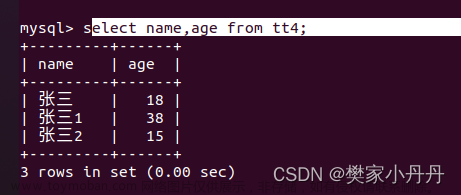
聚合查询:
下文中的所有聚合查询的示例操作都是基于此表:

聚合函数
聚合函数都是行与行之间的运算。
count()
select count(列名) from 表名;
统计该表中该列的行数,但是 null 值不会统计在内,但是如果写为 count(*) 那么 null 也会算进去(就算一整行都是 null 也会算进去)

例如我们暂时使用这个表进行演示:

此表有一行全为空


sum()
select sum(列名) from 表名;
只能针对数字类型使用,也可以对多列进行相加求一个总和;
对该表中的math列的值进行求和。
注:会将 null 值排除在外,不予计算。

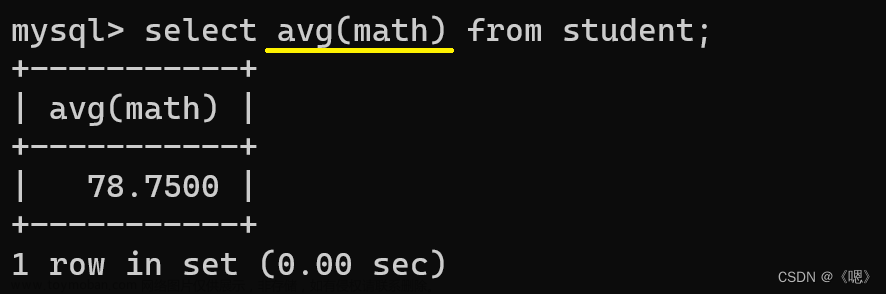
avg()
select avg(列名) from 表名;
对该表中的该列进行求平均值。
只能针对数字类型使用
注:会将 null 值排除在外,不予计算。
max()
select max(列名) from 表名;
求出该表中该列的最大值。
只能针对数字类型使用
注:会将 null 值排除在外,不予计算。

min()
select min(列名) from 表名;
求出该表中该列的最小值。
只能针对数字类型使用
注:会将 null 值排除在外,不予计算。

group by
group by 可以实现对数据进行分组。
一般的使用方法都是先用 group by 进行分组,然后再利用聚合函数进行聚合查询。
select * from 表名 group by 列名;
group by 会将该列中值相同的分为一组。因为没有使用order by 进行排序操作所以MySQL并不会对查询结果的顺序做出保证。

此时我们在原有表的基础上再加一行数据。

加入该条数据后该表变成了:

此时再进行分组查询操作:

此时因为没有使用聚合函数所以 张三这一行 只是在张三这一组中选了一个代表。

如果加入聚合函数就可以很清楚的看到,聚合函数会以每组为单位进行操作。

此时如果我们不想让某行(某几行)参与分组就可以在 group by 之前加入 where 进行条件筛选。
select * from 表名 where 条件 group by 列名;
例:此时我们不想让 null 这个空值和 math=100 的行参与分组

注意:where 条件 必须在 group by 之前
在后面就会报错。

having
having 其实和 where 差不多都是进行条件筛选的语句。
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用 having
having是对分组之后的数据进行筛选的。
例:此时我们不想让 null 这个空值和 成绩=100 的行参与分组

此时的语句执行顺序为:

所以 having 子句中的条件一定要和 select 中的对应

注:having 必须写在 group by 子句之后。

联合查询:
实际开发中往往数据来自不同的表,所以需要多表联合查询。
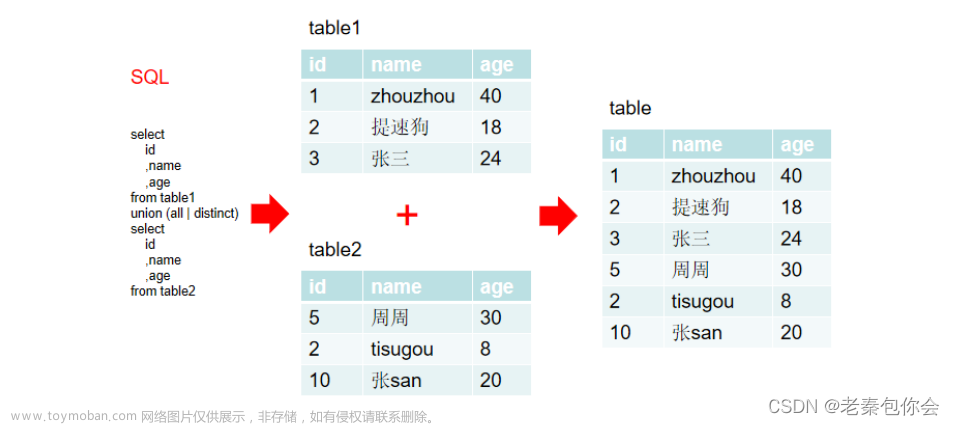
多表查询的关键是对多张表的数据取笛卡尔积:
下面我先简单介绍一下笛卡尔积,假设我们现在有如下的两张表。而对他们的数据取笛卡尔积就是用第一个表的每行数据分别与第二张表的每行数据进行组合。

这两张表进行笛卡尔积之后就变成了一个 9 行 4 列的新表,如图所示

这就是对两个表进行去取笛卡尔积的结果。
但是,我们很容易就可以发现这里面有非常多的所谓的非法数据,

从图中我们可以看到只有三条数据是合法的,而我们再进行数据库操作的时候肯定不能允许有这么多的非法数据出现在查询结果中,此时我们就可以通过寻找两张表的关联属性来通过 where 条件来进行筛选,比如上面的表就可以通过设置两张表的班级相同来进行筛选。
内连接
内连接其实就是在多张表中求交集(或者说就是最终查询的结果中的每条数据的链接条件都存在于原本的多张表中)。

此处为了更好的演示,我先创建了三张表



内连接的语句就这两条:
select 字段 from 表1 [inner] join 表2 on 连接条件 and 其他条件;
select 字段 from 表1 ,表2 where 连接条件 and 其他条件;
上面这些格式看着很复杂其实完全没有必要记这些。只要按照下面这些步骤一步一步的多练习几次就能掌握。
内连接本质上分为以下几步:
例:查询凌华的各科成绩。
第一步:先求出笛卡尔积
select * from 表一,表二,……
通过上述语句就可以求出多张表的笛卡尔积。

此时一共输出了27条数据。
第二步:加上连接条件,筛选出合法信息
此处推荐再写where中的条件时,使用 表名 点 列名 的写法因为表中可能会有相同的列名。

第三步:结合需求进一步增加条件,对结果进行筛选;
此处需要增加的条件就是名字是凌华。

第四步:对列进行精简,筛选出需要展示的列

此时你再对照开头的表达式就会发现一摸一样,基本上所有的内连接都可以套用这四大步。
select 字段 from 表1 [inner] join 表2 on 连接条件 and 其他条件;
select 字段 from 表1 ,表2 where 连接条件 and 其他条件;
注:第一条语句中的 [inner] join 中的 inner 之所以用 [] 括起来是因为可以省略不写。
外连接
如果多张表中的信息都存在对应关系那么内连接和外连接的结果就都是一样的,如果表中的数据不对应内外连接就会出现差别。
外连接分为左外连接和右外连接。
例:有如下两张数据没有完全对应的表


左外连接

select 字段 from 表1 left join 表2 on 连接条件 and 其他条件;
这个表达式除了 left 之外和内连接都是相同的。

左外连接就是以左表为基础,如果左表有右表没有那么就用 null 代替。
右外连接

select 字段 from 表1 right join 表2 on 连接条件 and 其他条件;
这个表达式除了 right 之外和左外连接都是相同的。

右外连接就是以右表为基础,如果右表有左表没有那么就用 null 代替。
自连接
自连接就是自己和自己取笛卡尔积,和内连接的解题方法相同。
注:在自连接中必须要给表取别名否则会报错。

自连接的优点:可以将行与行之间的关系转换成列与列。
例:在上述表中查询出 C++ 成绩大于单片机成绩的人。

子查询
子查询本质上就是‘套娃’,就是将多个简单的sql语句嵌套成一个复杂的sql语句。
例:查找出名为可莉的学生在几年级。
1.先找出可莉的班级号

2.根据班级号在班级表中找到班级名

而子查询就是将这两句sql语句嵌套起来

合并查询
合并查询是通过 union 来实现的
在MySQl中可以通过 union 来将多个表的查询结果合并成一张表。
注:合并的两个结果的对应列之间列数和数据类型必须相同(列名系统会自动按照第一个表的列名),union 会去掉结果中的重复项。


例如查询这两张表中的 id 和 name 结果返回一张表;

在这张结果中只有一个 id = 1 的学生。
如果你不想对结果进行去重处理,就可以使用 union all

如果对同一张表使用 union 那么它的结果会和使用 or 相同。
 文章来源:https://www.toymoban.com/news/detail-716405.html
文章来源:https://www.toymoban.com/news/detail-716405.html
 文章来源地址https://www.toymoban.com/news/detail-716405.html
文章来源地址https://www.toymoban.com/news/detail-716405.html
到了这里,关于MySQL --- 聚合查询 和 联合查询的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!