LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
导读:2023年07月31日,哈工大讯飞联合实验室,发布Chinese-LLaMA-Alpaca-2,本项目基于Meta发布的可商用大模型Llama-2开发,是中文LLaMA&Alpaca大模型的第二期项目,开源了中文LLaMA-2基座模型和Alpaca-2指令精调大模型。这些模型在原版Llama-2的基础上扩充并优化了中文词表,使用了大规模中文数据进行增量预训练,进一步提升了中文基础语义和指令理解能力,相比一代相关模型获得了显著性能提升。相关模型支持FlashAttention-2训练。标准版模型支持4K上下文长度,长上下文版模型支持16K上下文长度,并可通过NTK方法最高扩展至24K+上下文长度。
本项目主要内容
>> 针对Llama-2模型扩充了新版中文词表,开源了中文LLaMA-2和Alpaca-2大模型;
>>开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型;
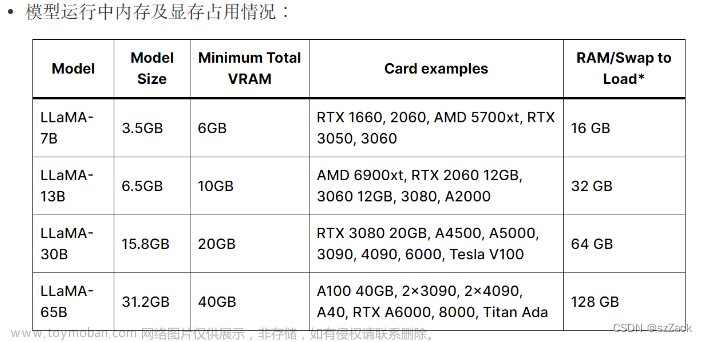
>>使用个人电脑的CPU/GPU快速在本地进行大模型量化和部署体验;
>>支持transformers, llama.cpp, text-generation-webui, LangChain, privateGPT, vLLM等LLaMA生态;
目录
相关文章
论文相关
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
实战应用相关
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
LLMs之Chinese-LLaMA-Alpaca:LLaMA汉化版项目详细源码解读多个py文件-基于Ng单机单卡实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(本质是高效参数微调,LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
LLMs:在单机CPU+Windows系统上实现中文LLaMA算法(基于Chinese-LLaMA-Alpaca)进行模型部署(llama.cpp)且实现模型推理全流程步骤的图文教程(非常详细)
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之LLaMA2:基于LocalGPT利用LLaMA2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略
LLMs之LLaMA2:基于云端进行一键部署对LLaMA2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数据集【datasets】→加载模型【transformers】→分词→模型训练【peft+SFTTrainer+wandb】→基于HuggingFace实现云端分享)之图文教程详细攻略
LLMs之LLaMA2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时微调LLaMA2模型(采用Conda环境安装tg webui+PyTorch→CLI/GUI下载模型→启动WebUI服务→GUI式+LoRA微调→加载推理)之图文教程详细攻略
Chinese-LLaMA-Alpaca-2的简介
1、已开源的模型
2、可视化本项目以及一期项目推出的所有大模型之间的关系
3、效果评估
(1)、生成效果评测
(2)、客观效果评测:C-Eval
(3)、客观效果评测:CMMLU
(3)、长上下文版模型(16K)评测
(4)、量化效果评测
Chinese-LLaMA-Alpaca-2的安装
1、下载模型
1.1、模型选择指引
1.2、完整模型下载
1.3、LoRA模型下载
(1)、LoRA模型无法单独使用,必须与原版Llama-2进行合并才能转为完整模型
2、模型训练与精调
2.1、预训练:基于deepspeed框架+Llama-2增量训练+采用120G纯文本+ 启用FlashAttention-2,默认fp16训练
(1)、训练步骤
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
(2)、支持的训练模式:基于原版LLaMA-2训练中文LLaMA-2 LoRA、基于中文LLaMA-2/Alpaca-2继续预训练(在新的LoRA上)
(3)、关于显存占用:只训练LoRA参数、减小block_size、开启gradient_checkpointing(但会降速)
(4)、使用多机多卡训练
(5)、训练后文件整理
2.2、指令精调:基于deepspeed框架+Chinese-LLaMA-2进行指令精调+500万条(Alpaca格式的json文件)+ 启用FlashAttention-2,默认fp16训练
(0)、⚠️重要提示⚠️
(1)、训练步骤
Stanford Alpaca数据集的格式如下:
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
(2)、支持的训练模模式:基于Chinese-LLaMA-2 LoRA进行指令精调、基于Chinese-LLaMA-2训练全新的指令精调LoRA权重
(3)、关于显存占用:只训练LoRA参数(单卡21G)、减小max_seq_length
(4)、使用多机多卡
(5)、训练后文件整理
3、推理与部署
T1、llama.cpp:丰富的量化选项和高效本地推理
T2、Transformers:原生transformers推理接口
T3、Colab Demo:在Colab中启动交互界面
T4、仿OpenAI API调用:仿OpenAI API接口的服务器Demo
T5、text-generation-webui:前端Web UI界面的部署方式
T6、LangChain:适合二次开发的大模型应用开源框架
T7、privateGPT:基于LangChain的多文档本地问答框架
Chinese-LLaMA-Alpaca-2的案例实战应用
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
相关文章
论文相关
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读_一个处女座的程序猿的博客-CSDN博客
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
https://yunyaniu.blog.csdn.net/article/details/131318974
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_一个处女座的程序猿的博客-CSDN博客
实战应用相关
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130397623
LLMs之Chinese-LLaMA-Alpaca:LLaMA汉化版项目详细源码解读多个py文件-基于Ng单机单卡实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(本质是高效参数微调,LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
https://yunyaniu.blog.csdn.net/article/details/131319010
LLMs:在单机CPU+Windows系统上实现中文LLaMA算法(基于Chinese-LLaMA-Alpaca)进行模型部署(llama.cpp)且实现模型推理全流程步骤的图文教程(非常详细)
LLMs之Chinese-LLaMA-Alpaca:基于单机CPU+Windows系统实现中文LLaMA算法进行模型部署(llama.cpp)+模型推理全流程步骤【安装环境+创建环境并安装依赖+原版L_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
https://yunyaniu.blog.csdn.net/article/details/131526139
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的chec-CSDN博客
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的che_一个处女座的程序猿的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-716390.html
LLMs之LLaMA2:基于LocalGPT利用LLaMA2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略
LLMs之LLaMA2:基于LocalGPT利用LLaMA2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA2:基于云端进行一键部署对LLaMA2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数据集【datasets】→加载模型【transformers】→分词→模型训练【peft+SFTTrainer+wandb】→基于HuggingFace实现云端分享)之图文教程详细攻略
LLMs之LLaMA2:基于云端进行一键部署对LLaMA2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时微调LLaMA2模型(采用Conda环境安装tg webui+PyTorch→CLI/GUI下载模型→启动WebUI服务→GUI式+LoRA微调→加载推理)之图文教程详细攻略
LLMs之LLaMA2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时_一个处女座的程序猿的博客-CSDN博客
Chinese-LLaMA-Alpaca-2的简介

本项目推出了基于Llama-2的中文LLaMA-2以及Alpaca-2系列模型,相比一期项目其主要特点如下:
| 经过优化的中文词表 |
在一期项目中,我们针对一代LLaMA模型的32K词表扩展了中文字词(LLaMA:49953,Alpaca:49954) 在本项目中,我们重新设计了新词表(大小:55296),进一步提升了中文字词的覆盖程度,同时统一了LLaMA/Alpaca的词表,避免了因混用词表带来的问题,以期进一步提升模型对中文文本的编解码效率 |
| 基于FlashAttention-2的高效注意力 |
FlashAttention-2是高效注意力机制的一种实现,相比其一代技术具有更快的速度和更优化的显存占用; 当上下文长度更长时,为了避免显存爆炸式的增长,使用此类高效注意力技术尤为重要; 本项目的所有模型均使用了FlashAttention-2技术进行训练; |
| 基于PI和NTK的超长上下文扩展技术 |
在一期项目中,我们实现了基于NTK的上下文扩展技术,可在不继续训练模型的情况下支持更长的上下文; 基于位置插值PI和NTK等方法推出了长上下文版模型,支持16K上下文,并可通过NTK方法最高扩展至24K-32K; 进一步设计了方便的自适应经验公式,无需针对不同的上下文长度设置NTK超参,降低了使用难度; |
| 简化的中英双语系统提示语 |
在一期项目中,中文Alpaca系列模型使用了Stanford Alpaca的指令模板和系统提示语; 初步实验发现,Llama-2-Chat系列模型的默认系统提示语未能带来统计显著的性能提升,且其内容过于冗长; 本项目中的Alpaca-2系列模型简化了系统提示语,同时遵循Llama-2-Chat指令模板,以便更好地适配相关生态; |
| 地址 |
GitHub地址:GitHub - ymcui/Chinese-LLaMA-Alpaca-2: 中文LLaMA-2 & Alpaca-2大模型二期项目 + 16K超长上下文模型 (Chinese LLaMA-2 & Alpaca-2 LLMs, including 16K long context models) |
| 时间 |
2023年07月31日 |
| 作者 |
哈工大讯飞联合实验室 |
1、已开源的模型
基座模型:Chinese-LLaMA-2-7B, Chinese-LLaMA-2-13B
聊天模型:Chinese-Alpaca-2-7B, Chinese-Alpaca-2-13B
长上下文模型:Chinese-LLaMA-2-7B-16K, Chinese-LLaMA-2-13B-16K, Chinese-Alpaca-2-7B-16K, Chinese-Alpaca-2-13B-16K
2、可视化本项目以及一期项目推出的所有大模型之间的关系

3、效果评估
为了评测相关模型的效果,本项目分别进行了生成效果评测和客观效果评测(NLU类),从不同角度对大模型进行评估。需要注意的是,综合评估大模型能力仍然是亟待解决的重要课题,单个数据集的结果并不能综合评估模型性能。推荐用户在自己关注的任务上进行测试,选择适配相关任务的模型。
(1)、生成效果评测
为了更加直观地了解模型的生成效果,本项目仿照Fastchat Chatbot Arena推出了模型在线对战平台,可浏览和评测模型回复质量。对战平台提供了胜率、Elo评分等评测指标,并且可以查看两两模型的对战胜率等结果。题库来自于一期项目人工制作的200题,以及在此基础上额外增加的题目。生成回复具有随机性,受解码超参、随机种子等因素影响,因此相关评测并非绝对严谨,结果仅供晾晒参考,欢迎自行体验。部分生成样例请查看examples目录。
⚔️ 模型竞技场:http://llm-arena.ymcui.com
| 系统 | 对战胜率(无平局) ↓ | Elo评分 |
|---|---|---|
| Chinese-Alpaca-2-13B-16K | 86.84% | 1580 |
| Chinese-Alpaca-2-13B | 72.01% | 1579 |
| Chinese-Alpaca-Pro-33B | 64.87% | 1548 |
| Chinese-Alpaca-2-7B | 64.11% | 1572 |
| Chinese-Alpaca-Pro-7B | 62.05% | 1500 |
| Chinese-Alpaca-2-7B-16K | 61.67% | 1540 |
| Chinese-Alpaca-Pro-13B | 61.26% | 1567 |
| Chinese-Alpaca-Plus-33B | 31.29% | 1401 |
| Chinese-Alpaca-Plus-13B | 23.43% | 1329 |
| Chinese-Alpaca-Plus-7B | 20.92% | 1379 |
Note
以上结果截至2023年9月1日。最新结果请进入⚔️竞技场进行查看。
(2)、客观效果评测:C-Eval
C-Eval是一个全面的中文基础模型评估套件,其中验证集和测试集分别包含1.3K和12.3K个选择题,涵盖52个学科。实验结果以“zero-shot / 5-shot”进行呈现。C-Eval推理代码请参考本项目:📖GitHub Wiki
| LLaMA Models | Valid | Test | Alpaca Models | Valid | Test |
|---|---|---|---|---|---|
| Chinese-LLaMA-2-13B | 40.6 / 42.7 | 38.0 / 41.6 | Chinese-Alpaca-2-13B | 44.3 / 45.9 | 42.6 / 44.0 |
| Chinese-LLaMA-2-7B | 28.2 / 36.0 | 30.3 / 34.2 | Chinese-Alpaca-2-7B | 41.3 / 42.9 | 40.3 / 39.5 |
| Chinese-LLaMA-Plus-33B | 37.4 / 40.0 | 35.7 / 38.3 | Chinese-Alpaca-Plus-33B | 46.5 / 46.3 | 44.9 / 43.5 |
| Chinese-LLaMA-Plus-13B | 27.3 / 34.0 | 27.8 / 33.3 | Chinese-Alpaca-Plus-13B | 43.3 / 42.4 | 41.5 / 39.9 |
| Chinese-LLaMA-Plus-7B | 27.3 / 28.3 | 26.9 / 28.4 | Chinese-Alpaca-Plus-7B | 36.7 / 32.9 | 36.4 / 32.3 |
(3)、客观效果评测:CMMLU
CMMLU是另一个综合性中文评测数据集,专门用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的67个主题,共计11.5K个选择题。CMMLU推理代码请参考本项目:📖GitHub Wiki
| LLaMA Models | Test (0/few-shot) | Alpaca Models | Test (0/few-shot) |
|---|---|---|---|
| Chinese-LLaMA-2-13B | 38.9 / 42.5 | Chinese-Alpaca-2-13B | 43.2 / 45.5 |
| Chinese-LLaMA-2-7B | 27.9 / 34.1 | Chinese-Alpaca-2-7B | 40.0 / 41.8 |
| Chinese-LLaMA-Plus-33B | 35.2 / 38.8 | Chinese-Alpaca-Plus-33B | 46.6 / 45.3 |
| Chinese-LLaMA-Plus-13B | 29.6 / 34.0 | Chinese-Alpaca-Plus-13B | 40.6 / 39.9 |
| Chinese-LLaMA-Plus-7B | 25.4 / 26.3 | Chinese-Alpaca-Plus-7B | 36.8 / 32.6 |
(3)、长上下文版模型(16K)评测
LongBench是一个大模型长文本理解能力的评测基准,由6大类、20个不同的任务组成,多数任务的平均长度在5K-15K之间,共包含约4.75K条测试数据。以下是本项目16K系列模型在该中文任务(含代码任务)上的评测效果。LongBench推理代码请参考本项目:📖GitHub Wiki
| Models | 单文档QA | 多文档QA | 摘要 | Few-shot学习 | 代码补全 | 合成任务 | Avg |
|---|---|---|---|---|---|---|---|
| Chinese-Alpaca-2-13B-16K | 48.1 | 26.0 | 12.8 | 23.3 | 45.5 | 21.5 | 29.5 |
| Chinese-Alpaca-2-13B | 38.4 | 20.0 | 12.2 | 18.0 | 46.2 | 9.0 | 24.0 |
| Chinese-Alpaca-2-7B-16K | 46.6 | 23.6 | 14.5 | 29.0 | 47.1 | 9.0 | 28.3 |
| Chinese-Alpaca-2-7B | 32.0 | 17.2 | 11.5 | 21.5 | 48.8 | 5.0 | 22.7 |
| Chinese-LLaMA-2-13B-16K | 37.3 | 18.1 | 3.4 | 30.8 | 13.0 | 3.0 | 17.6 |
| Chinese-LLaMA-2-13B | 26.7 | 14.0 | 4.4 | 16.3 | 9.8 | 5.5 | 12.8 |
| Chinese-LLaMA-2-7B-16K | 33.7 | 16.5 | 5.3 | 24.3 | 9.9 | 4.2 | 15.6 |
| Chinese-LLaMA-2-7B | 20.7 | 14.5 | 6.5 | 12.8 | 11.5 | 5.3 | 11.9 |
(4)、量化效果评测
以Chinese-LLaMA-2-7B为例,对比不同精度下的模型大小、PPL(困惑度)、C-Eval效果,方便用户了解量化精度损失。PPL以4K上下文大小计算,C-Eval汇报的是valid集合上zero-shot和5-shot结果。
| 精度 | 模型大小 | PPL | C-Eval |
|---|---|---|---|
| FP16 | 12.9 GB | 9.373 | 28.2 / 36.0 |
| 8-bit量化 | 6.8 GB | 9.476 | 26.8 / 35.4 |
| 4-bit量化 | 3.7 GB | 10.132 | 25.5 / 32.8 |
特别地,以下是在llama.cpp下不同量化方法的评测数据,供用户参考,速度以ms/tok计,测试设备为M1 Max。具体细节见📖GitHub Wiki
| llama.cpp | F16 | Q2_K | Q3_K | Q4_0 | Q4_1 | Q4_K | Q5_0 | Q5_1 | Q5_K | Q6_K | Q8_0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PPL | 9.128 | 11.107 | 9.576 | 9.476 | 9.576 | 9.240 | 9.156 | 9.213 | 9.168 | 9.133 | 9.129 |
| Size | 12.91G | 2.41G | 3.18G | 3.69G | 4.08G | 3.92G | 4.47G | 4.86G | 4.59G | 5.30G | 6.81G |
| CPU Speed | 117 | 42 | 51 | 39 | 44 | 43 | 48 | 51 | 50 | 54 | 65 |
| GPU Speed | 53 | 19 | 21 | 17 | 18 | 20 | x | x | 25 | 26 | x |
Chinese-LLaMA-Alpaca-2的安装
1、下载模型
1.1、模型选择指引
以下是中文LLaMA-2和Alpaca-2模型的对比以及建议使用场景。如需聊天交互,请选择Alpaca而不是LLaMA。
| 对比项 | 中文LLaMA-2 | 中文Alpaca-2 |
|---|---|---|
| 模型类型 | 基座模型 | 指令/Chat模型(类ChatGPT) |
| 已开源大小 | 7B、13B | 7B、13B |
| 训练类型 | Causal-LM (CLM) | 指令精调 |
| 训练方式 | LoRA + 全量emb/lm-head | LoRA + 全量emb/lm-head |
| 基于什么模型训练 | 原版Llama-2(非chat版) | 中文LLaMA-2 |
| 训练语料 | 无标注通用语料(120G纯文本) | 有标注指令数据(500万条) |
| 词表大小[1] | 55,296 | 55,296 |
| 上下文长度[2] | 标准版:4K(12K-18K) 长上下文版:16K(24K-32K) |
标准版:4K(12K-18K) 长上下文版:16K(24K-32K) |
| 输入模板 | 不需要 | 需要套用特定模板[3],类似Llama-2-Chat |
| 适用场景 | 文本续写:给定上文,让模型生成下文 | 指令理解:问答、写作、聊天、交互等 |
| 不适用场景 | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
Note
[1] 本项目一代模型和二代模型的词表不同,请勿混用。二代LLaMA和Alpaca的词表相同。
[2] 括号内表示基于NTK上下文扩展支持的最大长度。
[3] Alpaca-2采用了Llama-2-chat系列模板(格式相同,提示语不同),而不是一代Alpaca的模板,请勿混用。
1.2、完整模型下载
以下是完整版模型,直接下载即可使用,无需其他合并步骤。推荐网络带宽充足的用户。
| 模型名称 | 类型 | 大小 | 下载地址 |
|---|---|---|---|
| Chinese-LLaMA-2-13B | 基座模型 | 24.7 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-7B | 基座模型 | 12.9 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-13B | 指令模型 | 24.7 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-7B | 指令模型 | 12.9 GB | [百度] [Google] [🤗HF] |
以下是长上下文版模型,推荐以长文本为主的下游任务使用,否则建议使用上述标准版。
| 模型名称 | 类型 | 大小 | 下载地址 |
|---|---|---|---|
| Chinese-LLaMA-2-13B-16K | 基座模型 | 24.7 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-7B-16K | 基座模型 | 12.9 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-13B-16K 🆕 | 指令模型 | 24.7 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-7B-16K 🆕 | 指令模型 | 12.9 GB | [百度] [Google] [🤗HF] |
Important
使用长上下文模型推理时,必须按照文档要求进行设置,具体请参考各推理部署工具的Wiki。
1.3、LoRA模型下载
以下是LoRA模型(含emb/lm-head),与上述完整模型一一对应。需要注意的是LoRA模型无法直接使用,必须按照教程与重构模型进行合并。推荐网络带宽不足,手头有原版Llama-2且需要轻量下载的用户。
| 模型名称 | 类型 | 合并所需基模型 | 大小 | LoRA下载地址 |
|---|---|---|---|---|
| Chinese-LLaMA-2-LoRA-13B | 基座模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-LoRA-7B | 基座模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-13B | 指令模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-7B | 指令模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
以下是长上下文版模型,推荐以长文本为主的下游任务使用,否则建议使用上述标准版。
| 模型名称 | 类型 | 合并所需基模型 | 大小 | LoRA下载地址 |
|---|---|---|---|---|
| Chinese-LLaMA-2-LoRA-13B-16K | 基座模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-LLaMA-2-LoRA-7B-16K | 基座模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-13B-16K 🆕 | 指令模型 | Llama-2-13B-hf | 1.5 GB | [百度] [Google] [🤗HF] |
| Chinese-Alpaca-2-LoRA-7B-16K 🆕 | 指令模型 | Llama-2-7B-hf | 1.1 GB | [百度] [Google] [🤗HF] |
(1)、LoRA模型无法单独使用,必须与原版Llama-2进行合并才能转为完整模型
Important
LoRA模型无法单独使用,必须与原版Llama-2进行合并才能转为完整模型。请通过以下方法对模型进行合并。
- 在线转换:Colab用户可利用本项目提供的notebook进行在线转换并量化模型
- 手动转换:离线方式转换,生成不同格式的模型,以便进行量化或进一步精调
2、模型训练与精调
2.1、预训练:基于deepspeed框架+Llama-2增量训练+采用120G纯文本+ 启用FlashAttention-2,默认fp16训练
- 在原版Llama-2的基础上,利用大规模无标注数据进行增量训练,得到Chinese-LLaMA-2系列基座模型
- 训练数据采用了一期项目中Plus版本模型一致的数据,其总量约120G纯文本文件
- 训练代码参考了🤗transformers中的run_clm.py,使用方法见📖预训练脚本Wiki
(1)、训练步骤
训练脚本:scripts/training/run_clm_pt_with_peft.py
进入项目的scripts/training目录,运行bash run_pt.sh进行指令精调,默认使用单卡。运行前用户应先修改脚本并指定相关参数,脚本中的相关参数值仅供调试参考。run_pt.sh的内容如下:
部分参数的解释如下:
-
--dataset_dir: 预训练数据的目录,可包含多个以txt结尾的纯文本文件 -
--data_cache_dir: 指定一个存放数据缓存文件的目录 -
--flash_attn: 启用FlashAttention-2加速训练 -
--load_in_kbits: 可选择参数为16/8/4,即使用fp16或8bit/4bit量化进行模型训练,默认fp16训练。
这里列出的其他训练相关超参数,尤其是学习率以及和total batch size大小相关参数仅供参考。请在实际使用时根据数据情况以及硬件条件进行配置。
########参数设置########
lr=2e-4
lora_rank=64
lora_alpha=128
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05
pretrained_model=path/to/hf/llama-2/dir
chinese_tokenizer_path=path/to/chinese/llama-2/tokenizer/dir
dataset_dir=path/to/pt/data/dir
data_cache=temp_data_cache_dir
per_device_train_batch_size=1
gradient_accumulation_steps=1
output_dir=output_dir
block_size=512
deepspeed_config_file=ds_zero2_no_offload.json
########启动命令########
torchrun --nnodes 1 --nproc_per_node 1 run_clm_pt_with_peft.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--data_cache_dir ${data_cache} \
--per_device_train_batch_size ${per_device_train_batch_size} \
--do_train \
--seed $RANDOM \
--fp16 \
--num_train_epochs 1 \
--lr_scheduler_type cosine \
--learning_rate ${lr} \
--warmup_ratio 0.05 \
--weight_decay 0.01 \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--save_steps 500 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--block_size ${block_size} \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--lora_rank ${lora_rank} \
--lora_alpha ${lora_alpha} \
--trainable ${lora_trainable} \
--modules_to_save ${modules_to_save} \
--lora_dropout ${lora_dropout} \
--torch_dtype float16 \
--load_in_kbits 16 \
--gradient_checkpointing \
--ddp_find_unused_parameters FalseLLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
https://yunyaniu.blog.csdn.net/article/details/132613501
(2)、支持的训练模式:基于原版LLaMA-2训练中文LLaMA-2 LoRA、基于中文LLaMA-2/Alpaca-2继续预训练(在新的LoRA上)
【务必仔细核对】 以下是脚本支持的训练模式,请根据相应情况传入model_name_or_path。本项目中LLaMA-2模型与Alpaca-2模型使用相同的tokenizer,不再进行区分。不支持未在表格中的模式,如要修改请自行debug。
| 用途 | model_name_or_path | tokenizer_name_or_path | 最终模型词表大小 |
|---|---|---|---|
| 基于原版LLaMA-2训练中文LLaMA-2 LoRA | 原版HF格式的LLaMA-2 | 中文LLaMA-2的tokenizer(55296) | 55296 |
| 基于中文LLaMA-2,在新的LoRA上继续预训练 | HF格式的完整中文LLaMA-2 | 中文LLaMA-2的tokenizer(55296) | 55296 |
| 基于中文Alpaca-2,在新的LoRA上继续预训练 | HF格式的完整中文Alpaca-2 | 中文LLaMA-2的tokenizer(55296) | 55296 |
(3)、关于显存占用:只训练LoRA参数、减小block_size、开启gradient_checkpointing(但会降速)
- 如果机器的显存比较紧张,可以删去脚本中的
--modules_to_save ${modules_to_save} \, 即不训练embed_tokens和lm_head(这两部分参数量较大),只训练LoRA参数。- 仅可在基于中文LLaMA-2或Alpaca-2的基础上训练时进行此操作
-
减小
block_size也可降低训练时显存占用,如可将block_size设置为256。 - 开启gradient_checkpointing可有效降低显存占用,但是会拖慢训练速度。
(4)、使用多机多卡训练
请参考以下启动方式:
torchrun \
--nnodes ${num_nodes} \
--nproc_per_node ${num_gpu_per_node}
--node_rank ${node_rank} \
--master_addr ${master_addr} \
--master_port ${master_port} \
run_clm_pt_with_peft.py \
--deepspeed ${deepspeed_config_file} \
...(5)、训练后文件整理
训练后的LoRA权重和配置存放于${output_dir}/pt_lora_model,可用于后续的合并流程。
2.2、指令精调:基于deepspeed框架+Chinese-LLaMA-2进行指令精调+500万条(Alpaca格式的json文件)+ 启用FlashAttention-2,默认fp16训练
- 在Chinese-LLaMA-2的基础上,利用有标注指令数据进行进一步精调,得到Chinese-Alpaca-2系列模型
- 训练数据采用了一期项目中Pro版本模型使用的指令数据,其总量约500万条指令数据(相比一期略增加)
- 训练代码参考了Stanford Alpaca项目中数据集处理的相关部分,使用方法见📖指令精调脚本Wiki
指令精调代码脚本:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/blob/main/scripts/training/run_clm_sft_with_peft.py
(0)、⚠️重要提示⚠️
-
该代码仅适用于特定PEFT版本,运行脚本前请依照requirements安装要求的依赖版本
-
如果使用其他版本的PEFT或修改部分训练参数设置(如不使用deepspeed),不能保证模型可以正常训练。
-
运行前确保拉取仓库最新版代码:
git pull
(1)、训练步骤
进入项目的scripts/training目录,运行bash run_sft.sh进行指令精调,默认使用单卡。运行前用户应先修改脚本并指定相关参数,脚本中的相关参数值仅供调试参考。run_sft.sh的内容如下:
其中一些参数的含义不言自明。部分参数的解释如下:
-
--tokenizer_name_or_path: Chinese-LLaMA-2 tokenizer所在的目录。⚠️ 本项目中LLaMA-2模型与Alpaca-2模型使用相同的tokenizer,不再进行区分。 -
--dataset_dir: 指令精调数据的目录,包含一个或多个以json结尾的Stanford Alpaca格式的指令精调数据文件 -
--validation_file: 用作验证集的单个指令精调文件,以json结尾,同样遵循Stanford Alpaca格式 -
--flash_attn: 启用FlashAttention-2加速训练 -
--load_in_kbits: 可选择参数为16/8/4,即使用fp16或8bit/4bit量化进行模型训练,默认fp16训练。
这里列出的其他训练相关超参数(尤其是学习率,以及和total batch size大小相关的参数)仅供参考。请在实际使用时根据数据情况以及硬件条件进行配置。
########参数部分########
lr=1e-4
lora_rank=64
lora_alpha=128
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05
pretrained_model=path/to/hf/llama-2/or/merged/llama-2/dir/or/model_id
chinese_tokenizer_path=path/to/chinese/llama-2/tokenizer/dir
dataset_dir=path/to/sft/data/dir
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=1
output_dir=output_dir
peft_model=path/to/peft/model/dir
validation_file=validation_file_name
max_seq_length=512
deepspeed_config_file=ds_zero2_no_offload.json
########启动命令########
torchrun --nnodes 1 --nproc_per_node 1 run_clm_sft_with_peft.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--per_device_train_batch_size ${per_device_train_batch_size} \
--per_device_eval_batch_size ${per_device_eval_batch_size} \
--do_train \
--do_eval \
--seed $RANDOM \
--fp16 \
--num_train_epochs 2 \
--lr_scheduler_type cosine \
--learning_rate ${lr} \
--warmup_ratio 0.03 \
--weight_decay 0 \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--evaluation_strategy steps \
--eval_steps 250 \
--save_steps 500 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--max_seq_length ${max_seq_length} \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--lora_rank ${lora_rank} \
--lora_alpha ${lora_alpha} \
--trainable ${lora_trainable} \
--modules_to_save ${modules_to_save} \
--lora_dropout ${lora_dropout} \
--torch_dtype float16 \
--validation_file ${validation_file} \
--peft_path ${peft_model} \
--load_in_kbitsStanford Alpaca数据集的格式如下:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
https://yunyaniu.blog.csdn.net/article/details/132958044
(2)、支持的训练模模式:基于Chinese-LLaMA-2 LoRA进行指令精调、基于Chinese-LLaMA-2训练全新的指令精调LoRA权重
该脚本支持以下训练模式。不支持未在表格中的模式,如要修改请自行debug。
| 模型 | model_name_or_path | peft_path | lora params |
|---|---|---|---|
| 基于Chinese-LLaMA-2 LoRA进行指令精调 | 原版HF格式的LLaMA-2 | Chinese-LLaMA-2 LoRA | 无需指定 |
| 基于Chinese-Alpaca-2 LoRA进行指令精调 | 原版HF格式的LLaMA-2 | Chinese-Alpaca-2 LoRA | 无需指定 |
| 基于Chinese-LLaMA-2训练全新的指令精调LoRA权重 | 完整(合并Chinese-LLaMA-2-LoRA后)的HF格式Chinese-LLaMA-2模型 | 勿提供此参数,并且从脚本中删除 --peft_path
|
需设置--lora_rank、--lora_alpha、--lora_dropout、--trainable和--modules_to_save参数 |
| 基于Chinese-Alpaca-2训练全新的指令精调LoRA权重 | 完整(合并Chinese-Alapca-2-LoRA后)的HF格式Chinese-Alpaca-2模型 | 勿提供此参数,并且从脚本中删除 --peft_path
|
需设置--lora_rank、--lora_alpha、--lora_dropout、--trainable和--modules_to_save参数 |
(3)、关于显存占用:只训练LoRA参数(单卡21G)、减小max_seq_length
- 默认配置训练llama,单卡24G会OOM,可以删去脚本中的
--modules_to_save ${modules_to_save} \, 即不训练embed_tokens和lm_head(这两部分参数量较大),只训练LoRA参数,单卡使用显存约21G。- 如果是在已有LoRA基础上继续微调,需要修改
peft_path下的adapter_config.json文件,改为"modules_to_save": null
- 如果是在已有LoRA基础上继续微调,需要修改
-
减小
max_seq_length也可降低训练时显存占用,可将max_seq_length设置为256或者更短。
(4)、使用多机多卡
请参考以下启动方式:
torchrun \
--nnodes ${num_nodes} \
--nproc_per_node ${num_gpu_per_node}
--node_rank ${node_rank} \
--master_addr ${master_addr} \
--master_port ${master_port} \
run_clm_sft_with_peft.py \
...(5)、训练后文件整理
训练后的LoRA权重和配置存放${output_dir}/sft_lora_model,可用于后续的合并流程。
3、推理与部署
本项目中的相关模型主要支持以下量化、推理和部署方式,具体内容请参考对应教程。
| 工具 | 特点 | CPU | GPU | 量化 | GUI | API | vLLM§ | 16K‡ | 教程 |
|---|---|---|---|---|---|---|---|---|---|
| llama.cpp | 丰富的量化选项和高效本地推理 | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ | link |
| 🤗Transformers | 原生transformers推理接口 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | link |
| Colab Demo | 在Colab中启动交互界面 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | link |
| 仿OpenAI API调用 | 仿OpenAI API接口的服务器Demo | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | link |
| text-generation-webui | 前端Web UI界面的部署方式 | ✅ | ✅ | ✅ | ✅ | ✅† | ❌ | ✅ | link |
| LangChain | 适合二次开发的大模型应用开源框架 | ✅† | ✅ | ✅† | ❌ | ❌ | ❌ | ✅ | link |
| privateGPT | 基于LangChain的多文档本地问答框架 | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ | link |
Note
† 工具支持该特性,但教程中未实现,详细说明请参考对应官方文档
‡ 指是否支持16K长上下文模型(需要第三方库支持自定义RoPE)
§ vLLM后端不支持16K长上下文模型
T1、llama.cpp:丰富的量化选项和高效本地推理
教程地址:llamacpp_zh · ymcui/Chinese-LLaMA-Alpaca-2 Wiki · GitHub
T2、Transformers:原生transformers推理接口
教程地址:
T3、Colab Demo:在Colab中启动交互界面
教程地址:
T4、仿OpenAI API调用:仿OpenAI API接口的服务器Demo
教程地址:
T5、text-generation-webui:前端Web UI界面的部署方式
教程地址:
T6、LangChain:适合二次开发的大模型应用开源框架
教程地址:
T7、privateGPT:基于LangChain的多文档本地问答框架
教程地址:privategpt_zh · ymcui/Chinese-LLaMA-Alpaca-2 Wiki · GitHub
Chinese-LLaMA-Alpaca-2的案例实战应用
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的che_一个处女座的程序猿的博客-CSDN博客
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的chec_一个处女座的程序猿的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-716390.html
到了这里,关于LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!