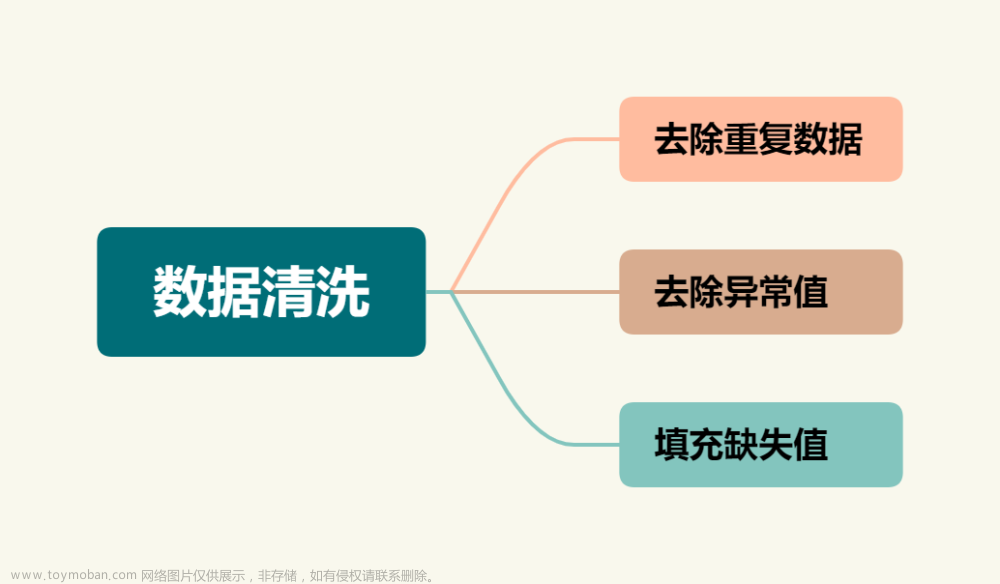
0 提纲
- 噪声相关概述
- 噪声处理的理论与方法
- 基于数据清洗的噪声过滤
- 主动式过滤
- 噪声鲁棒模型
1 噪声相关概述
噪声是影响机器学习算法有效性的重要因素之一,由于实际数据集存在采集误差、主观标注以及被恶意投毒等许多因素,使得所构造的数据集中难免存在噪声。
在机器学习训练数据中,存在两种噪声:
- 属性噪声:样本中某个属性的值存在噪声。由于设备、数据处理方法等因素影响,在每个属性或特征的测量、处理的过程中会引入噪声。例如,测量血压、温度时由于突发因素的影响造成波动;
- 标签噪声:由于人工标注时存在一定主观性、非专业性、经验不足等,导致数据集中的样本标签可能存在一定噪声。
标签噪声的产生原因:
- (1)特定类别的影响,在给定的标注任务中,各个类别样本之间的区分度不同,有的类别与其他类别都比较相似,就会导致这类样本标注错误率高;
- (2)标注人为的因素;
- (3)少数类的标注更容易错误;
- (4)训练数据受到了恶意投毒,当在对抗环境下应用机器学习模型时,攻击者往往会通过一些途径向数据中注入恶意样本,扰乱分类器的性能。
关于噪声分布的假设:均匀分布、高斯分布、泊松分布等。
噪声标签的影响:
- 标签噪声比属性噪声更重要;
- 数据利用率;
- 分类性能下降: k k kNN、决策树和支持向量机、 Boosting 等;
- 模型复杂度:
– 决策树节点增多;
– 为了降低噪声影响,需要增加正确样本数量;
– 可能导致非平衡数据。 - 正面影响:Bagging训练数据中的噪声有利于增加基分类器的差异性,最终可能提高整个学习模型的分类性能。
与噪声类似的概念和研究:
- 异常
- 离群点:outlier
- 少数类
- 小样本
- 对抗样本
- 恶意样本
- 脏数据
2 噪声处理的理论与方法
2.1 噪声处理的理论基础
概率近似正确定理(probably approximately correct,PAC ):只要计算结果和真实值的偏差小于一个足够小的值就认为“近似正确”,因此PAC理论不要求学习器输出零错误率,只要求错误率被限制在某常数 ϵ \epsilon ϵ范围内。
根据PAC理论,有一个已经被证明的结论:对于任意的学习算法而言,假设训练数据的噪声率为
β
\beta
β,分类器的错误率为
ϵ
\epsilon
ϵ,那么两者之间存在如下关系:
β
≤
ϵ
1
+
ϵ
.
\beta \leq \frac{\epsilon}{1 + \epsilon}.
β≤1+ϵϵ.
下图给出了噪声率和错误率之间的变化关系(横坐标是噪声率,纵坐标是错误率),从图中可以看出,机器学习允许训练数据存在一定的噪声。但当噪声率超过
50
%
50\%
50%时,分类器已经
100
%
100\%
100%的错误率了。基于这个出发点,在噪声数据处理中,一般假设噪声比例并不太高。
2.2 噪声处理的方法概览
- 基于数据清洗的噪声过滤
- 主动式噪声过滤
- 噪声鲁棒模型
3 基于数据清洗的噪声过滤
数据层
- 去除噪声样本
- 修正噪声样本
- 方法:采用噪声敏感方法检测噪声
– k k kNN, k k k较小
– 密度方法
– 决策树
– 集成学习:静态集成、动态集成;投票
– 主动学习:人工+分类器迭代
3.1 直接删除
直接删除法是基于两种情况:
- 把异常值影响较大或看起来比较可疑的实例删除;
- 或者直接删除分类器中分类错误的训练实例。
在具体实现方法上,如何判断异常值、可疑等特征,可以使用边界点发现之类的方法。
缺点:容易造成数据样本数量减少,特别是对于训练样本本来就少的应用或是非平衡分类问题。
3.2 基于最近邻的去噪方法
- 从 k k kNN本身原理来看,当 k k k比较小的时候,分类结果与近邻的样本标签关系很大。当发现若干样本分类错误都是由同一邻居引起的,则认为这个邻居样本可能是噪声;
- k k kNN( k k k较小)是一种典型的噪声敏感模型,在噪声过滤中有一定优势;
- 压缩最近邻CNN、缩减最近邻RNN、基于实例选择的Edited Nearest Neighbor等,也都可以用于噪声过滤。
3.3 集成去噪
集成分类方法对若干个弱分类器进行组合,根据结果的一致性来判断是否为噪声,也是一种较好的标签去噪方法。
对于给定的标签数据集,如何排除其中的噪声样本?主要的问题是集成分类器的选择和训练。根据所使用的训练数据,可以分为以下两类处理方法:
- 使用具有相同分布的其他数据集,该数据集是一个干净、没有噪声的数据。
- 不使用外部数据集,而是直接使用给定的标签数据集进行 K K K折交叉分析。

对于每一组划分得到数据集,分别训练基分类器,然后对于相应的测试集进行噪声检测。检测的方法有两种:
- 对于一致投票而言,当所有的基分类器都同意删除某个样本时(也就是所有的基分类器都错分了该样本),它会被删除;
- 对于多数投票,超过半数的基分类器错分的样本可视为标签噪声样本。
4 主动式过滤
主动式过滤:
- 基于数据清洗的噪声过滤方法的隐含假设是噪声是错分样本,把噪声和错分样本等同起来。
- 位于分类边界的噪声最难于处理,需要人工确认。
主动学习框架和理论为人类专家与机器学习的写作提供了一种有效的途径,它通过迭代抽样的方式将某种特定的样本挑选出来,交由专家对标签进行人工判断和标注,从而构造有效训练集的一种方法。
上图是一个主动学习框架,包括两个部分:训练和查询。
- 在训练环节,利用学习算法对已标注的样本进行学习获得分类器模型。
- 在查询环节,通过样本选择算法从训练数据中选择一些需要人工确认的样本(比如代表性样本、不确定性较高的样本),由专家进行标注确认。
查询策略如何选择需要人工确认的样本,就成为主动学习的核心问题。查询策略主要可以分为以下两类:
- 基于池的样例选择算法;
- 基于流的样例选择算法。
基于池的样本选择算法通过选择当前基准分类器最不确定其分类类别的样本进行人工标注,代表性的有:
- 基于不确定性采样的查询方法;
- 基于委员会的查询方法;
- 基于密度权重的方法等。
基于流的样本选择算法按照数据流的处理方式,在某个时间窗内可以参照基于池的样本选择算法。
4.1 不确定性采样的查询
将模型难于区分的样本提取出来,具体在衡量不确定性时可以采用的方法有最小置信度、边缘采样和熵。
x
L
C
∗
=
argmax
x
(
1
−
P
θ
(
y
^
∣
x
)
)
=
argmin
x
P
θ
(
y
^
∣
x
)
x_{L C}^{*}=\operatorname{argmax}_{x}\left(1-P_{\theta}(\hat{y} \mid x)\right)=\operatorname{argmin}_{x} P_{\theta}(\hat{y} \mid x)
xLC∗=argmaxx(1−Pθ(y^∣x))=argminxPθ(y^∣x)
边缘采样是选择哪些类别概率相差不大的样本:
x
M
∗
=
argmin
x
(
P
θ
(
y
^
1
∣
x
)
−
P
θ
(
y
^
2
∣
x
)
)
x_{M}^{*}=\operatorname{argmin}_{x}\left(P_{\theta}\left(\hat{y}_{1} \mid x\right)-P_{\theta}\left(\hat{y}_{2} \mid x\right)\right)
xM∗=argminx(Pθ(y^1∣x)−Pθ(y^2∣x))
其中,
y
^
1
,
y
^
2
\hat{y}_1,\hat{y}_2
y^1,y^2是样本
x
x
x的top 2归属概率的类别。
对于两个样本a,b的分类概率分别为(0.71,0.19,0.10)、(0.17,0.53,0.30) ,应当选择b,因为0.53-0.17<0.71-0.19。对于二分类问题,边缘采样和最小置信度是等价的。
基于熵采样:通过熵来度量,它衡量了在每个类别归属概率上的不确定。选择熵最大的样本作为需要人工判定的样本。
x
H
∗
=
argmax
x
−
∑
i
P
θ
(
y
i
∣
x
)
⋅
ln
P
θ
(
y
i
∣
x
)
x_H^*=\operatorname{argmax}_x-\sum_i P_\theta\left(y_i \mid x\right) \cdot \ln P_\theta\left(y_i \mid x\right)
xH∗=argmaxx−i∑Pθ(yi∣x)⋅lnPθ(yi∣x)
4.2 基于委员会的查询
当主动学习中采用集成学习模型时,这种选择策略考虑到每个基分类器的投票情况。相应地,通过基于投票熵和平均KL散度来选择样本。
样本
x
x
x的投票熵计算时,把
x
x
x的每个类别的投票数当作随机变量,衡量该随机变量的不确定性。
x
V
E
∗
=
argmax
x
−
∑
i
V
(
y
i
)
C
⋅
ln
V
(
y
i
)
C
x_{V E}^*=\operatorname{argmax}_x-\sum_i \frac{V\left(y_i\right)}{C} \cdot \ln \frac{V\left(y_i\right)}{C}
xVE∗=argmaxx−i∑CV(yi)⋅lnCV(yi)
其中
V
(
y
)
V(y)
V(y)表示投票给y的分类器的个数,
C
C
C表示分类器总数。投票熵越大,就越有可能被选择出来。
当每个基分类器为每个样本输出分类概率时,可以使用平均KL散度来计算各个分类器的分类概率分布与平均分布的平均偏差。偏差越大的样本,其分类概率分布的一致性越差,应当越有可能被选择出来。
x
K
L
∗
=
argmax
x
1
C
∑
c
=
1
C
D
(
P
θ
(
c
)
∥
P
C
)
x_{K L}^*=\operatorname{argmax}_x \frac{1}{C} \sum_{c=1}^C D\left(P_{\theta^{(c)}} \| P_{\mathcal{C}}\right)
xKL∗=argmaxxC1c=1∑CD(Pθ(c)∥PC)
5 噪声鲁棒模型
5.1 AdaBoost的分析与改进

AdaBoost串接的基分类器中,越往后面,错误标签的样本越会得到基分类器的关注。
W
m
+
1
,
i
=
W
m
i
Z
m
e
(
−
β
m
y
i
G
m
(
x
i
)
)
W_{m+1, i}=\frac{W_{m i}}{Z_m} e^{\left(-\beta_m y_i G_m\left(x_i\right)\right)}
Wm+1,i=ZmWmie(−βmyiGm(xi))
当样本
x
x
x分类错误时,其权值以
e
(
β
m
)
e^{(\beta_m)}
e(βm)变化;而对于正确分类的样本以
e
(
−
β
m
)
e^{(-\beta_m)}
e(−βm)变化。
从上述算法流程可以看出,
0
≤
e
m
≤
0.5
0 \leq e_m \leq0.5
0≤em≤0.5,相应地,
β
m
≥
0
\beta_m\geq0
βm≥0。因此,对于,错误的样本的权重
>
e
(
0
)
=
1
>e^{(0)}=1
>e(0)=1,而分类正确的样本的权值
≤
e
(
0
)
=
1
\leq e^{(0)}=1
≤e(0)=1。
经过t轮后得到的权重为
e
(
β
m
1
)
,
e
(
β
m
2
)
,
…
,
e
(
β
m
t
)
e^{(\beta_{m_1})}, e^{(\beta_{m_2})}, \dots, e^{(\beta_{m_t})}
e(βm1),e(βm2),…,e(βmt)。可见噪声样本的权重得到了快速增加而变得很大。
AdaBoost 算法的噪声敏感性归因于其对数损失函数,当一个样本未被正确分类的时候,该样本的 权值会指数型增加。
随着迭代次数的增加,由于算法会更多地关注于错分类的样本, 必然会使得噪声样本的权值越来越大,进而增加了模型复杂度,降低了算法性能。
删除权重过高的样本或调整异常样本的权重来降低标签噪声的影响。
MadaBoost:针对噪声样本在后期的训练权重过大的问题,算法重新调整了AdaBoost中的权值更新公式,设置了一个权重的最大上限1,限制标签噪声造成的样本权值的过度增加。
AdaBoost的损失函数改进:
各分类器稳健性差异的本质原因在于损失函数;
不同损失函数对噪声的稳健性差异:
- 0-1损失或最小二乘损失对均匀分布噪声稳健;
- 指数、对数型损失函数对各类噪声大都不稳健。
AdaBoost的损失函数:
L
=
∑
n
=
1
N
e
(
−
y
n
F
T
(
x
n
)
)
=
∑
n
=
1
N
e
[
−
y
n
(
α
T
h
T
(
x
n
)
+
F
T
−
1
(
x
n
)
)
]
L=\sum_{n=1}^N e^{\left(-y_n F_T\left(x_n\right)\right)}=\sum_{n=1}^N e^{\left[-y_n\left(\alpha_T h_T\left(x_n\right)+F_{T-1}\left(x_n\right)\right)\right]}
L=n=1∑Ne(−ynFT(xn))=n=1∑Ne[−yn(αThT(xn)+FT−1(xn))]
对于每次迭代,权重是一个常数:
L
=
∑
n
=
1
N
w
n
(
T
)
e
[
−
y
n
α
T
h
T
(
x
n
)
]
L=\sum_{n=1}^N w_n^{(T)} e^{\left[-y_n \alpha_T h_T\left(x_n\right)\right]}
L=n=1∑Nwn(T)e[−ynαThT(xn)]
where
w
n
(
T
)
=
e
(
−
y
n
F
T
−
1
(
x
n
)
)
w_n^{(T)}=e^{\left(-y_n F_{T-1}\left(x_n\right)\right)}
wn(T)=e(−ynFT−1(xn))
F
T
−
1
(
x
n
)
=
∑
t
=
1
T
−
1
α
t
h
t
(
x
n
)
F_{T-1}\left(x_n\right)=\sum_{t=1}^{T-1} \alpha_t h_t\left(x_n\right)
FT−1(xn)=t=1∑T−1αtht(xn)
此处,
h
h
h是分类器,
α
α
α是分类器的权重
5.2 ndAdaBoost

(1)噪声样本被正确分类,表示为
x
p
x_p
xp
(2)非噪声样本被正确分类,表示为
x
q
x_q
xq
(3)噪声样本被错误分类,表示为
x
k
x_k
xk
(4)非噪声样本被错误分类,表示为
x
l
x_l
xl文章来源:https://www.toymoban.com/news/detail-717185.html
预期目标:
ndAdaBoost的损失函数:
L
^
=
∑
n
=
1
N
w
^
n
(
T
)
e
[
−
y
n
α
T
h
T
(
x
n
)
ϕ
T
(
x
n
)
]
\widehat{L}=\sum_{n=1}^{N} \widehat{w}_{n}^{(T)} e^{\left[-y_{n} \alpha_{T} h_{T}\left(x_{n}\right) \phi_{T}\left(x_{n}\right)\right]}
L
=n=1∑Nw
n(T)e[−ynαThT(xn)ϕT(xn)]
此处
w
^
n
(
T
)
=
e
(
−
y
n
∑
t
=
1
T
−
1
α
t
h
t
(
x
n
)
ϕ
t
(
x
n
)
)
\widehat{w}_{n}^{(T)}=e^{\left(-y_{n} \sum_{t=1}^{T-1} \alpha_{t} h_{t}\left(x_{n}\right) \phi_{t}\left(x_{n}\right)\right)}
w
n(T)=e(−yn∑t=1T−1αtht(xn)ϕt(xn)),
ϕ
t
(
x
n
)
=
sgn
(
μ
ˉ
t
−
μ
t
(
x
n
)
)
\phi_{t}\left(x_{n}\right)=\operatorname{sgn}\left(\bar{\mu}_{t}-\mu_{t}\left(x_{n}\right)\right)
ϕt(xn)=sgn(μˉt−μt(xn)),
μ
t
(
x
n
)
\mu_{t}\left(x_{n}\right)
μt(xn)表示样本
x
n
x_n
xn为噪声的概率,即样本为噪声的置信度,
μ
ˉ
t
=
∑
n
=
1
N
μ
t
(
x
n
)
N
\bar{\mu}_{t} = \frac{\sum_{n = 1}^N \mu_{t}\left(x_{n}\right)}{N}
μˉt=N∑n=1Nμt(xn)。
在这样的损失函数下:文章来源地址https://www.toymoban.com/news/detail-717185.html
- (1)如果样本
x
n
x_n
xn被错误分类
在误分的样本中,噪声数据比非噪声数据所占的比例更大。不正确分类的样本噪声越大,其损失函数值越小。
L ^ = ∑ ϕ t = + 1 W ^ n ( t ) e α t + ∑ ϕ t = − 1 W ^ n ( t ) e − α t \widehat{\mathbf{L}} = \sum_{\phi_t = +1} \widehat{W}_n^{(t)} e^{\alpha_t} + \sum_{\phi_t = -1} \widehat{W}_n^{(t)} e^{- \alpha_t} L =ϕt=+1∑W n(t)eαt+ϕt=−1∑W n(t)e−αt - (2)如果样本
x
n
x_n
xn被正确分类
在正确分类的样本中,非噪声数据倾向于最小化损失函数,也就是说非噪声数据尽可能多地成为正确分类。
L ^ = ∑ ϕ t = − 1 W ^ n ( t ) e α t + ∑ ϕ t = + 1 W ^ n ( t ) e − α t \widehat{\mathbf{L}} = \sum_{\phi_t = -1} \widehat{W}_n^{(t)} e^{\alpha_t} + \sum_{\phi_t = +1} \widehat{W}_n^{(t)} e^{- \alpha_t} L =ϕt=−1∑W n(t)eαt+ϕt=+1∑W n(t)e−αt
5.3 损失函数设计与选择
- 0-1损失函数
- 平均绝对误差MAE
- 均方误差MSE
- 均方根误差RMSE
- 交叉熵损失
- 指数损失
- 对数损失
- Hinge损失函数
到了这里,关于人工智能安全-3-噪声数据处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!