明显, 没有办法灵活得控制输入的数据量和数据规模, 一旦push模型的 plan 调度起来, 当前节点是没有办法终止数据的输入的, 数据输入和输出的规模都不好控制, 毕竟数据输入是从上游节点强制push下来的, 不是像pull 一样上游节点问你要数据.
如下案例, 是一个非常简单的 acero hashjoin的调度:
// 生成数据
ARROW_ASSIGN_OR_RAISE(auto input, MakeGroupableBatches());
// 定义 LeftScan 节点
ac::Declaration left{"source", ac::SourceNodeOptions{input.schema, input.gen()}};
// 定义 RightScan节点
ac::Declaration right{"source", ac::SourceNodeOptions{input.schema, input.gen()}};
// HashJoin 采用 inner类型, 且 cp::literal(true) 表示使用 swisstable 做hash表
ac::HashJoinNodeOptions join_opts{
ac::JoinType::INNER,
/*left_keys=*/{"str"},
/*right_keys=*/{"str"}, cp::literal(true), "l_", "r_"};
// 定义 hashjoin 的节点, 并指定左右子节点
ac::Declaration hashjoin{
"hashjoin", {std::move(left), std::move(right)}, std::move(join_opts)};
// 调度hashjoin 的执行
return ExecutePlanAndCollectAsTable(std::move(hashjoin));
如上案例 主要是通过 Declaration 声明节点, Declaration 能够比较友好得组织管理 ExecNode , 并且能够快速将管理的 ExecNode 算子通过 AddToPlan 添加到执行计划 之中.
如上案例中添加好的 hashjoin 以及被作为hashjoin Declaration 初始化参数的左右子节点都会在 DeclarationToTableImpl 中按照添加顺序完成初始化并添加到 ExecPlan中进行 StartProducing 的异步调度.
接下来看看 HashJoin 实际是如何被 Acero 调度起来的:

本图额外补充了 HashJoin 经常用到的 JoinFilter 以及 Project 算子:
-
初始化. Arrow 对于输入的plan 进行 toposort 之后会形成如上红色箭头的 初始化 顺序.
-
Arrow的 hashjoin 分为 probe 以及 build端, build 部分是用hash-join 的 inputs_[1] 即 right-input 内表 节点生成的RecordBatch数据在 内存中构建 hash表; Probe 则是hash-join 的 inputs_[0] left-intput 节点进行hash表的探查.
-
数据流 则是在初始化过程中 从 source-node 即上图中生成数据的两个scan节点开始, 这一些节点调度自己的 StartProducing 进行数据的读取(读取parquet文件) 形成record-batc 作为输入 传给 下游节点(hash-join)的 inputReceived 进行对应的处理. 处理完成通过 inputFinished 标识当前节点处理完毕.
因为 Arrow 有自己的 pipeline 调度, 所以 inputReceived 和 InputFinished 每一个节点都会有, 每次数据上游节点push 的batch数据都可以 以pipeline方式在整个plan之间传递, 直到 最上游的节点调度 InputFinished 才标识数据处理完毕, 并调用下游节点的 InputFinished. -
Arrow 拥有自己的 Filter-node 和 Project node, 所以可以有专门的节点来做投影和过滤. 因为有pipeline 的存在, 数据流按照 batch 通过这一些节点的时候并不会对性能有多少影响.
需要注意的是 Acero 的调度框架为了达成高效的 PipeLine 处理模式, 让整个执行计划上的所有算子每次接受到的 ExecBatch 都可以被当前算子启动的一个task异步处理. 当然 pipeline的复杂度主要是在正确性上, 因为有一些 batch 的处理是一定要求第 X 个要在 X-1 个之后处理,但是这样的异步调度可能出现第 X 个batch 在 第 X-1 个batch之前被处理完. 这就会有问题. 整个 pipeline 全链路异步 以及 正确性如何保证是 Acero 调度体系的核心, 这个就复杂多了.
提一嘴 HashJoin 的Schema, 本质上使用 Acero 的hashjoin时并不会有额外需要 Filter以及Project 节点的需求, 因为 HashJoinSchema 这个数据结构已经做了相关的管理, Filter 本质是过滤输出的行, 而 Project 则是过滤输出的列. 用户在构造 HashJoin 的 Declaration的时候指定了相关的 Filter, 制定了 Output的schema, 比如:
HashJoinNodeOptions(
JoinType join_type, std::vector<FieldRef> left_keys,
std::vector<FieldRef> right_keys, std::vector<FieldRef> left_output,
std::vector<FieldRef> right_output, Expression filter = literal(true),
std::string output_suffix_for_left = default_output_suffix_for_left,
std::string output_suffix_for_right = default_output_suffix_for_right,
bool disable_bloom_filter = false)
: join_type(join_type),
left_keys(std::move(left_keys)),
right_keys(std::move(right_keys)),
output_all(false),
left_output(std::move(left_output)),
right_output(std::move(right_output)),
output_suffix_for_left(std::move(output_suffix_for_left)),
output_suffix_for_right(std::move(output_suffix_for_right)),
filter(std::move(filter)),
disable_bloom_filter(disable_bloom_filter) {
this->key_cmp.resize(this->left_keys.size());
for (size_t i = 0; i < this->left_keys.size(); ++i) {
this->key_cmp[i] = JoinKeyCmp::EQ;
}
}
构建 HashJoinNodeOptions 的时候也可以指定输出的左右 fields, 以及Expression filter, 然后在 HashJoinNode::Make即初始化 HashJoinNode 的时候会利用这一些 right_output 以及 left_output 来构造 output_schema, 从而也就有了用户指定的输出列.
当然,在 HashJoinSchema 中有更加优雅的管理 schema 的方式, 除了保证输入、输出、filter等操作的正确性, 还需要能够有高性能, 尤其是大宽表场景中快速获取对应的列schema信息就尤为重要.
上面只是基本的调度流程, Acero hashjoin 的详细实现本文暂时不会展开, 因为还有 和simd深度结合的 超高性能的 swisstable 还在学习中, 等后续有时间了和 hashjoin 以及 pipeline 一起介绍.文章来源:https://www.toymoban.com/news/detail-715897.html
总结
本文只是通过 PG 和 Arrow 这两个各自在数据以及计算领域如日中天的系统 介绍一下 Pull 和 Push 模型的工作形态. 因为前者服务于 TP 系统, 后者服务于 AP 系统, 所以没有可比性. 但是 HashJoin的基本实现还是比较接近, build hash表之后probe, 只是两者在性能上的考虑因为面对的应用场景不同,有比较大的差异:文章来源地址https://www.toymoban.com/news/detail-715897.html
- PG 因为要支持外存的 hashjoin 而且是 once-a-tuple 的模型,所以在性能的考虑上主要是如何尽可能得减少对数据的IO访问上.
- Arrow 目前不支持外存join 且 是 once-a-batch 工作形态, 即使未来支持spill ,这个也不是其工作的核心,因为arrow 主打的是对内存数据格式的统一 以及 高效处理平台, 所以 arrow 的 hashjoin 性能核心就是尽可能得利用好CPU 来完成算子的计算. 也就有了 io和计算分离的threadpool, pipeline调度, swisstable + simd 而不是传统的unordered_map(无法高效利用simd 指令集). 这一些设计其实都是面向当下分析型场景中高效利用多核CPU特性而设计的, 值得深入学习.
到了这里,关于HashJoin 在 Apache Arrow 和PostgreSQL 中的实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!