郭炜
本文由白鲸开源CEO郭炜投递并参与《2023中国企业数智化转型升级先锋人物》榜单/奖项评选。

数据智能产业创新服务媒体
——聚焦数智 · 改变商业
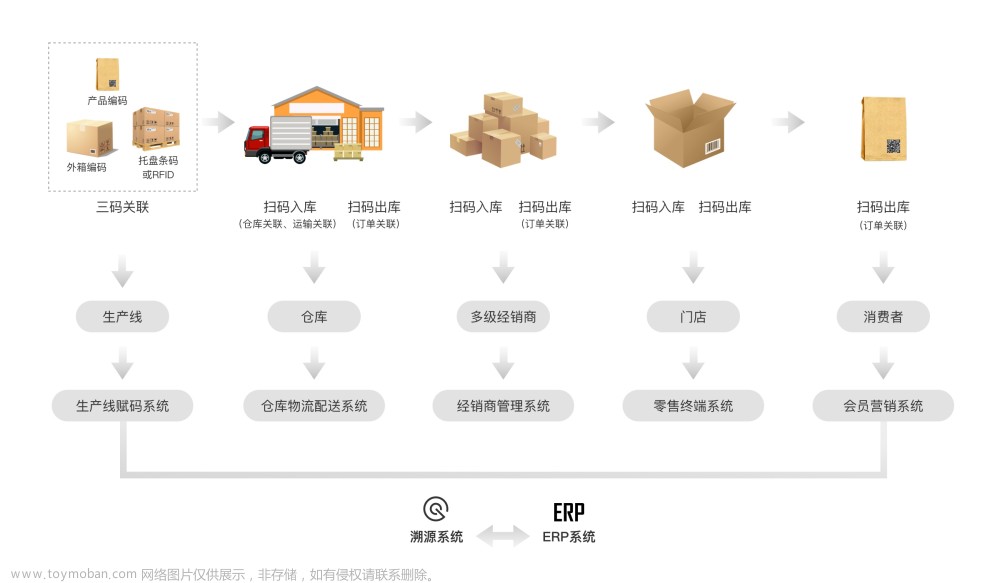
随着数据驱动的理念深入人心,每个企业内部积累越来越多纷繁复杂的大数据,而这些新兴数据源与快速敏捷开发过程给企业数据治理提出新的挑战:
● 应用研发敏捷开发让应用/交易数据快速扩张,数据管理部门无法快速处理和及时响应,传统的数据治理流程产生巨大挑战;
● 新兴数据源,多云、混合云、SaaS快速发展,企业“暗数据”越来越多,大数据领域新兴数据孤岛越来越多,根据Gartner统计目前企业的大数据有68%数据没有被分析,82%企业出现数据孤岛;
● 业务部门数据驱动理念深入,为了满足需求多数企业建立多个数据集市让业务部门自己单独管理,结果是数据指标爆炸增长,数据治理的工作量越做越多,数据治理的范围却越管越少;
● 庞大的数据体系让数据越来越难找,数据治理越来越难,数据范围已经从DataOps扩大到DevOps流程,分析师80%时间都在找数据和验证数据。
这些都是在这个大数据时代下每个企业在数据治理方面提出的挑战。而大模型的出现,让企业通过智能化方法快速理解企业内部数据资产并帮助企业内部数据自发现、自分类、自关联,从而加速企业产生数据到数据产生信息最终转化成知识的效率,实现企业在数据管理方面全面数智化升级。
传统数据治理方式下智能化技术挑战
智能化数据治理的目标是让数据自发现,最终实现业务部门的自服务,这个目标很美好,但是技术落地实践非常复杂。过去Gartner曾经评估过DataFabric的实现难度,很多黄色(中成熟度)和红色(低成熟度)部分。
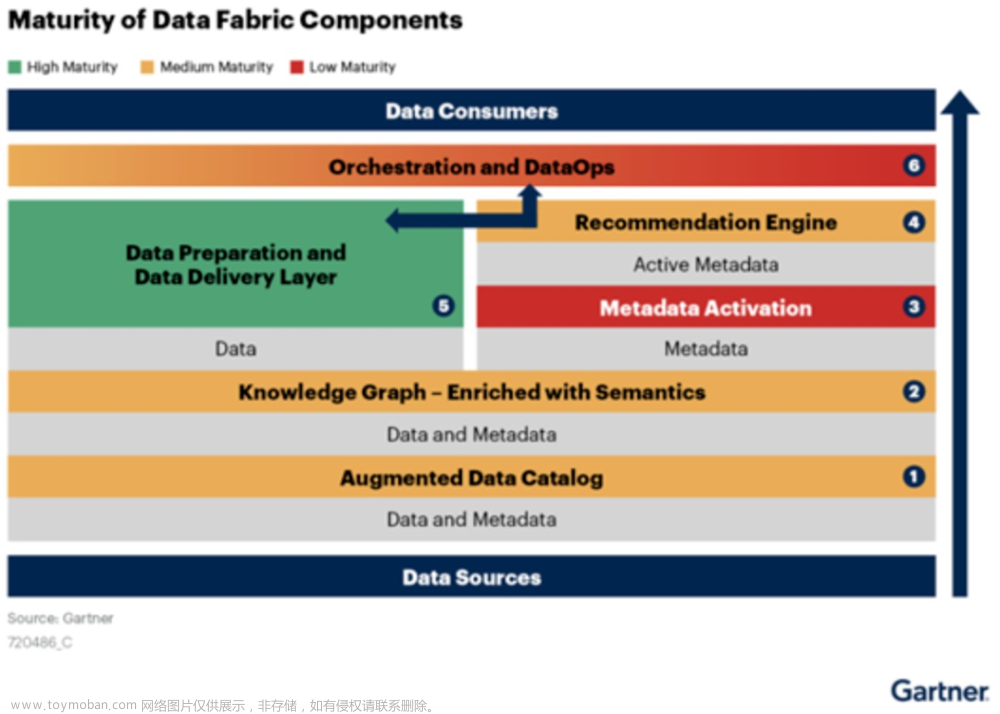
而具体智能化数据治理在企业落地过程中也遇到很多挑战:
● 传统元数据采集和映射,只有技术元数据,业务元数据获取方式大部分采取人工方式,大数据爆发的时代人工处理不过来;
● 知识图谱,传统用户画像现有的技术已经过时,数据目录型态无法满足查询和找到用户所需的数据;
● 数据虚拟化技术性能不足,而全部同步代价又大,何时自动迁移,何时源库查询?如何不影响OLTP环境很难判断。
●DataOps是基础(代码,需求,测试,ETL,数据质量,链路血缘)+数据源元数据整理并不完善。
大模型促进大数据数据治理“数智化”升级
过去传统的元数据分析和数据治理技术是基于图数据库、NLP语义分析,所以存在着技术元数据和业务元数据无法对应,数据管理工具无法理解行业属性和行业文档等问题,所以面对需要加企业业务理解(业务元数据)和数据资产(技术元数据)几乎无法实现。而大模型的自然语言理解力,结合向量数据库的知识储备能力已经远超过传统NLP、图数据库这些能力,将大数据数据治理“数智化”成为可能:
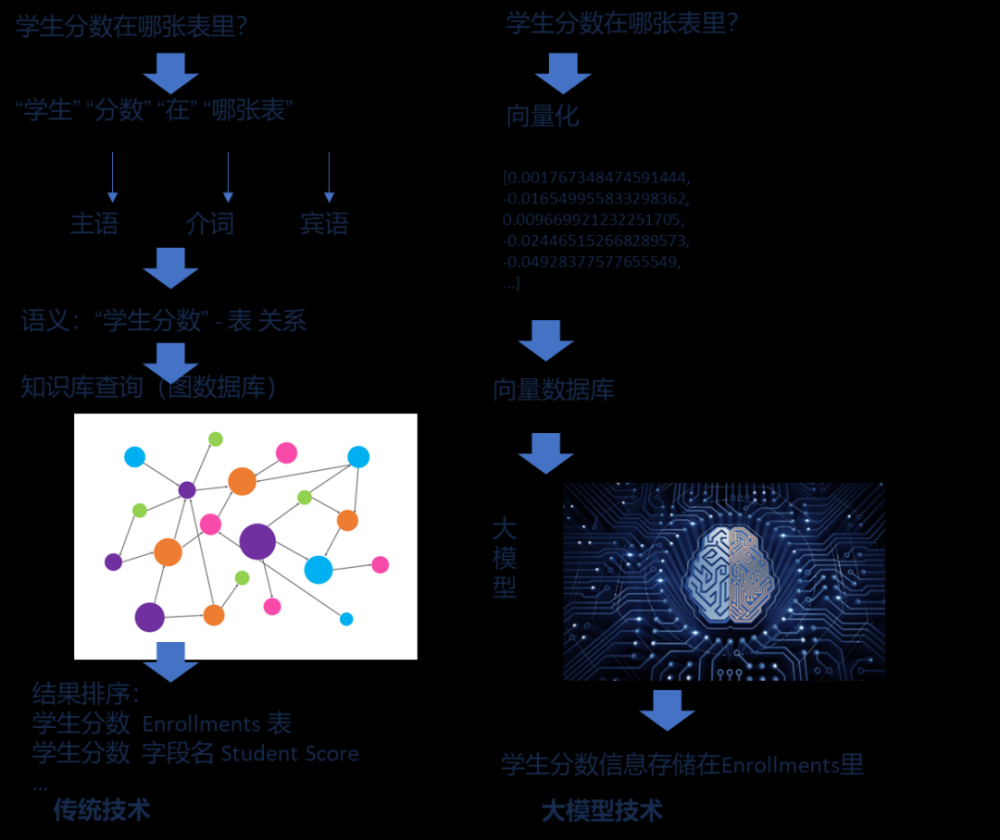
大模型的出现完全颠覆了以前数据治理智能化的技术框架架构,下图是过去传统的数据治理技术架构:
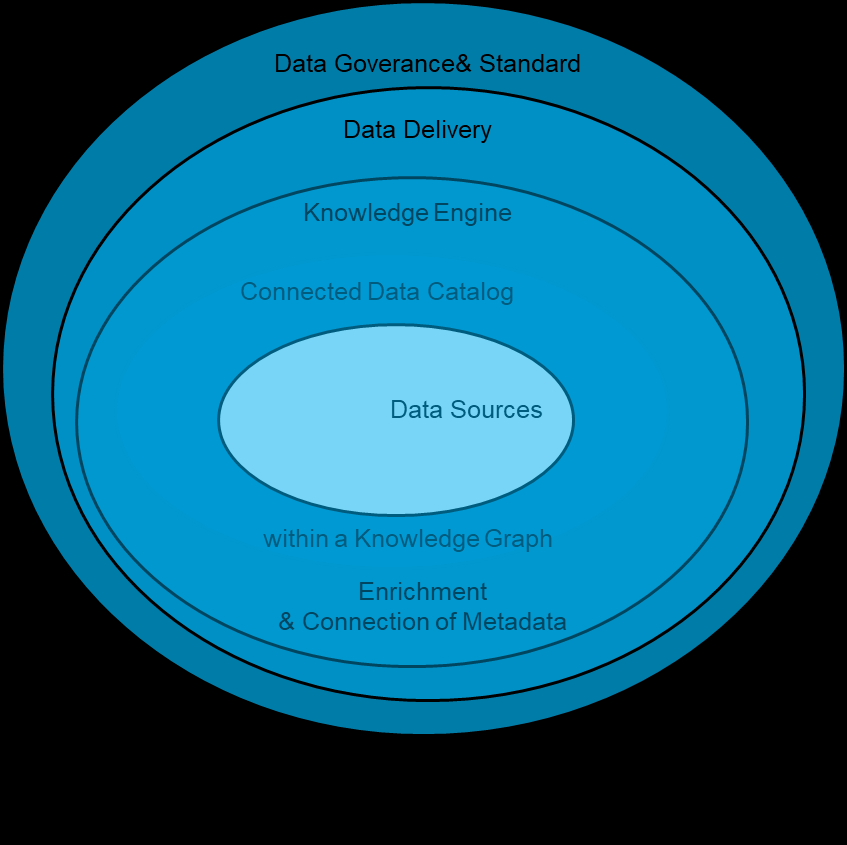
将企业的业务定义、行业理解,企业业务口径定义,企业内部数据库的结构,甚至数据画像都通过灌入大模型最终实现对企业内部数据的全面“自动化”最终实现数据,所以在大模型体系下,数智化数据治理技术框架是这样的:
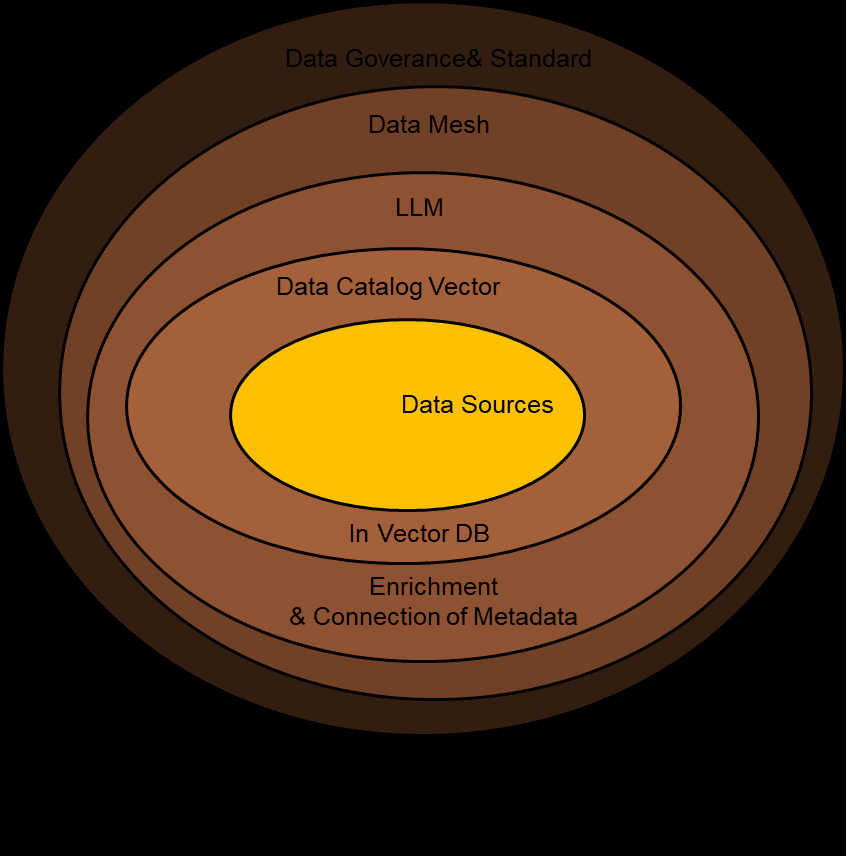
大模型数据数据治理“数智化”实践
下图就是我在白鲸开源训练的私有化大模型WhaleLLM的效果,我们可以惊喜的发现大模型可以迅速理解表述的语义,特殊的业务术语,并可以快速理解用户企业自己的数据库表结构,甚至可以把用户需求可以用SQL直接表述出来。在这个体系下,让DataFabric落地成为了可能。用一张A40显卡就可以让私有化大模型理解你的业务定义、表结构,并可以告诉你数据怎么来使用,甚至可以帮你把SQL准备好。

所以,在企业环境下,通过DevOps快速迭代开发应用,这些应用会远远不断的产生数据和新的业务流程以及业务知识,这些数据通过DataOps快速开发迭代反哺应用开发和企业决策。而在DevOps和DataOps之间,源源不断在学习业务知识、业务信息、数据治理的业务知识同时也源源不断学习企业数据湖、云、数据查询规则的大模型,将会成为一个企业内部的数据“万能顾问”,最终让智能化的数据治理落地。
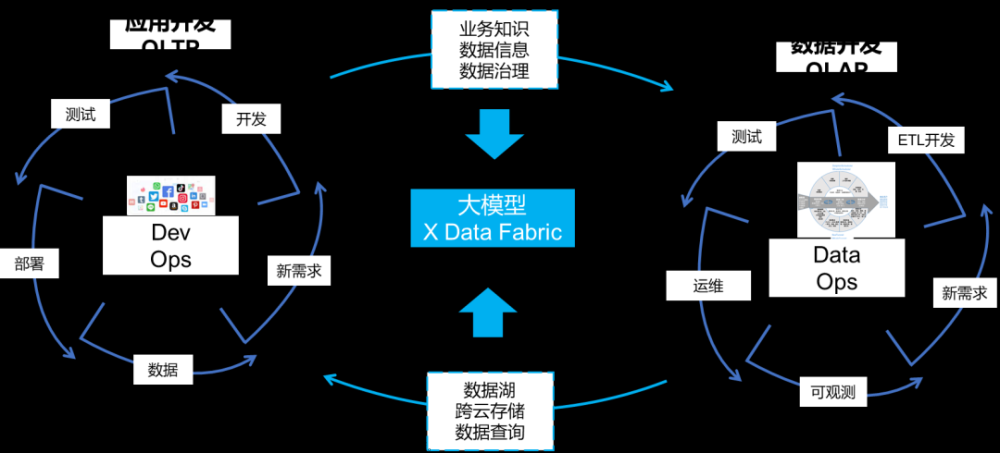
大模型在数据治理的应用最终实现DataFabric
早在2000年初Forrester面对纷繁复杂的数据定义和数据治理体系就提出了智能化的概念DataFabric。
而什么是DataFabric?中文翻译有人叫数据编织,也有人叫做数据经纬,从词面分析可知它的目标是把错综复杂的数据变为可快速被分析师使用可理解的数据,而且无论从“经纬”还是“编织”来看,都可以快速寻找到你所需要的数据,目前在Gartner和Forrester是这样定义的:
Data Fabric是以一种智能和安全的并且是自服务的方式,动态地协调分布式的数据源,跨数据平台地提供集成和可信赖的数据,支持广泛的不同应用的分析和使用场景。”其专注于对数据集成、转换、准备、策展、安全、治理和编排的自动化,从而实现了快速的数据分析和洞察,帮助业务获得成功。
——Forrester
Data Fabric是一种新兴的数据管理设计理念,可实现跨异构数据源的增强数据集成和共享,通过对现有的、可发现和可推断的元数据资产进行持续分析,来支持数据系统跨平台的设计、部署和使用,从而实现灵活的数据交付。通过散落各处的数据孤岛都能被统一发现和使用,并基于主动元数据进行建设和持续分析,认为数据编织的真正价值在于它能够通过内置的分析技术动态改进数据的使用,同时通过将自动化能力添加到整体数据管理中,使数据管理工作量减少 70% 并加快价值实现速度。
——Gartner
而大模型在数据治理和数据管理方面的力度,我最终认为会实现最终的DataFabric:
Data Fabric是一套新兴的数据管理自服务方式,通过智能化手段对企业的整体数据资源、元数据、业务规则等实现自发现、自分类、自关联,并提供手段可以快速异构同步/查询的方式快速完成数据获取和分析,从而实现企业数据资产全覆盖和高效的数据洞察。
——郭大侠
不止步于数智化的数据治理,
Chat with Your Data最终目标!
这就是结束了么?并不是。我认为最终智能化的数据治理和DataFabric,Chat with Your Data才是目标,也就是让每个有权限的员工,直接可以和企业大模型对话,从而实现对企业数据的访问和分析。
而这也正在一步一步成为现实,现在的ChatGPT,其实是互联网数据通过大量数据训练而成,所以你每次和ChatGPT对话的时候,你是在和整个互联网对话。而现在有很多开源工具,可以让你更简单的接入企业数据,自己训练自己的大模型。如下图,我前面的举例白鲸开源的WhaleLLM的大模型例子就是利用Apache SeaTunnel去获得多大150多种企业数据库同步和访问的权限,利用Apache DolphinScheduler来训练出来自己的DataFabric大模型。每个企业都可以简单的使用这些开源大模型生态来通过比较小的代价(GPU可以使用4090、A40、V100等)来训练自己的大模型。
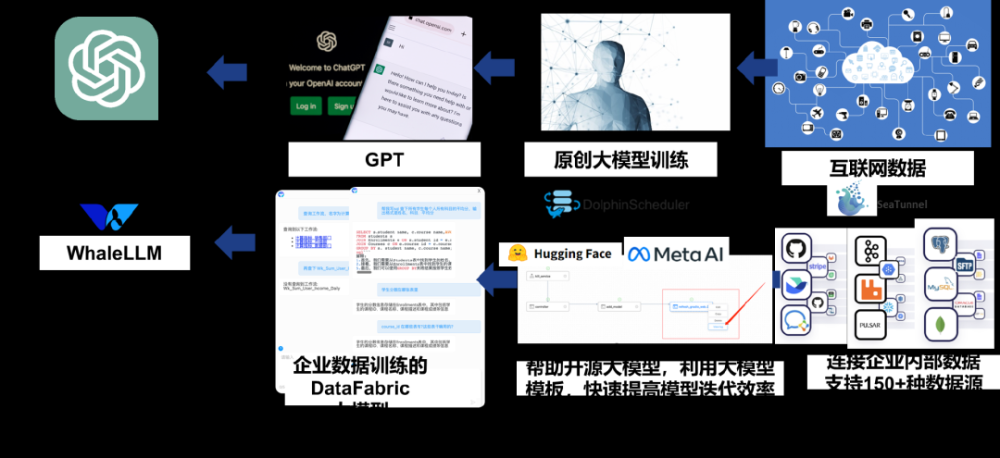
当然,这些开源大模型的训练生态还在迭代,还有很多需要进一步提高的地方,而DataFabric这个概念也是和大模型一样刚开始落地,不过我相信有大模型的助力和DataFabric理念框架的指引,最终在每个企业里都可以拥有自己的人工智能大数据管理平台。
未来几年,企业的“数智化”升级是离不开大模型的助攻,数据治理的“数智化”升级只是开始,私有化开源大模型的进一步普及会让企业各方面的传统软件流程再重新构建一次,让我们拭目以待!
·关于郭炜
郭炜先生,白鲸开源CEO,毕业于北京大学,现任中国通信学会开源技术委员会委员,中国软件行业协会智能应用服务分会副主任委员,Apache基金会成员, Apache孵化器导师,全球中小企业创业联合会副会长,TGO鲲鹏会北京分会会长,ApacheCon Asia DataOps论坛主席,波兰DataOps峰会、北美Big Data Day演讲嘉宾,虎啸十年杰出数字技术人物,中国开源社区最佳33人,中国2021年开源杰出人物。
郭炜先生曾任易观CTO,联想研究院大数据总监,万达电商数据部总经理,先后在中金、IBM、Teradata任大数据方重要职位,对大数据前沿研究做出卓越贡献。同时郭先生参与多个技术社区工作,Presto, Alluxio,Hbase等,是国内开源社区领军人物。
★以上由郭炜投递申报的观点性文章,最终将会角逐由数据猿与上海大数据联盟联合推出的《2023中国企业数智化转型升级先锋人物》榜单/奖项。
该榜单奖项最终将于11月14日以下活动中进行榜单的首发与奖项的颁发,欢迎报名莅临现场:
 文章来源:https://www.toymoban.com/news/detail-717872.html
文章来源:https://www.toymoban.com/news/detail-717872.html
 文章来源地址https://www.toymoban.com/news/detail-717872.html
文章来源地址https://www.toymoban.com/news/detail-717872.html
到了这里,关于【数智化人物展】白鲸开源CEO郭炜:大模型助力企业大数据治理“数智化”升级...的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!