一、Sparkshuffle
(1)Map和Reduce
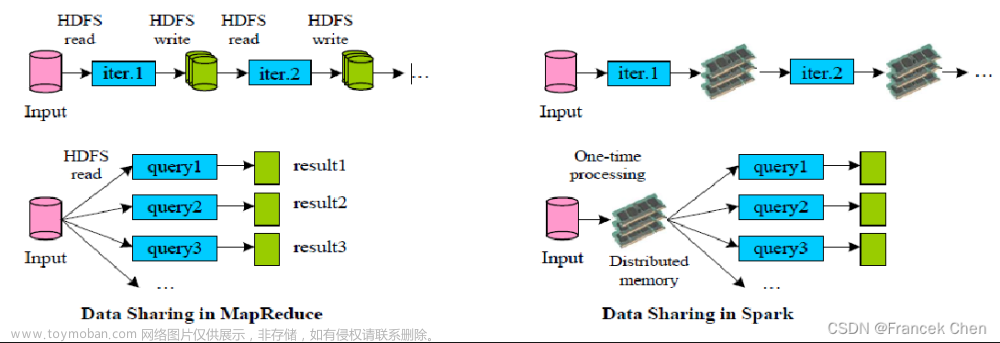
在shuffle过程中,提供数据的称之为Map端(Shuffle Write),接受数据的称之为Redeuce端(Shuffle Read),在Spark的两个阶段中,总是前一个阶段产生一批Map提供数据,下一阶段产生一批Reduce接收数据。

(2)Shuffle管理器
①HashShuffleManager
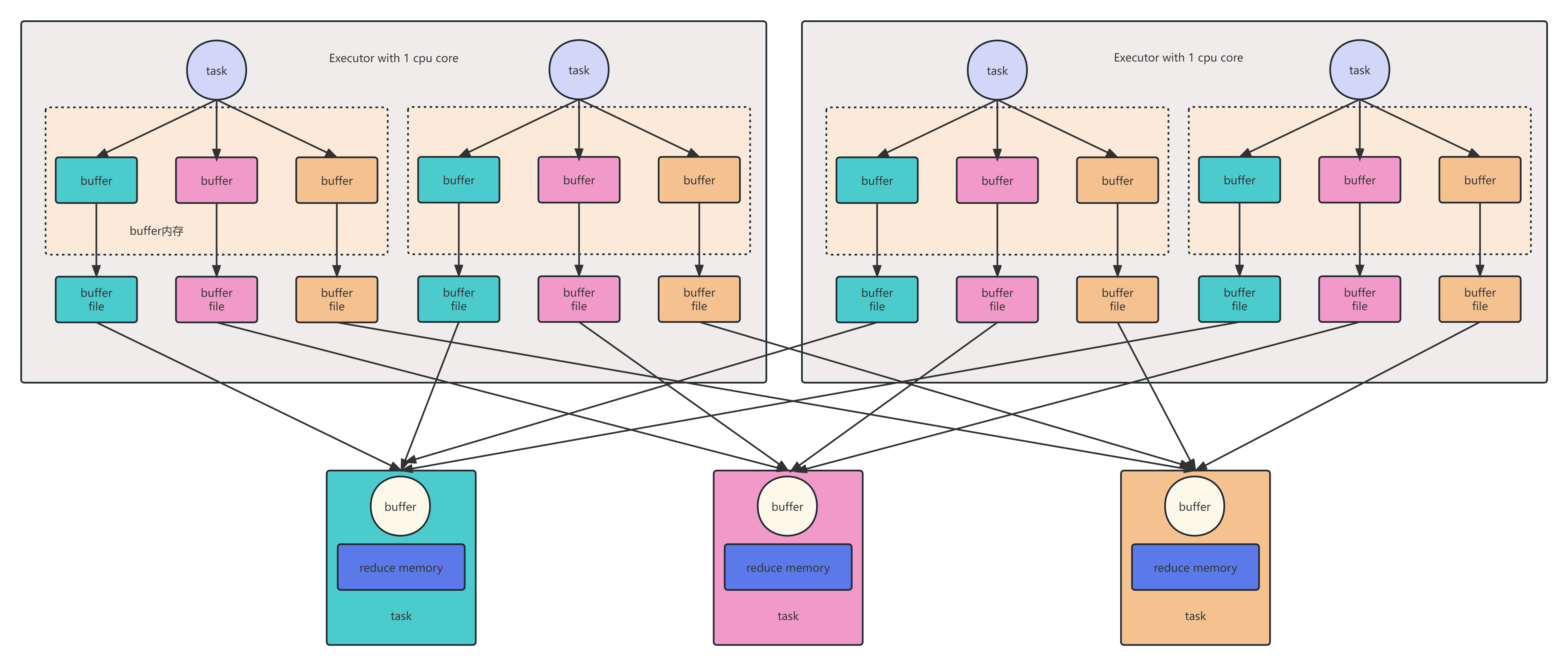
HashShuffleManager是Spark的一个组件,用于实现在节点之间进行数据分发和合并。它的主要作用是将数据进行随机哈希分区,然后将不同分区的数据发送到不同的节点上进行处理,最后将结果合并返回给调用方。HashShuffleManager的优点是能够高效地处理大规模数据集,同时保证数据的顺序性和数据安全性。它一共分为两种,一种有优化,一种无优化。

优化后的和未优化的一致,不同点在于
1. 在一个Executor内, 不同Task是共享Buffer缓冲区
2. 这样减少了缓冲区乃至写入磁盘文件的数量, 提高性能

②SortShuffleManager
SortShuffleManager是Spark的一个组件,用于实现在节点之间进行数据分发和合并。与HashShuffleManager不同的是,SortShuffleManager使用的是排序方式进行数据分发和合并。相对于HashShuffleManager,SortShuffleManager的优点是能够更好地保证数据的有序性,减少数据倾斜的情况,提高数据处理效率。但是,SortShuffleManager需要进行排序操作,需要占用更多的计算资源和时间。因此,在不同的使用场景下,可以选择合适的ShuffleManager来实现数据分发和合并。
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。
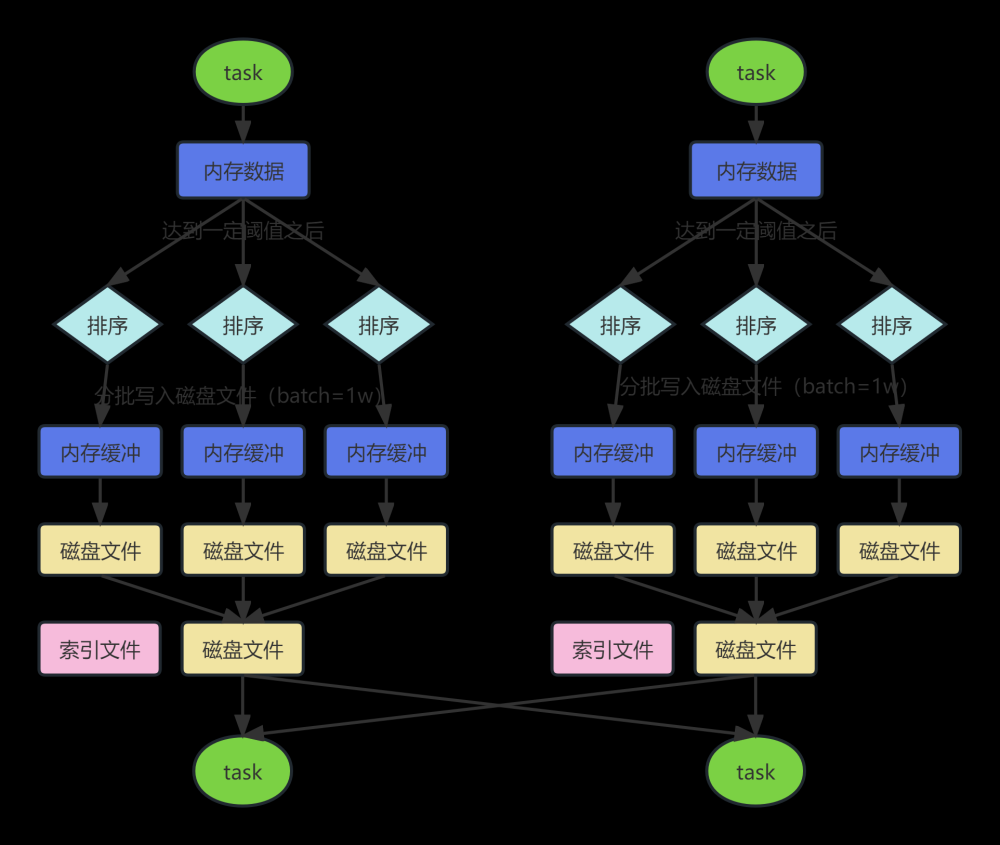
bypass运行机制的触发条件如下:
(1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
(2)不是聚合类的shuffle算子(比如reduceByKey)。
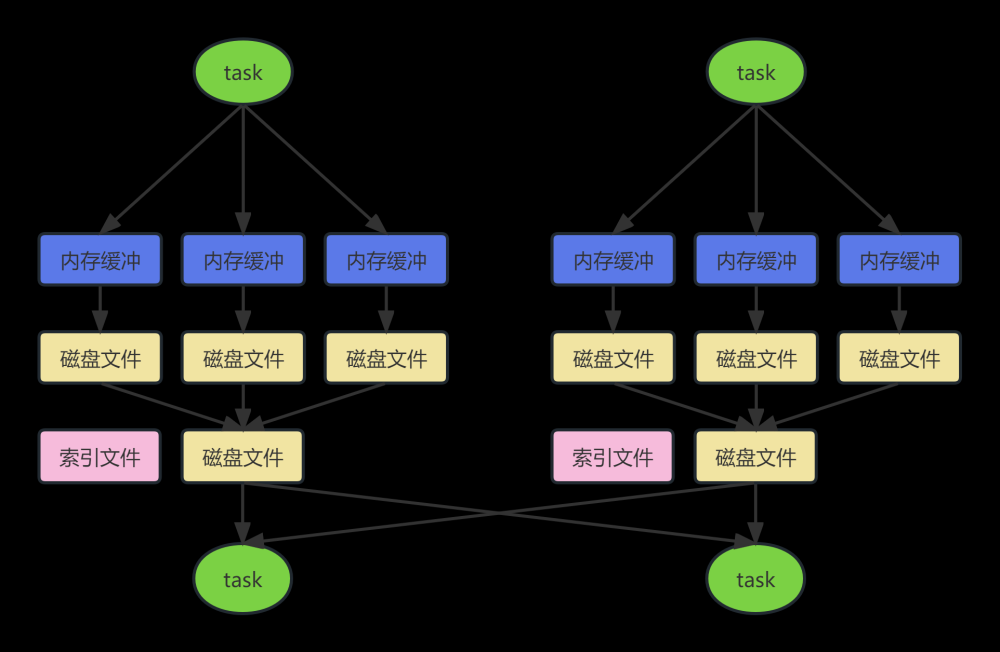
同普通机制基本类同, 区别在于, 写入磁盘临时文件的时候不会在内存中进行排序而是直接写,最终合并为一个task一个最终文件。
与普通模式IDE区别在于:
第一,磁盘写机制不同。
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
二、Spark3新特性概览
(1)Adaptive Query Execution 自适应查询(SparkSQL)
由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想。在Spark3.x版本提供Adaptive Query Execution自适应查询技术,通过在”运行时”对查询执行计划进行优化,允许Planner在运行时执行可选计划,这些可选计划将会基于运行时数据统计进行动态优化,从而提高性能。
Adaptive Query Execution AQE主要提供了三个自适应优化:
①动态合并Shuffle Partitions
②动态调整Join策略
③动态优化倾斜Join(Skew Joins)
开启AQE方式:
set spark.sql.adaptive.enabled = true;
①动态合并Dynamically coalescing shuffle partitions
可以动态调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区。


②动态调整Join策略Dynamically switching join strategies
此优化可以在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行计划性能不佳的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能。

③动态优化倾斜Join
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测至J任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。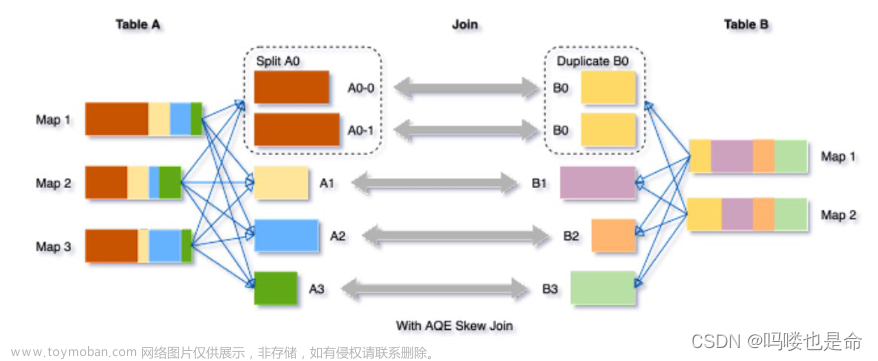
触发条件:
1.分区大小> spark.sql.adaptive.skewJoin.skewedPartitionFactor (default=10) * "median partition size(中位数分区大小)"
2.分区大小 > spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes (default = 256MB)
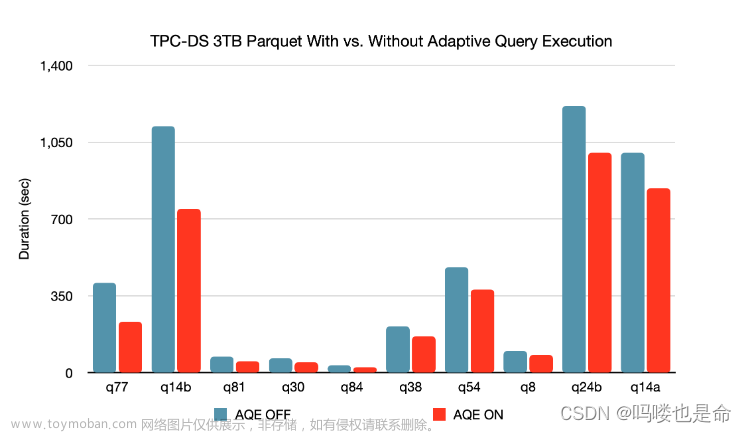
④AQE总结
1.AQE的开启通过: spark.sql.adaptive.enabled设置为true开启。
2.AQE是自动化优化机制,无需我们设置复杂的参数调整,开启AQE符合条件即可自动化应用AQE优化。
3.AQE带来了极大的SparkSQL性能提升。
(2)Dynamic Partition Pruning动态分区裁剪(SparkSQL)
当优化器在编译时无法识别可跳过的分区时,可以使用"动态分区裁剪",即基于运行时推断的信息来进一步进行分区裁剪。这在星型模型中很常见,星型模型是由一个或多个并且引用了任意数量的维度表的事实表组成。在这种连接操作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。在一个TPC-DS基准测试中,102个查询中有60个查询获得2到18倍的速度提升。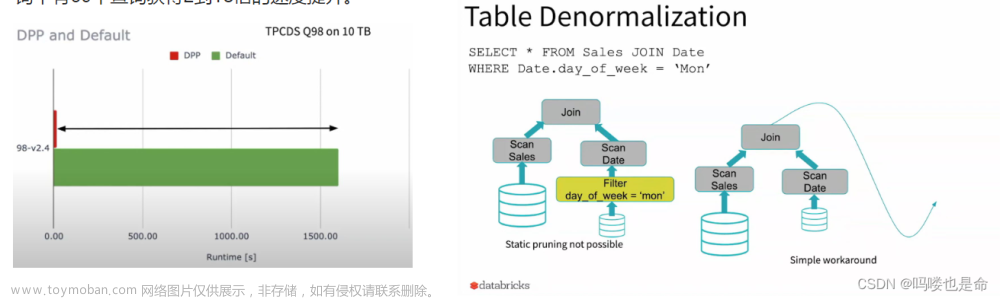
(3)增强的Python APl: PySpark和Koalas
Python现在是Spark中使用较为广泛的编程语言,因此也是Spark 3.0的重点关注领域。Databricks有68%的notebook命令是用Python写的。PySpark在 Python Package lndex上的月下载量超过500万。
很多Python开发人员在数据结构和数据分析方面使用pandas APl,但仅限于单节点处理。Databricks会持续开发Koalas——基于Apache Spark的pandas API实现,让数据科学家能够在分布式环境中更高效地处理大数据。
经过一年多的开发,Koalas实现对pandas API将近80%的覆盖率。Koalas每月PyPI下载量已迅速增长到85万,并以每两周一次的发布节奏快速演进。虽然Koalas可能是从单节点pandas代码迁移的最简单方法,但很多人仍在使用PySpark API,也意味着
PySpark API也越来越受欢迎。

三、Spark核心概述文章来源:https://www.toymoban.com/news/detail-716195.html
 文章来源地址https://www.toymoban.com/news/detail-716195.html
文章来源地址https://www.toymoban.com/news/detail-716195.html
到了这里,关于Spark新特性与核心概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!