👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

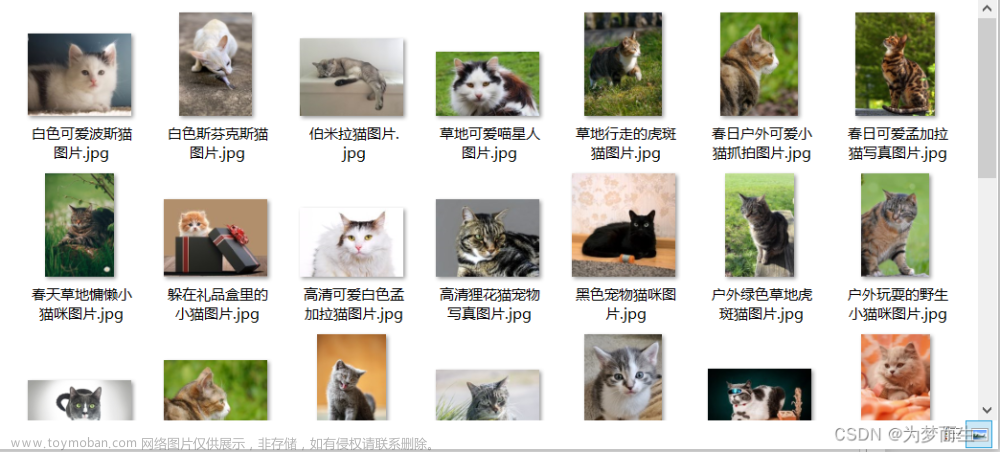
爬虫(框架)爬取网站页面
爬虫(框架)爬取网站页面
1. 导入必要的库
import requests
from bs4 import BeautifulSoup
-
requests库用于发送HTTP请求以获取网页内容。 -
BeautifulSoup库用于解析HTML内容并提取我们需要的信息。
2. 获取网页内容
我们首先要使用requests库获取页面的HTML内容。
url = 'https://example.com/articles'
response = requests.get(url)
html_content = response.content
3. 使用BeautifulSoup解析HTML
将获取到的HTML内容传递给BeautifulSoup,这样我们就可以用它来解析页面了。
soup = BeautifulSoup(html_content, 'html.parser')
4. 数据提取
这完全取决于你想从页面中提取哪些信息。假设我们要提取所有文章标题和链接:
articles = soup.find_all('div', class_='article') # 假设每篇文章都包含在一个class为'article'的div标签内
for article in articles:
title = article.find('h2').text
link = article.find('a')['href']
print(title, link)
5. 异常处理
在爬取网站时可能会遇到各种问题,如网络问题、页面不存在等。我们需要添加一些异常处理来确保爬虫的稳定性。
try:
response = requests.get(url, timeout=10)
response.raise_for_status() # 如果响应状态不是200,则引发异常
except requests.RequestException as e:
print(f"Error fetching the url: {url}. Reason: {e}")
6. 避免被封禁
当连续并频繁请求某个网站时,可能会被封禁。你可以使用以下策略避免这种情况:文章来源:https://www.toymoban.com/news/detail-717603.html
- 设置User-Agent:伪装成真正的浏览器。
-
设置延迟:在连续的请求之间设置延迟,例如使用
time.sleep(5)延迟5秒。 - 使用代理:使用不同的IP地址来发送请求。
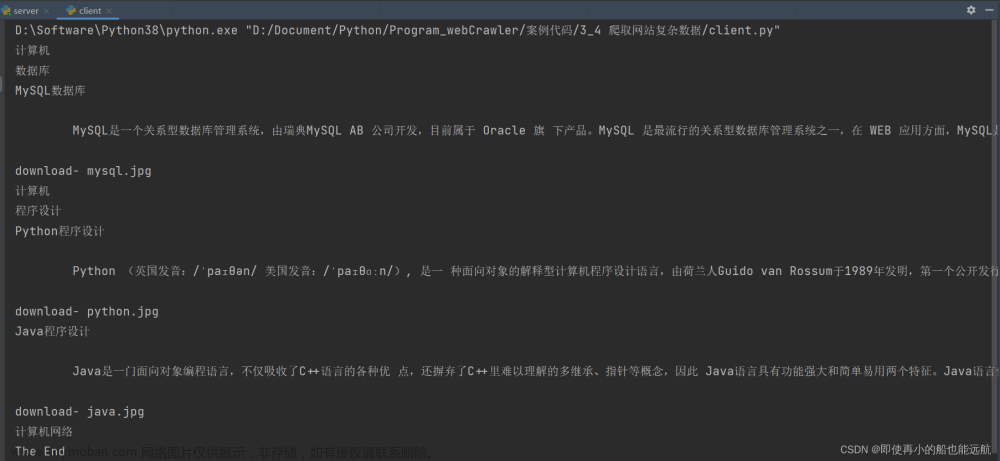
完整代码示例:
import requests
from bs4 import BeautifulSoup
import time
url = 'https://example.com/articles' # 换成你的网站
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
articles = soup.find_all('div', class_='article')
for article in articles:
title = article.find('h2').text
link = article.find('a')['href']
print(title, link)
time.sleep(5) # 每抓取一个页面后,暂停5秒
except requests.RequestException as e:
print(f"Error fetching the url: {url}. Reason: {e}")
注意事项
注意:在运行爬虫之前,你应该:文章来源地址https://www.toymoban.com/news/detail-717603.html
- 检查目标网站的
robots.txt文件,了解哪些页面允许爬取。 - 不要频繁地请求网站,这可能会被视为DDoS攻击。
- 确保你有权爬取和使用目标数据。
- 考虑网站的负载,不要对网站造成不必要的压力。
- 有时候,使用API是获取数据的更好方法,许多网站提供API来获取数据,而不是直接爬取。
到了这里,关于【爬虫】python爬虫爬取网站页面(基础讲解)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)