声明
以下只是搬运下我公众号的东西。很早就发过了。原帖地址:
python完美突破tls/ja3 (qq.com)
已经发公众号的为什么还发csdn
有的圈内朋友,不经过我的允许,删减摘录我公众号的内容,这里就不提谁了,心里清楚,还能获得一些关注和流量。很无语,所以我还不如自己也发发。【猛男落泪】
前言
时隔一个多月我又发文了,我还是只发好文的geekbyte,前几天有朋友跟我说我断更一个多月了,哈哈,这不就来了吗
不多废话,进入正题。
如果你偶尔看到这篇文章,而对tls还一脸懵的朋友,可以先阅读以下文章了解一下
https://mp.weixin.qq.com/s/Qx7PjnBgrTR30oCurU6CGw
https://mp.weixin.qq.com/s/7VJHCl2ht4pjkgIdcOKc5w
JS逆向之猿人学第十九题突破ja3指纹验证
深度剖析ja3指纹及突破
ja3指纹补充说明
距离我上次发 深度剖析ja3指纹及突破 已时隔半年多(因为之前删过重新发的),我当时抛出一个问题,就是python由于依赖的openssl库没法高度自定义,导致针对tls那5个组件没法改动太大。
TLSVersion,Ciphers,Extensions,EllipticCurves,EllipticCurvePointFormats所以目前有些平台如果有tls认证的话,那对python的爬虫就是降维打击。当时的我确实考虑过看自己去编译一个库,然后解除这个针对python的限制。
这个tls,如果我没搞错的话,在国内的圈子,进入大家视线的是青南大佬,然后是猿人学的练习题,接着再是我的深度剖析,惭愧,我提出来的python被降维打击,我自己想搞定,因为各种原因,我没能去研究,而现在已经有大佬搞定了,而且个人觉得十分完美,所以下面我给一个详细的食用流程吧,也算是给它画上一个句号了。
目前我知道的针对tls的方案
1.hook tls 组件
目前hook方面,比较成熟的方案就是golang的cycletls,这个cycletls是我偶然找到的go库,也算是能解决大部分的平台。但是据我所知,已经有一些风控强的网站可以识别你hook修改过ja3指纹了
2.魔改openssl
用志远大佬的方案,重新编译openssl,在编译过程中,改c源码,使每次发起请求的tls指纹随机
个人觉得,按目前的行情,如果是校验很强的tls话,随机的可能不行
想我还被远哥在群里@夸赞过,嘻嘻~
3.魔改socket
这个方案是@3301大佬魔改了一套socket收发包流程,是真的牛逼。
在几个月前我跟他私聊过,说好了一起研究的,因为种种原因我放他鸽子了,唉
不过他已经基本搞定,目前已开源:
https://github.com/zero3301/pyrequests/
作者自己说了,暂不支持HTTP2和tls1.3和动态tls指纹,他希望有人能跟他一起开发,感兴趣的可以跟他联系。
4.重编译chromium
根据我的研究,发现这个方案在针对tls方面,能改的不是很多,底层还是借助了浏览器,还不如直接rpc或者用selenium之类的
5.curl-impersonate+pycurl
这个方案我自认为是相对来说最完美的方案
也是我之前想过准备要走的研究方向,可惜因为种种原因,没有继续,理论上的思路跟这个很类似,这里就暂不透漏了。
curl-impersonate,就是用一个大佬编译好的跟浏览器完全一致的curl魔改版
https://github.com/lwthiker/curl-impersonate
其中,curl-impersonate作者自己也写过相关的文章,想了解原理的可以看看,我看完之后真的受益匪浅,对tls的理解更深入了,如果你有意向也想自己编译一个,个人十分建议阅读,反复阅读
https://lwthiker.com/
pycurl就是借助curl发起请求的库
https://github.com/pycurl/pycurl # 官方版
https://github.com/ycq0125/pycurl # 肝总魔改版本
这里我推荐用肝总的版本。
在编译安装pycurl时指定的curl是魔改好的curl-impersonate,这样python就可以发起跟浏览器完全一致的tls,而且支持自定义tls算法套件。
这个方案唯一的缺点就是,编译过程相对复杂,没法开箱即用,在不同的系统平台下就会遇到各种各样的问题
ok,以下开始我的编译血泪史吧,带着大家一起编译一下curl-impersonate+pycurl。
我选用的环境是在win上用vm虚拟机软件里的linux,这样,即使我有一个步骤错了,可以回到正常的还原点上,节省很多时间。以下用到的图片,由于是我在编译时在每个步骤的截图保留的,所以一会儿是kali界面,一会儿是ubuntu界面,这个不影响,实际你跟着我操作能编译成功即可(其实是真的不想再重新走一遍编译了)
编译curl-impersonate
官方教程,里面给了ubuntu、centos、macos的编译过程,当然如果你想快速用上,可以用该作者直接编译好的docker,但是如果你还要编译pycurl的话,那就得自编译了
https://github.com/lwthiker/curl-impersonate/blob/main/INSTALL.md
注意:不建议用kali
我刚开始使用的是kali linux,为了图方便,直接用的肉师傅的r0env,反正我是没成功(不是说肉师傅的r0env有问题,我咋可能这么冒犯呢,我中途踩坑了很多次,估计装了有冲突的依赖所以导致不行)
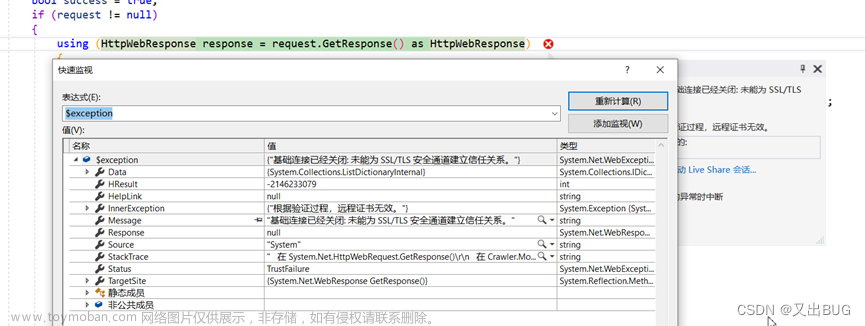
kali编译curl-impersonate是没问题的,结果到后面编译pycurl就会有问题:

这个问题我查阅了大量代码,反正就是提示源码的这一行有问题,大概意思是说事先没声明使用

各种方法都试了,有的说是openssl和curl版本太老了,但是我的是最新的,基本不是这个问题,所以,没法了,一度让我心态没了,我放弃用kali。
去官网下载的最新的ubuntu22.04lts(18版本也可以),安装在虚拟机里,网络,proxychains啥的基本配置好了。重新来吧
1.安装需要的环境依赖
这个步骤跟官方教程一样,但是多了些其他的步骤:
sudo apt install build-essential pkg-config cmake ninja-build curl autoconf automake libtool安装完之后,还要再输入以下命令安装:
# 多了以下命令sudo apt upgrade build-essential pkg-config cmake ninja-build curl autoconf automake libtool
注意,检查下你系统里有没有支持HTTP2的库,要不然还是有问题,curl-impersonate可以编译,pycurl也可以编译,但是不支持HTTP2,然后只要设置HTTP2的就会报如下错:

这些坑我都踩过了,一想起编译失败的时候就心里苦,所以提前跟你说好在编译之前的操作
怎么装HTTP2库,先用apt search http2
然后会搜到一堆,这里就不贴上占篇幅了。
我刚开始是安装了这些:
sudo apt-get install nghttp2 libnghttp2-dev后面实在是不放心,因为真的不想重来了,都记不清楚我重试了多少次了(哭~)
我索性又把自己感觉可能会用到的库都装了
sudo apt-get install gogottrpc libghc-http2-prof libghc-wai-http2-extra-dev libghc-wai-http2-extra-prof libprotocol-http2-perl librust-curl+http2-dev librust-curl-sys+http2-dev librust-curl-sys+http2-dev ruby-protocol-http2好了,有了以上的操作,再继续执行后续步骤,这个步骤没啥要注意的,直接能装上
sudo apt install python3-pip libnss3pip install gyp-nextexport PATH="$PATH:~/.local/bin" # Add gyp to PATH# For the Chrome version onlysudo apt install golang-go unzip
2.拉取代码
也没啥要特别注意的
git clone https://github.com/lwthiker/curl-impersonate.gitcd curl-impersonate
如果你没装git会报错,这个就不多说了:sudo apt get git
如果提示无法识别github.com的域名,vim /etc/resolv.conf
去里面,把nameserver改为如下,保存退出,其他别改
nameserver 8.8.8.8nameserver 114.114.114.114
如果报错:
fatal: unable to access 'https://github.com/lwthiker/curl-impersonate.git/': gnutls_handshake() failed: The TLS connection was non-properly terminated.终端设置下git的代理:
git config --global http.https://github.com.proxy http://192.168.18.231:7890git config --global https.https://github.com.proxy https://192.168.18.231:7890
再次执行,即可拉取成功

下面这个步骤必须先后顺序执行:
autoconfmkdir build && cd build../configure
3.开始编译
# Build and install the Firefox versionmake firefox-buildsudo make firefox-install# Build and install the Chrome versionmake chrome-buildsudo make chrome-install# You may need to update the linker's cache to find libcurl-impersonatesudo ldconfig # 这个步骤必须要,不然用不了
注意,使用make命令的时候,会去下载需要的文件,如果报错:
curl: (7) Failed to connect to github.com port 443 after 6 ms: Connection refused说明你网络不行,可以加上proxychains
proxychains make firefox-build配置proxychains,先用apt 安装,然后在win电脑开启你的科学软件,
配置,vim /etc/proxychains.conf ,把dns注释掉,到文件最底部,设置你win电脑的ip,科学软件暴露的端口即可


这里就不多介绍了,具体自己查proxychains怎么配置吧
接着再次执行build命令,如果报错:
CMake Error at CMakeLists.txt:486 (message):Unknown processor:[proxychains] DLL init: proxychains-ng 4.14[proxychains] DLL init: proxychains-ng 4.14x86_64-- No package 'libunwind-generic' found
执行以下解决:
sudo apt-get update -ysudo apt-get install -y libunwind-dev
再次执行build,没报错则构建完毕,接着再执行安装命令:
sudo make firefox-install

接着编译chrome,操作同上
make chrome-build # 如果太慢加上proxychainssudo make chrome-install
如果在build的时候报错:
FAILED: crypto_test_data.cc /root/Desktop/curl-impersonate/build/boringssl/build/crypto_test_data.cccd /root/Desktop/curl-impersonate/build/boringssl && /usr/bin/go run util/embed_test_data.go -file-list /root/Desktop/curl-impersonate/build/boringssl/build/embed_test_data_args.txt > /root/Desktop/curl-impersonate/build/boringssl/build/crypto_test_data.cc[proxychains] DLL init: proxychains-ng 4.14[proxychains] DLL init: proxychains-ng 4.14go: golang.org/x/crypto@v0.0.0-20210513164829-c07d793c2f9a: Get "https://proxy.golang.org/golang.org/x/crypto/@v/v0.0.0-20210513164829-c07d793c2f9a.mod": dial tcp 142.251.42.241:443: i/o timeout
是因为借用了go的库,使用命令:
go env -w GOPROXY=https://goproxy.cn继续编译、安装
完成之后再继续执行下面的命令,注意下面最后一个命令的rm, 如果你只是要编译curl-impersonate,那可以删除,如果你还要编译pycurl,千万别执行删除
sudo ldconfig# Optionally remove all the build filescd ../ && rm -Rf build # 注意了
4.编译完成测试
整个过程安装完后,输入curl_ 按tab键,有下面的说明编译完成


装完了测试:
curl-impersonate-ff https://ja3er.com/jsoncurl-impersonate-chrome https://ja3er.com/json

curl-impersonate编译完了
如果你执行的时候报错如下:
/usr/local/bin/curl_ff98: line 10: /usr/local/bin/curl-impersonate-ff: No such file or directory重来吧
编译pycurl
1.环境准备
首先确认你刚才编译的curl-impersonate,是否符合编译pycurl的要求
curl-impersonate-chrome -V
如果有对应的ssl库和nghttp2,那就可以。这两个缺一个都不行,否则重新编译curl-impersonate吧
2.拉取代码
建议不要用官方的那个pycurl,用spike肝总魔改过的
git clone https://github.com/ycq0125/pycurl那么肝总魔改了哪些呢?我问过他本人,跟官方的比,他就改了这些,个人建议可以好好读一下他的代码:
https://github.com/pycurl/pycurl/commit/d0dbf9569f1440bdfe452000ff3073336061e24f如果无法正常拉取,按照上面拉取curl-impersonate的方法同样操作即可
3.改源码
这个步骤就是为了指定刚才编译的curl-impersonate的
cd pycurl/srcvi pycurl.h
其他不用动,改下面这里就行,把这个路径改为你实际的路径,也就是刚才编译好的curl-impersonate的build,改之前:

改之后:

保存退出
4.开始编译
python3 setup.py install --curl-config={实际的curl路径}/curl-impersonate-chrome-config --openssl-dir={实际的curl路径}/curl-impersonate/build/boringssl/build比如我的:
python3 setup.py install --curl-config=/home/async/桌面/curl-impersonate-chrome-config --openssl-dir=/home/async/桌面/curl-impersonate/build/boringssl/build如果报这个错,权限问题

加上sudo再次执行,以下就是编译完了

5.测试执行
有个地址可以暂时替代ja3官网作为参考(最近发现ja3官网经常崩)
https://tls.peet.ws/api/all先用curl请求:

现在用python请求下,也就是pycurl文件里的那个test.py文件

执行结果里,如果看不到这个nghttp2,就不支持HTTP2,你又得整个过程重来了
可以看看test.py代码,其实跟之前的python改tls算法区别不大,只是现在用的是编译过的curlAdapter。

光能跑没有用对吧,要看tls真的被改了没有,对比下:

一模一样,牛逼了
6.实际案例测试
还是那个不可说的地址,先用curl-impersonate看看,能访问哈:

用python请求看看:

起飞!!!!
7.自定义tls算法
你可以对照着已有的tls算法,自定义了
主要就是改这里:

https://hpbn.co/transport-layer-security-tls/#tls-session-resumptionhttp://pycurl.io/docs/latest/quickstart.htmlhttps://curl.se/libcurl/c/CURLOPT_HTTP_VERSION.html
反正想怎么改怎么改,你只要别给一个tls不认识的算法就行,起飞吧
后期有空我把我这个编译好的环境,打成docker镜像发出来,你们就不用再走我走过的路了,当然,有时间才行,嘻嘻

编译其他浏览器
上面的步骤是编译指定curl-chrome的,你可以重新拉下pycurl,然后重新编译,指定为firefox,edage,safari的路径即可,流程也是一样的,这里就不细说了
踩坑总结
以下是我安装过程中遇到过的坑,仅供各位朋友参考:
1.fatal: unable to access 'https://github.com/lwthiker/curl-impersonate.git/': gnutls_handshake() failed: The TLS connection was non-properly terminated.解决办法:git config --global http.https://github.com.proxy http://192.168.18.231:7890git config --global https.https://github.com.proxy https://192.168.18.231:78902.curl: (7) Failed to connect to github.com port 443 after 6 ms: Connection refused解决办法:proxychains make firefox-build编译的时候虽然会去下载各种库,如果中途报curl的错就不要用proxychains3.curl: (35) error:0A000126:SSL routines::unexpected eof while reading解决办法:https://blog.csdn.net/u011700186/article/details/1094526844.install /root/Desktop/curl-impersonate/build/../firefox/curl_ff* /usr/local/binbash: line 1: cd: curl-7.81.0: No such file or directorycurl_chrome101 https://www.baidu.com/usr/local/bin/curl-impersonate-chrome: error while loading shared libraries: libcurl-impersonate-chrome.so.4: cannot open shared object file: No such file or directory解决办法:ldconfig5.CMake Error at CMakeLists.txt:486 (message):Unknown processor:[proxychains] DLL init: proxychains-ng 4.14[proxychains] DLL init: proxychains-ng 4.14x86_64-- No package 'libunwind-generic' found解决办法:sudo apt-get update -ysudo apt-get install -y libunwind-dev6.FAILED: crypto_test_data.cc /root/Desktop/curl-impersonate/build/boringssl/build/crypto_test_data.cccd /root/Desktop/curl-impersonate/build/boringssl && /usr/bin/go run util/embed_test_data.go -file-list /root/Desktop/curl-impersonate/build/boringssl/build/embed_test_data_args.txt > /root/Desktop/curl-impersonate/build/boringssl/build/crypto_test_data.cc[proxychains] DLL init: proxychains-ng 4.14[proxychains] DLL init: proxychains-ng 4.14go: golang.org/x/crypto@v0.0.0-20210513164829-c07d793c2f9a: Get "https://proxy.golang.org/golang.org/x/crypto/@v/v0.0.0-20210513164829-c07d793c2f9a.mod": dial tcp 142.251.42.241:443: i/o timeout解决办法:go env -w GOPROXY=https://goproxy.cn7./usr/local/bin/curl_ff98: line 10: /usr/local/bin/curl-impersonate-ff: No such file or directory这是出错了,重来吧8.src/easyopt.c: In function ‘do_curl_setopt_string_impl’:src/easyopt.c:215:10: error: ‘CURLOPT_SSL_CERT_COMPRESSION’ undeclared (first use in this function); did you mean ‘CURLOPT_SSH_COMPRESSION’?215 | case CURLOPT_SSL_CERT_COMPRESSION:| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~| CURLOPT_SSH_COMPRESSION更新openssl,重新安装export OPENSSL=/usr/local/openssl/bin不行就重来9.src/pycurl.h:5:10: fatal error: Python.h: No such file or directory换ubuntu ,kali不行10.Traceback (most recent call last):File "/home/async/桌面/pycurl/test2.py", line 19, in <module>curl.setopt(curl.HTTP_VERSION, curl.CURL_HTTP_VERSION_2_0)pycurl.error: (1, '')原因是不支持HTTP2,https://github.com/pycurl/pycurl/issues/477解决办法:需要安装nghttp2 , 这个在编译curl前就要安装的sudo apt-get install libnghttp2-devsudo apt-get install nghttp2sudo apt-get install gogottrpc libghc-http2-prof libghc-wai-http2-extra-dev libghc-wai-http2-extra-prof libprotocol-http2-perl librust-curl+http2-dev librust-curl-sys+http2-dev librust-curl-sys+http2-dev ruby-protocol-http2
这是某大佬遇到的报错:

这个是系统问题,换系统镜像吧
目前我知道的可用的镜像:
1.No LSB modules are available.Distributor ID: DebianDescription: Debian GNU/Linux 10 (buster)Release: 10Codename: buster2.ubuntu18.043.ubuntu22.04
结语
1.在编译的时候别慌,遇到问题别乱,一点点排查
如果遇到了我总结的里面没有的坑,多点耐心,多查资料,找原因,解决它
我就为了编译好,设置了这么多还原点,所以你知道我经历了多少吗,从崩溃中重新放平心态重来(期间非常感谢spike肝总帮我排查问题)

2.想进群交流的,加我微信,ID:geekbyte,加了我还没进群的,私聊我。
由于现在群里大佬众多,为了维护良好环境,所以会有一个简单的1分钟入群测试,为了过滤打广告和无关人员的。文章来源:https://www.toymoban.com/news/detail-717746.html
3.要提升技术的,可以找我报课哟,肉丝,珍惜,猿人学都有优惠价
最后再说一句,python 好起来了!!!!文章来源地址https://www.toymoban.com/news/detail-717746.html
到了这里,关于python完美突破tls/ja3的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!