GPT-1🏡
自然语言理解包括一系列不同的任务,例如文本蕴涵、问答、语义相似度评估和文档分类。尽管大量的未标记文本语料库很充足,但用于学习这些特定任务的标记数据却很稀缺,使得判别式训练模型难以达到良好的表现。我们证明,在多样化的未标记文本语料库上进行生成式预训练语言模型,然后在每个具体任务上进行判别式微调,可以实现这些任务的大幅提升。与以往方法相比,我们在微调过程中利用了任务感知型输入转换,从而实现了有效的迁移学习,而对模型架构的改变也是最小化的。我们在自然语言理解的广泛基准测试上展示了我们方法的有效性。
Framework🏣
我们的训练过程包括两个阶段。第一阶段是在大量文本语料库上学习高容量的语言模型。接下来是微调阶段,我们使用带标签的数据将模型适应于不同的任务。

GPT(Generative Pre-trained Transformer)使用的模型是Transformer的Decoder,我们知道BERT使用的模型是Transformer的Encoder。在GPT模型中,start、delim、extract是一些特殊的token,它们分别代表以下含义:
- start:表示生成文本的开始,通常在文本生成任务中,我们需要给定一个开始的文本片段,然后让模型继续生成后续的文本内容。在GPT中,start就是这个开始的标记,可以用于标记生成文本的开始。
- delim:表示文本片段之间的分隔符,通常用于在文本生成任务中,将生成的文本分成多个片段,每个片段之间用delim进行分隔。
- extract:表示从生成的文本中抽取出有意义的部分。在一些文本生成任务中,我们需要将生成的文本中的某些部分提取出来,例如答案、关键词等等。在GPT中,可以用extract标记生成的文本中需要抽取的部分。
上图主要包括两个部分。左侧显示了Transformer的架构和在该工作中使用的训练目标,它们是语言模型预训练和针对不同任务的微调。右侧显示了针对不同任务进行微调时的输入转换方式,这些结构化输入都被转换成由预训练模型处理的令牌序列,然后通过线性+softmax层进行处理。
GPT-2🏪
GPT-2(Generative Pre-trained Transformer 2)相对于GPT-1做了以下几方面的改进:
更大规模的模型:GPT-2使用了更多的参数,达到了1.5亿个参数,比GPT-1的1.17亿个参数更多,从而提高了模型的能力。
更多的训练数据:GPT-2使用了更多、更广泛的文本数据来预训练模型,包括了包括维基百科、网页文本、书籍、新闻、社交媒体等多个来源。
更长的上下文:GPT-2在输入时使用了更长的上下文,即前面的文本内容,这使得模型能够更好地理解文本语境。
更好的遮盖策略:GPT-2采用了更好的遮盖策略来避免模型在预测时泄露后面文本的信息,从而提高了模型的准确性。
更好的生成策略:GPT-2引入了一些新的技术来改进文本生成的策略,包括无偏采样、重复惩罚等,使得生成的文本更加准确和自然。
综上所述,GPT-2相比于GPT-1在模型规模、训练数据、上下文长度、遮盖策略和生成策略等方面都做出了改进,使得其在自然语言处理任务上的表现更加出色。
Zero-Shot💒
GPT-2的zero-shot功能是其最引人注目的特点之一。这意味着,即使在没有进行任何特定任务的监督训练的情况下,GPT-2模型也能够自然地生成与特定任务相关的文本输出。这使得GPT-2模型可以在许多不同的NLP任务上表现出色,而无需进行大量的监督训练。此外,GPT-2还具有非常大的参数容量和表现力,使其成为自然语言处理领域的前沿技术。
GPT-3🏤
GPT-3是GPT模型系列中最新的一款模型,相比于之前的版本有以下改进和新特点:
模型规模更大:GPT-3的模型规模比GPT-2大了数倍,达到了175亿个参数,这使得它能够处理更长、更复杂的文本,并且能够解决一些之前的GPT模型难以处理的任务。
更广泛的语言能力:GPT-3在多种语言的自然语言处理任务上都有出色的表现,包括英语、西班牙语、法语、德语、意大利语、荷兰语、葡萄牙语、俄语、阿拉伯语和中文等多种语言。
支持更多的任务和应用场景:GPT-3不仅可以处理自然语言生成任务,还能够处理一些其他的任务,比如翻译、问答、推理、代码生成等。此外,GPT-3还能够处理一些比较特殊的应用场景,比如情感分析、文本摘要、机器写作等。
Zero-shot 和 Few-shot 能力更强:GPT-3可以通过阅读只有几个例子的新任务来学习如何完成该任务,这使得GPT-3具有更强的Zero-shot 和 Few-shot 能力,能够快速适应新任务并表现出色。
更加灵活的模型结构:GPT-3采用了一种新的模型结构,即可重复模块(可重用模块),使得模型更加灵活和高效。此外,GPT-3还采用了一种新的模型架构,即分层模型架构,使得模型能够自适应不同的任务和输入。
总之,GPT-3是目前自然语言处理领域中最先进的模型之一,具有更广泛的语言能力和更强的任务适应性,可以应用于各种自然语言处理任务和场景中。
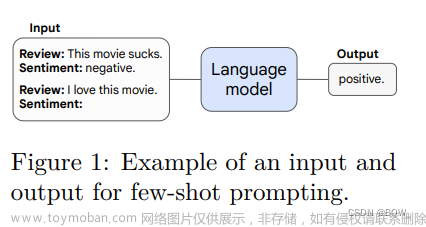
Few-Shot🏯
- GPT-3 (Generative Pre-trained Transformer 3)是OpenAI于2020年发布的最新版本的语言模型。除了具有GPT-2的zero-shot学习能力外,GPT-3还具备了few-shot学习的能力,这是它的一个显著特点和优势。
- Few-shot learning是一种机器学习方法,它可以使模型在仅有少量标注数据的情况下学会新任务。与传统的机器学习方法需要大量标注数据不同,few-shot学习使用少量数据进行训练,能够显著减少数据收集和标注的成本。
- 在GPT-3中,few-shot学习是通过在预训练的语言模型之上引入一个新的递归神经网络(Meta-learner)来实现的。这个递归神经网络可以根据输入的few-shot任务和数据快速学习出一个新的模型,然后将这个新的模型用于实际的任务中。这个过程称为元学习(Meta-learning)。
- 在few-shot学习中,GPT-3使用了所谓的prompt技术。Prompt是指在输入中添加一个特定的文本片段,以提示模型执行特定的任务。在GPT-3中,prompt不仅限于简单的问题和答案,还可以是一系列的指令、约束和条件,从而使模型能够执行更加复杂的任务。
- GPT-3的few-shot学习使得这个模型可以在许多不同的任务上进行快速的适应和学习,并且在很多情况下,它的表现甚至可以超过一些专门为这些任务设计的模型。这使得GPT-3成为了一个强大的通用语言模型,可以应用于许多自然语言处理任务中。

在相同参数量的情况下,Few-Shot的结果更好。
in-context learning🏭
GPT-3的in-context learning是指在进行自然语言处理任务时,将上下文信息引入到模型中以更好地理解和生成文本。传统的自然语言处理模型通常是针对特定任务进行训练的,而且需要大量的标注数据,而GPT-3的in-context learning则允许模型在不需要显式的任务指导和大量标注数据的情况下进行学习。
具体来说,in-context learning可以通过以下两种方式实现:
Prompt-based learning: 在进行自然语言处理任务时,模型会根据给定的提示信息生成相应的文本,这些提示信息可以是文本、问题、任务描述等等。模型在生成文本的同时,可以同时理解上下文信息,从而更好地完成任务。
Generative pre-training: 在in-context learning的训练过程中,模型会预先进行大量的语言模型训练,学习各种类型的文本和语言结构,从而能够更好地理解和生成各种类型的文本。在进行特定任务时,模型可以通过微调来适应该任务,同时也可以通过in-context learning引入上下文信息,从而更好地完成任务。文章来源:https://www.toymoban.com/news/detail-718103.html
总之,GPT-3的in-context learning允许模型在不需要显式的任务指导和大量标注数据的情况下进行学习,并且能够通过引入上下文信息来更好地理解和生成文本。这一特点在自然语言处理领域中具有重要的意义,为实现更加智能和人性化的自然语言处理系统提供了新的思路和方法。与传统的fine-tuning方法不同,GPT-3在所有任务上都没有进行任何梯度更新或微调,拿来即用。文章来源地址https://www.toymoban.com/news/detail-718103.html
Summary🏩
- 在本文中,我们探讨了GPT系列模型的语言理解能力革新。GPT模型的核心是基于Transformer的自回归语言模型,通过无监督学习大规模文本数据,学习到了丰富的语言知识,具备了强大的语言理解能力。GPT-2和GPT-3相比于GPT-1,在模型规模、训练数据和fine-tuning等方面都有了进一步的提升,尤其是GPT-3通过大规模参数和few-shot学习,在NLP任务上取得了极具竞争力的结果。通过GPT系列模型的研究和探索,我们可以看到自然语言处理的发展方向,同时也为我们提供了构建更强大、更智能的语言处理系统的启示。
- 本文大部分内容由chatGPT翻译和生成。
到了这里,关于【深度学习】GPT系列模型:语言理解能力的革新的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!