作为互联网时代的重要组成部分,搜索引擎扮演着指引我们获取信息的角色。而搜索引擎如何实现对网页的爬取,一直是人们关注的焦点之一。本文将从多个方面详细介绍搜索引擎如何爬取网页,帮助读者更好地理解这一过程。
1.爬虫的作用
搜索引擎通过爬虫程序对互联网上的网页进行抓取,构建庞大的索引库,以便用户能够快速、准确地找到所需信息。爬虫是搜索引擎的重要组成部分,它们按照一定的规则遍历互联网上的网页,并将其内容保存下来。
2.爬虫的工作原理
当用户在搜索引擎中输入关键词进行搜索时,搜索引擎会根据爬虫抓取到的页面内容进行匹配,并返回相关结果。爬虫会按照设定的算法对网页进行抓取、解析和存储。
3.网页链接的发现
爬虫首先从一个或多个种子URL开始,通过解析页面中的链接来发现更多的页面。这些链接可以是页面内部链接、外部链接或者是其他网站的链接。爬虫会按照一定的策略选择需要抓取的链接,并将其加入待抓取队列。
4.页面内容的抓取
一旦爬虫从队列中选取了一个链接,它就会发送HTTP请求到服务器,获取页面的HTML代码。然后,爬虫会解析HTML代码,提取出页面中的文本、图片、视频等信息,并进行存储。
5.避免重复抓取
为了避免重复抓取同一个页面,爬虫会记录已经抓取过的URL,并将其加入去重集合。在后续的抓取过程中,爬虫会先判断该URL是否已经在去重集合中,如果是,则跳过该URL。
6.处理动态页面
有些网页采用了动态生成技术,即在浏览器加载完页面后,通过JavaScript等技术再次向服务器请求数据并进行渲染。为了解决这个问题,搜索引擎爬虫会模拟浏览器行为,执行JavaScript代码,并获取最终生成的页面内容。
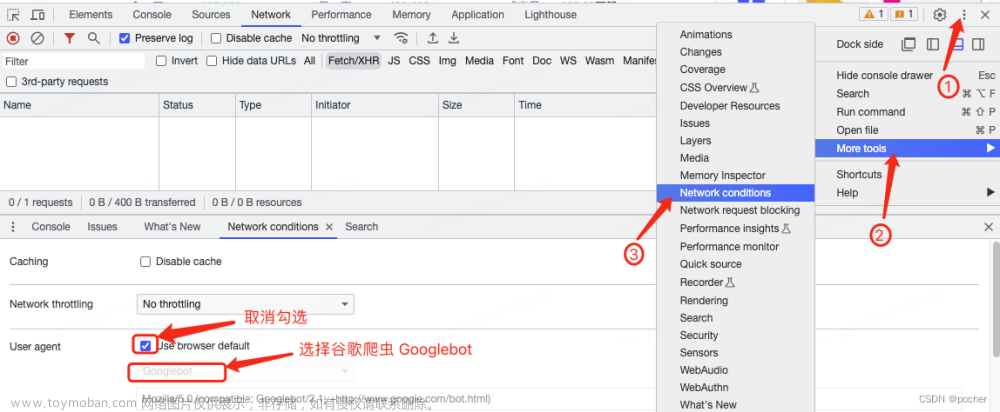
7. robots.txt文件的作用

robots.txt文件是网站管理员用来指示搜索引擎爬虫哪些页面可以访问、哪些不可以访问的文件。搜索引擎爬虫在抓取页面之前会先查看该文件,并根据其中的规则进行处理。
8.爬虫的策略
为了高效地抓取网页,搜索引擎爬虫会采用一些策略。例如,爬虫会优先抓取高质量、高权重的页面;在抓取过程中,会限制对同一网站的并发请求数量,以避免对服务器造成过大压力。
9.反爬机制与应对策略
为了防止非法抓取和保护网站数据安全,一些网站会采取反爬机制。例如,通过验证码、IP封禁等手段来限制爬虫的访问。搜索引擎爬虫需要应对这些反爬机制,并采取相应的策略进行处理。
10.爬虫的发展趋势
随着互联网的快速发展,搜索引擎爬虫也在不断演进。未来,随着人工智能技术的应用,搜索引擎爬虫将更加智能化、自适应,并能够更好地理解和解析网页内容。
通过本文的介绍,相信读者对搜索引擎如何爬取网页有了更深入的了解。搜索引擎爬虫在信息时代中扮演着重要的角色,它们的工作不仅仅是简单地抓取网页,更是为用户提供准确、高效的搜索结果。未来,随着技术的不断发展,搜索引擎爬虫将继续发挥重要作用,为用户带来更好的搜索体验。
(本文图片来源:Unsplash)
参考资料:
1.张亚勤,杨灿英,李鹏程.网页爬虫指南[M].机械工业出版社, 2021.
2.刘炜,陈波.搜索引擎原理与技术[M].清华大学出版社, 2020.文章来源:https://www.toymoban.com/news/detail-716337.html
3.徐云霞,邵晓丽.搜索引擎技术与应用[M].人民邮电出版社, 2019.文章来源地址https://www.toymoban.com/news/detail-716337.html
到了这里,关于搜索引擎:网页爬取的奥秘的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!