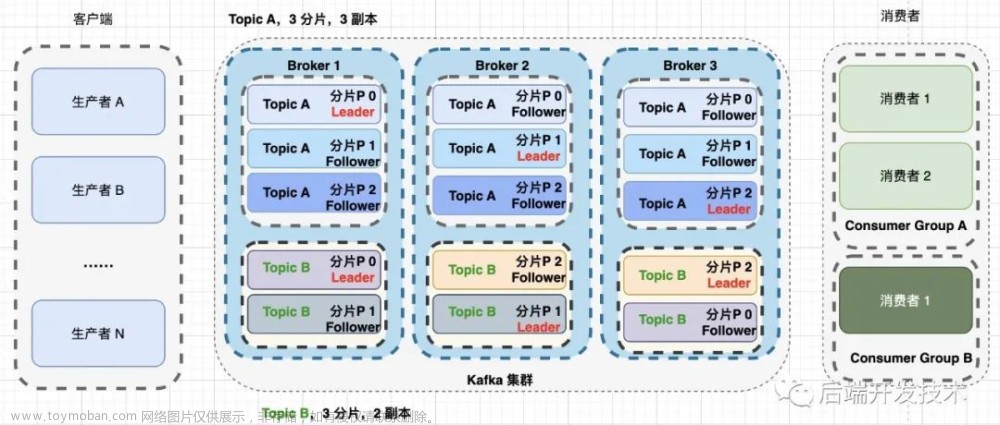
一、leader和follower
在Kafka中,每个topic都可以配置多个分区以及多个副本。每个分区都有一个leader以及0个或者多个follower。在创建topic时,Kafka会将每个分区的leader均匀地分配在每个broker上。使用Kafka时,是感觉不到leader和follower存在的。
- Kafka中的leader负责处理读写操作,而follower只是负责副本数据的同步
- 如果leader出现故障,其他follower会被重新选举为leader
- follower像是一个消费者,不断拉取对应分区的leader数据,并保存到日志数据文件中


二、AR、ISR、OSR
- AR(Assigned Replica 已分配的副本):表示某个分区的所有副本
- ISR(In-Sync-Replica 在同步中的副本):表示所有与leader副本保持一定程度同步的副本(包括leader副本在内)
- OSR(Out-of-Sync-Replica 不在同步中的副本):表示所有与leader副本同步滞后过多的follower副本(不包括leader副本)
- AR = ISR + OSR
- 正常情况下,所有的follower副本都应该与leader副本保持同步,即:AR = ISR,OSR集合为空

四、leader选举
1. Controller的介绍
- Kafka启动时,会在所有的broker(集群节点)中选择一个controller
- 之前的leader和follower是针对分区而言的,而controller是针对broker的
- 创建topic、添加分区、修改副本数量等管理任务都是由controller完成的
- Kafka分区leader的选举,也是有controller决定的
2. Controller的选举
- 在Kafka集群启动时,每个broker都会常识去ZooKeeper上注册成为Controller(ZK临时节点)
- 只会有一个broker竞争成功,其他的broker会注册该节点的监视器,一旦该临时节点状态发生变化,就可以进行相应的处理
- Controller是高可用的,一旦某个broker崩溃,其他的broker会重新注册成为Controller

3. Controller选举分区leader
- 所有分区的leader选举都是由controller决定的
- controller会将leader的改变直接通过RPC的方式通知需为此做出响应的broker
- controller读取到当前分区的ISR,只有一个replica存活时,就选择这个replica作为leader,否则任意选择一个replica作为leader
- 如果该分区的所有replica都已经宕机,则新的leader为-1
4. 为什么不通过ZK的方式选举分区的leader?
- Kafka集群如果业务很多的情况下,会存在很多的分区
- 假设某个broker宕机,就会出现很多的分区都需要重新选举leader
- 如果使用zookeeper选举leader,会给zk带来巨大的压力。因此,Kafka中leader的选举不能使用zk来实现
五、leader负载均衡
如果某个broker崩溃之后,就可能导致分区的leader分布不均匀,就是说一个broker上存在一个topic下不同分区的leader
1. Prefered Replica
- Kafka中引入了一个叫做【prefered replica】概念,即:优先的replica
- 在ISR列表中,第一个replica就是prefered replica
2. 重新分配分区leader
 文章来源:https://www.toymoban.com/news/detail-716571.html
文章来源:https://www.toymoban.com/news/detail-716571.html

 文章来源地址https://www.toymoban.com/news/detail-716571.html
文章来源地址https://www.toymoban.com/news/detail-716571.html
到了这里,关于【Kafka原理】分区的leader和follower的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!