先看卷积是啥,url: https://www.bilibili.com/video/BV1JX4y1K7Dr/?spm_id_from=333.337.search-card.all.click&vd_source=7a1a0bc74158c6993c7355c5490fc600
下面这个式子就是卷积
看完了,感觉似懂非懂
下一个参考视频:https://www.youtube.com/watch?v=E5Z7FQp7AQQ&list=PLuhqtP7jdD8CD6rOWy20INGM44kULvrHu
视频1:简单介绍卷积神经网络的意义,以及它的大概原理
先讲一个简单神经网络在图像识别领域里缺点

如上图,一个 1000 * 1000 的 RGB 图像,这里一共需要 1000 * 1000 * 3 = 三百万 个输入神经元
随后,它的第一个隐藏层包含 1000 个神经元。这样来看,输入层和第一个隐藏层之间的边(连接)一共有 三百万 * 1000 = 三十亿
这是一个非常大的数字,如果我们要去训练这样的一个 权重矩阵,将会耗费巨大的时间
此外,过量的参数和过大的权重矩阵通常也意味着 过拟合
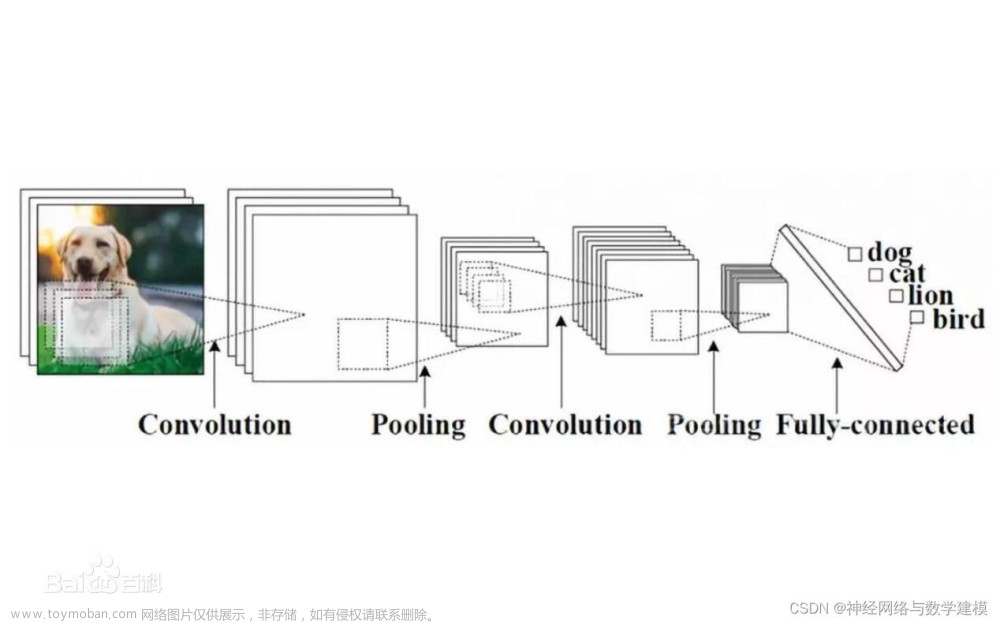
这就是为什么需要卷积神经网络,它在图像识别和视频识别领域要远强于简单的神经网络
卷积神经网络的思想如下:
使用 filters(滑动窗口) 去提取图像中的特征。
图像有一个特性,就是它会有边、形状、颜色。
CNN 的 filters 的任务就是检测图像里的上述特征,如下图

上图使用两个filter 去提取图像特征,分别是提取水平边 和 垂直边。filter(滑动窗口)的大小仅仅为 3* 3 = 9 像素
卷积神经网络中的 单层神经元 会使用大量这样的 filters
这些 filters 可能会检测我们图像里的边,随后这些边传给 更深的隐藏层,这些隐藏层可能会检测出 人脸的局部特征。、
再更深层的神经网络则可能会检测出整张人脸。接着这些人脸特征可以和一个 label “人类” 联系起来,从而帮助我们检测到人类。
这里减少的开销:三十亿参数 -> 很少的参数 增加的开销:sliding window
视频2:CNN 中的卷积操作到底是什么?

如上图,卷积其实就是拿一个 3*3 的矩阵去乘以图像矩阵,具体请看视频 3:35

为什么卷积操作能够提取图像特征?如图所示,棕色的卷积矩阵可以提取灰度图中的 垂直边,具体请看 5:05

相应的,提取垂直边的是上面的卷积矩阵,提取水平边的是下面的卷积矩阵 (或者叫做 filter)

遇到 RGB 图怎么办呢?简单,我们也用一个 乘以3 的 filter (也就是一共 27 个值) 去做卷积,随后产出一个特征图

我们用多少个 filter 就会产出多少个 特征图。
这里提示一下,filter 里的值实际上就是 卷积神经网络 里的 参数,它们通常由训练得来。
视频3:卷积神经网络中的 padding ,为什么需要 padding?
之前介绍的 CNN 有两个限制。
限制1:经过卷积操作后,图像会变小,也就说经过了很多层卷积后,图像可能变得非常小,丢掉很多信息。如下图

限制2:角落的像素没有收到足够多的关注。如下图。
左上角的 pixel 在做卷积操作的时候只会参与一次,而中心的 pixel 则会参与多次
解决方案就是给图像加上 padding,我们可以加一层 padding,也可以加两层三层,下图展示加一层 padding 的情形

从上图可以看到,加了 padding 之后,产出的图像是 6*6,尺寸和原图一样
此外,左上角的 pixel 也参与了多次卷积操作

如上图,一般来说,卷积操作有两种选择:文章来源:https://www.toymoban.com/news/detail-716012.html
- Valid 。不使用任何 padding
- Same。卷积后产出的特征图,尺寸和原图一样。
一般而言,filter滑动窗口的边长会使用奇数,否则,padding 需要使用非对称 padding文章来源地址https://www.toymoban.com/news/detail-716012.html
到了这里,关于什么是 CNN? 卷积神经网络? 怎么用 CNN 进行分类?(1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!