本文编写日期是:2023年4月. Python开发环境是Anaconda 3.10版本,具体Anaconda的安装这里就不赘述了,基础来的。建议先完整看完本文再试,特别是最后安装过程经验分享,可以抑制安装过程中一些奇怪的念头,减少走弯路。
目录
1. NVidia驱动安装
2. 安装CUDA Toolkit
3. 安装Tensorflow 2.10.1
4. 添加CUDNN加速包
5. 验证是否成功安装和调用GPU进行运算
6. 测试启用CUDNN加速器
7. Tensorflow 小结
8. 安装PyTorch
9. 检测PyTorch安装情况
10. PyTorch试运行
11. 安装过程经验分享和坑
文章来源地址https://www.toymoban.com/news/detail-716392.html
1. NVidia驱动安装
首先确定你的电脑是N卡,也是英伟达的显卡,否则本文就不用看了。
在官网找到最新的驱动下载安装。
官方驱动 | NVIDIA

安装过程略过,全选,C盘安装。
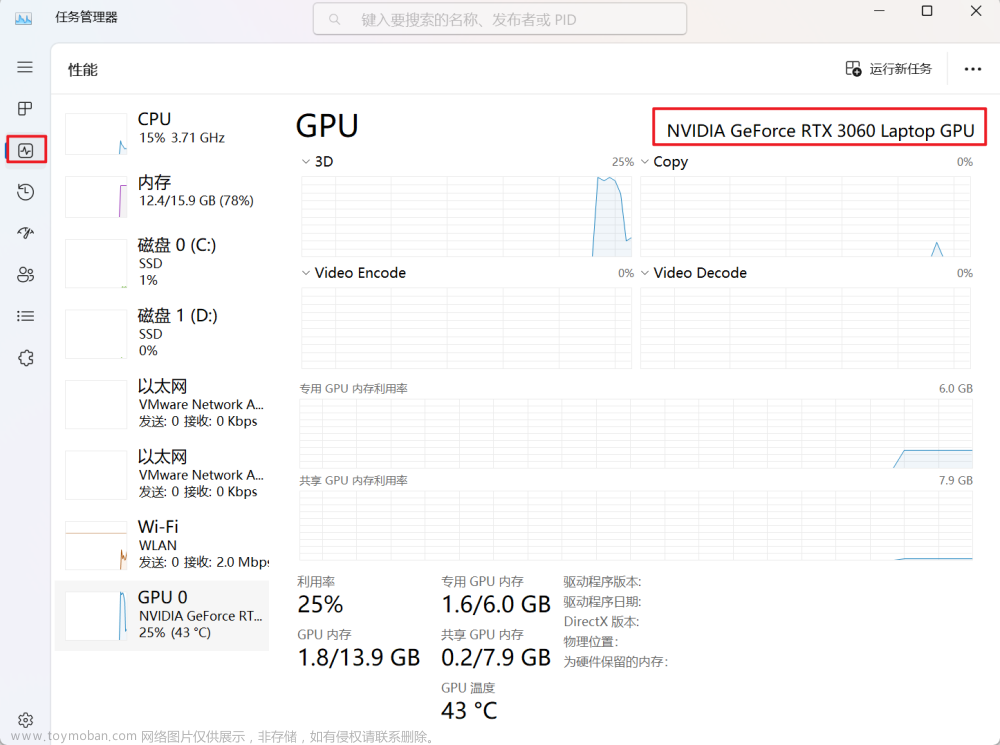
安装完成后,CMD运行nvidia-smi,查看这个驱动支持的最高版本CUDA

或者入NVIDIA的控制面板查看:
 也就是后面安装的CUDA版本,不能高于12.1
也就是后面安装的CUDA版本,不能高于12.1
2. 安装CUDA Toolkit
安装之前,最好先安装好Microsoft的 Visual Studio
安装 Visual Studio | Microsoft Learn

安装守后选好CUDA版本,此处是入口:CUDA 工具包下载

但是,先别急着下载安装,注意了!!!!!!!!!!!!!!!!!!!!!
如果运行的Tensorflow框架,那么要看最新的Tensorflow支持什么版本的CUDA,再进行安装。
(至于多版本CUDA同时共存的方法,可参考这位大佬的文章:CUDA版本共存方法
个人经验,不要急着研究多版本问题,后面有环境需求了,再慢慢看。)
回到Tensorflow支持的CUDA版本问题。
在本文件的发布时刻,Tensorflow在Native Windows系统下,目前只支持到Tensorflow 2.10.1版本。意思就是:暂时不要了解太多,就安装到Tensorflow 2.10.1版本就够用了(目前还有2.11等版本)。具体原因,请读回官方文档:Tensorflow版本安装
注意需要转回英文页面,中文实在被阉割太多了。实在看不明白,复制出来翻译吧。原因简而言之就是Windows开始进军开源,在原生系统(Native Windows)下,整合出了一个Windows WSL2功能,也就是在Windows系统内,整合了Linux系统的功能。相当于不用再为了两种系统,在机器上做双系统了,但实用性上来说,只能说,能用吧。具体关于WSL2的,网上有很多资料,此处不多说。参考另一大佬:WSL2的安装使用
对应Tensorflow 2.10.1的版本,目前支持到CUDA 11.8.0版本,下载CUDA Toolkit 11.8.0后默认C盘全选安装(我C盘很大,哈哈,我有两条990 1T SSD。其实是懒得自定义,后面也容易出错)。
3. 安装Tensorflow 2.10.1
如果以前安装过其他版本的tensorflow,强烈建议使用以下命令卸载:
pip uninstall tensorflow # 卸载旧版本的tensorflow
pip uninstall tensorflow-intel # 卸载intel版本的tensorflow,一般没有
pip uninstall tensorflow-gpu #卸载老的GPU版本
tensorflow从2.x版本后已将CPU版和GPU版进行合并,所以不要使用pip install tensorflow-gpu了,成功了也是旧版本的。这使用以下命令进行安装:
pip install tensorflow=2.10.1
这里不用conda安装,也不要添加国内的镜像源,原因后面会说,速度会比较慢,但值得等待!
4. 添加CUDNN加速包
下载CUDA 11.8.0 版本的cuDNN加速包,版本是V8.8.1 for CUDA 11.x 官方地址在:cuDNN下载地址
 下载后解压,将解压后的三个文件夹bin、lib、include复制到安装目录下,合并。
下载后解压,将解压后的三个文件夹bin、lib、include复制到安装目录下,合并。


配置环境变量

以上可以看到CUDA 11.8.0安装完成后,已经设置在环境变量公有路径。
接下来配置CUDA和CUDNN的路径,去到PATH变量名下,点击编辑:

添加如图中所示的环境变量V11_8的5个变量,缺一不可,这里用的是短地址,默认安装路径下,为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8
(对了,如果你看不到这个环境变量清单,只看到一行文本,那是因为你的第一个变量是个短地址,随便添加一个C:\或者把已有的长地址移到第一行,后保存重新打开就有了)
保存,建议重启电脑,可以先等会。
查算力,按照下图,CD到安装地址,运行deviceQuery.exe 。不要羡慕哥,没错,又在显摆4090了。

再运行 bandwidthTest.exe
以上两者都的结果都是PASS,则说明暂时配置成功。
5. 验证是否成功安装和调用GPU进行运算
1,如果以下代码运行得到如注释所示的结果,则证明安装成功。
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
#这一行输出至少是数量1,说明有1个显卡
print("CUDA Available:", tf.test.is_built_with_cuda())
#这一行要输出True
print("GPU Support:", tf.test.is_built_with_gpu_support())
#这一行也要输出True2,就算安装成功,也要运行一下以下代码,看计算过程会不会调用GPU:
tf.debugging.set_log_device_placement(True)
# Create some tensors
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
c = tf.matmul(a, b)
print(c)如果显示的是如下图CPU字样,就很遗憾了,4090也没得得瑟,调用的还是CPU。如果结果有下图2中的GPU字样,那么恭喜,一次成功。


如果没有成功,先不急,说明系统有旧的版本或者安装版本还是不对,需要重新装过,本人也是经历了几次才装成功。
6. 测试启用CUDNN加速器
以上,说明已经成功安装Tensorflow2.10.1,成功调用CUDA,但,还不知道能不能成功启用CUDNN加速器。所以,用以下代码进行测试:
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPool2D, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import TensorBoard
import time
from tensorflow.python.client import device_lib
def create_model():
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=[28, 28, 1]))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def compile_model(model):
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['acc'])
return model
def train_model(model, x_train, y_train, batch_size=128, epochs=10):
tbCallBack = TensorBoard(log_dir="model", histogram_freq=1, write_grads=True)
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2,validation_split=0.2, callbacks=[tbCallBack])
return history, model
if __name__ == "__main__":
print(tf.__version__)
print(device_lib.list_local_devices())
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test))
x_train = np.expand_dims(x_train, axis=3)
x_test = np.expand_dims(x_test, axis=3)
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test))
model = create_model()
model = compile_model(model)
print("start Time")
ts = time.time()
history, model = train_model(model, x_train, y_train, epochs=2)
print("Time consumption:", time.time() - ts)能够成功输出结果,则基本就是成功了。博主在跑这段程序的时候,Jupyter出现报错:The kernel appears to have died. It will restart automatically.

GPU也直接退出运算。

查看Jupyter后台,报错文为:Could not locate zlibwapi.dll. Please make sure it is in your library path!
查看官方文档,Installation Guide :: NVIDIA Deep Learning cuDNN Documentation ,意思是缺少zlibwapi.dll动态库文件,点击红色部分下载,但从Nvidia官网是无法成功下载的:

只能从Zlibdll官网下载:zlibwapi.dll下载,但是下载的时候要看清楚自己的系统是32位还是64位的,一般现在都是Intel EM64T,也就是英特尔64位系统, 点击下载。
下载后的文件如下:

分别复制文件到以下地址:
- zlibwapi.dll 复制到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
- zlibwapi.lib 复制到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib\x64
博主一开始因为下载成了32位的文件包,复制进去后运行报错:Could not load library zlibwapi.dll. Error code 193. 英文能力需要提升啊,There看成It.
7. Tensorflow 小结
以上是关于Tensorflow2.0在N卡上运行的具体配置,基本上是当前在原生Windows系统下,所能安装的最高版本的程序,各个程序的版本如下,一定要安装对版本:
- Tensorflow 2.10.1
- CUDAToolkit 11.8
- CUDNN 8.8.1
- Python 3.10 -- Anaconda
8. 安装PyTorch
接下来,安装另一个图像处理框架:PyTorch
前面设置对了,这个安装相对就比较顺利了,进入官网:PyTorch

按照自己的系统配置以及安装 的CUDA版本,运行安装即可:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1189. 检测PyTorch安装情况
接着运行检测程序:
import torch
print(torch.cuda.is_available())
print(torch.__version__)运行结果如下,说明PyTorch也成功调用显卡。

10. PyTorch试运行
再运行测试程序:
import time
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
device = torch.device("cuda")
train_data = torchvision.datasets.CIFAR10('../dataset', True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练集长度:{}, 测试集长度:{}".format(train_data_size, test_data_size))
# 用 DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = Model()
model.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
learning_rate = 0.01 # 1e-2 = 10^-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 设置训练网络的参数
total_train_step = 0 # 训练次数
total_test_step = 0 # 测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("--------------第{}轮训练开始---------------".format(i+1))
# 训练开始
model.train()
for data in train_dataloader:
if total_train_step % 100 == 1:
start_time = time.time()
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print("训练次数:{},loss:{:.3f},time:{:.3f}".format(total_train_step, loss.item(), end_time-start_time))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试开始
model.eval()
total_test_loss = 0
total_accuracy = 0 # 整体正确预测的个数
with torch.no_grad(): # 清空梯度
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("测试集上的平均loss: {:.3f}".format(total_test_loss/len(test_dataloader)))
print("整体测试集上的正确率:{:.3f}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# 保存训练模型
# torch.save(model, "../model_data/model_{}.pth".format(i+1))
if i % 100 == 0:
torch.save(model.state_dict(), "../model_data/model_{}.pth".format(i + 1))
print("模型已保存!")
writer.close()速度简直飞起:

11. 安装过程经验分享和坑
以上,就是所有的安装过程,其实过程并不像上面写的这么顺利:
1. 关于版本的问题由于一开始太过兴奋,直接下载了CUDA12.1安装,后面发现在Tensorflow2.10.1无法运行CUDA12.1,又下载了CUDA11.8,再后面又研究了怎么双版本CUDA,12.1与11.8的共存方法,并做了设置。 结果一直检测不到GPU。
2. 过程中还卸载了Tensorflow,重新安装 Tensorflow。还在pip和conda的安装方式下纠结。一开始安装的是Tensorflow2.10.0,卸载又重新安装,结果在重新安装过程中按了退出,导致整个Tensorflow的库坏掉,不得不重新来过。
3. 最后的解决方法是:先卸载CUDA 12.1,以及删除对应的复制的CUDNN文件,同时删除设置的环境变量。然后卸载Anaconda。清理一下清册表,重启。
4. 重新安装一次CUDA 11.8, 安装之前需要安装微软的Visual Studio.安装教程如安装 Visual Studio | Microsoft Learn
5. 重新安装pip 安装Tensorflow 2.10.1,个人不太喜欢用Conda安装,Anaconda有时没有最新的文件包,所以还是选择从Pypi源下载,但是速度超级慢,用了5个小时,开机过夜下载完的。这里特别要强调的是,对于这些比较大的而且停更的关键库,最好不要用国内镜像源,虽然飞快,但博主中间试过一次,还是会报错是的,库不完全。而且现在很多国内源对它停更了,即使是Tsinghua源也不能保证一定能行,比如以下玩法就失败了,显示成功安装,但调用不了。
pip install tensorflow==2.10.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
#选择国内清华Pypi源安装总结以上,对于无法调用GPU的问题,大多数还是各个程序的版本不对应,本文的版本匹配是博主亲测成功的。
对于网传还有这么一个Tensorflow, CUDAToolkit, CUDNN, Python版本的对应表,也是官网的版本对应表:Build from source on Windows | TensorFlow

其实这个对应表是针对上文提及的Tensorflow-gpu版本的,也就是旧的Tensorflow版本,在Tensorflow2.0版本中已经将gpu版本合并了,并不需要单独pip tensorflow-gpu。所以这里看到的CUDA及CUDNN版本都相对比较旧,其实按照这个版本安装理论上也是可行的,特别是针对一些旧的显卡。
另外,在一些英文教程中,还提到了直接conda 安装CUDA和CUDNN, 直接一行搞定,但前提也是要搞清楚各个程序的版本对应。相对来说就没有那么麻烦,不用下载CUDAToolkit手动安装以及CUDNN的配置,本人没有亲测过,不过在上一台独显笔记本电脑中,误打误撞安装上了,也是可行的,但Conda的库更新没那么及时,现在用以下语句安装的话,会报错找不到版本为8.8.1的cudnn包,降级cudnn的包版本也许可行,这里就不测试了,折腾几天终于可以跑了。
所以个人还是推荐手动安装CUDA和CUDNN。
conda install -c conda-forge cudatoolkit=11.8 cudnn=8.8.1文章来源:https://www.toymoban.com/news/detail-716392.html
到了这里,关于全网最新最全的基于Tensorflow和PyTorch深度学习环境安装教程: Tensorflow 2.10.1 加 CUDA 11.8 加 CUDNN8.8.1加PyTorch2.0.0的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!