在网络时代,爬虫作为一种强大的数据采集工具,被广泛应用于各行各业。然而,许多网站为了防止被恶意爬取数据,采取了各种反爬虫机制。为了能够成功地绕过这些机制,Selenium成为了爬虫领域的一把利器。本文将为你介绍爬虫入门基础,并重点探讨如何使用Selenium应对反爬虫的挑战。

一、爬虫入门基础
1、定义:爬虫是一种模拟浏览器行为自动化访问网络文档的程序,用于提取网页数据。
2、需要的基础知识:HTTP协议、HTML基础、编程语言(如Python)基础等。
二、反爬虫机制简介
1、Robots.txt文件:网站通过Robots.txt文件告知爬虫哪些页面可以访问,哪些页面应该忽略。
2、User-Agent限制:网站服务器通过检查请求的User-Agent来判断是否为爬虫,并采取相应措施拒绝访问。
3、IP封锁:网站根据IP地址对大量请求进行封锁,阻止爬虫访问。
4、验证码:网站通过验证码等方式验证访问者的人类身份。
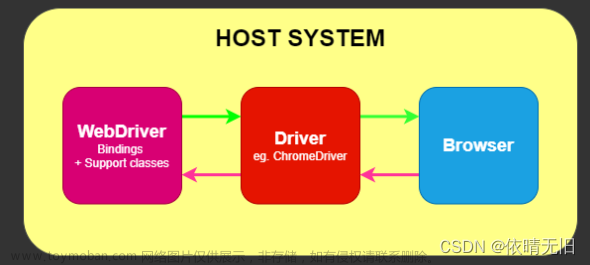
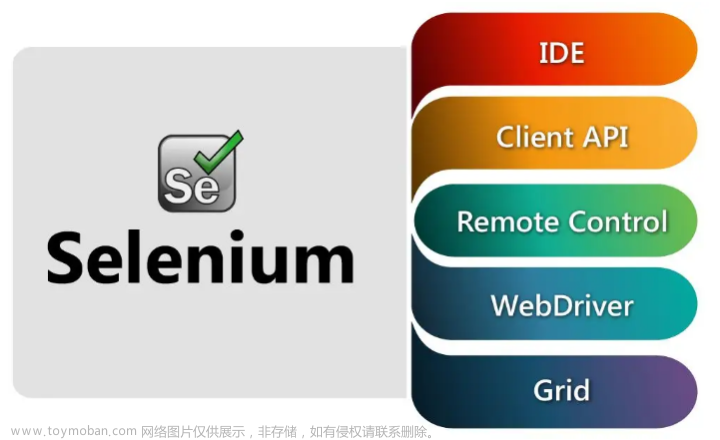
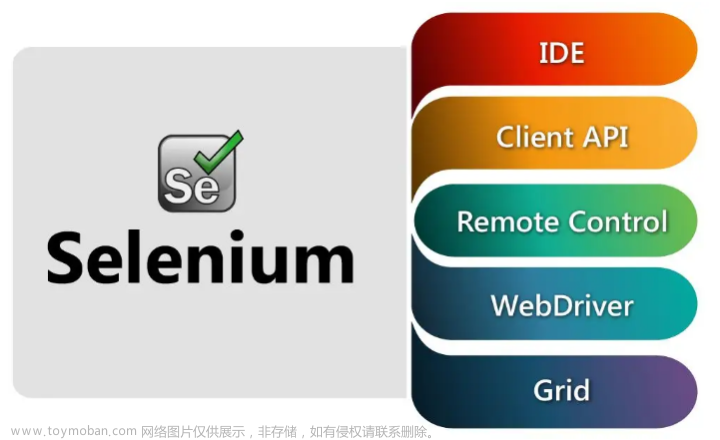
三、Selenium简介
1、定义:Selenium是一套用于自动化浏览器操作的工具,可以模拟用户在浏览器中的操作,实现网页的完全加载和渲染。
2、优势:通过使用Selenium,我们可以绕过一些简单的反爬虫机制,如User-Agent限制和部分简单的验证码。
3、使用步骤:安装Selenium库,配置浏览器驱动,编写代码实现自动化操作。
四、应对反爬虫的Selenium策略
1、修改User-Agent:在Selenium中,我们可以自定义User-Agent,模拟浏览器的不同版本,来绕过User-Agent检测。
2、处理验证码:尝试使用第三方工具库(如Tesseract OCR)对验证码进行识别,并通过Selenium注入识别结果。
五、Selenium的局限性和注意事项
1、性能损耗:Selenium模拟浏览器操作需要使用更多的计算资源,可能导致爬取速度较慢。
2、不适用于动态网页:对于使用JavaScript动态渲染的网站,Selenium的能力有限。
3、隐私和法律问题:在使用Selenium进行爬取时,务必遵守相关网站的爬虫政策,并确保不侵犯他人的隐私和法律规定。文章来源:https://www.toymoban.com/news/detail-716773.html
通过本文的介绍,你已经了解了爬虫入门基础知识,并掌握了Selenium作为应对反爬虫机制的利器。Selenium的灵活性和自动化操作能力为我们在爬取数据过程中提供了强大的支持。在实际应用中,我们需要根据具体的场景选择合适的策略,并遵守相关法律和道德规范。希望本文对你的爬虫学习之旅有所帮助。如果你有任何问题或需要进一步了解,欢迎评论区随时与我交流。文章来源地址https://www.toymoban.com/news/detail-716773.html
到了这里,关于爬虫入门基础-Selenium反爬的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!