在数字时代,搜索引擎在通过浏览互联网上的大量可用信息来检索数据方面发挥着重要作用。 此方法涉及用户在搜索栏中输入特定术语或短语,期望搜索引擎返回与这些确切关键字匹配的结果。
虽然关键字搜索对于简化信息检索非常有价值,但它也有其局限性。 主要缺点之一在于它对词汇匹配的依赖。 关键字搜索将查询中的每个单词视为独立的实体,通常会导致结果可能与用户的意图不完全一致。 此外,不明确的查询可能会产生不同的解释,从而导致混合或不准确的结果。
当处理上下文严重影响含义的语言时,会出现另一个关键限制。 词语的含义在很大程度上取决于具体情况。 单独使用关键字可能无法正确捕获这些查询,这可能会导致误解。
随着我们的数字环境不断发展,我们对更精致、更直观的搜索体验的期望也在不断变化。 这为语义搜索的出现铺平了道路,语义搜索是一种旨在超越传统基于关键字的方法的局限性的方法。 通过关注搜索查询的意图和上下文含义,语义搜索为关键字搜索带来的挑战提供了一种有前景的解决方案。

如上面的图片所示,如果我们通过 keyword 来进行搜索,我们想搜索的是 apple 水果,但是我们最终可能得到是关于 apple(苹果)公司的有关信息。其实它并不是我们想要的。
什么是语义搜索?
语义搜索是在互联网上搜索内容的高级方式。 它不仅仅是匹配单词,而是理解你真正在寻找的内容。 它能找出你的话背后的含义以及它们之间的关系。
这项技术使用人工智能和理解人类语言等技术。 几乎就像它在说人类一样! 它着眼于大局,检查具有相似含义的单词以及与你所问问题相关的其他想法。
基本上,语义搜索可以帮助你从互联网上的大量内容中准确获取所需的内容。 这就像与一个超级聪明的搜索引擎交谈,它不仅可以获取你所说的单词,还可以获取你真正想要查找的内容。 这使得它非常适合做研究、查找信息,甚至获得符合你兴趣的建议。

语义搜索的好处
- 精确度和相关性:语义搜索通过理解用户意图和上下文提供高度相关的结果。
- 自然语言理解:它理解复杂的查询,使自然语言交互更加有效。
- 消除歧义:它解决歧义查询,根据用户行为和上下文提供准确的结果。
- 个性化:语义搜索从用户行为中学习以获取定制结果,从而随着时间的推移提高相关性。
Elastic Search 中的语义搜索
Elastic Search 提供语义搜索,重点关注搜索查询的含义和上下文,而不仅仅是匹配关键字。 它使用自然语言处理(NLP)和向量搜索来实现这一目标。 Elastic 有自己的预训练表示模型,称为 Elastic Learned Sparse EncodeR (ELSER)。
在进入 ELSER 之前,让我们更多地了解 NLP 和向量搜索。
自然语言处理(NLP)
自然语言处理是人工智能的一个分支,致力于使计算机能够以有价值且有用的方式理解、解释和生成人类语言。

NLP 涉及一组允许计算机处理和分析大量自然语言数据的技术和算法。 这包括以下任务:
- 文本理解:NLP 帮助计算机理解一篇文章的内容。 它可以找出文本中的重要内容,例如姓名、关系和感受。
- 文本处理:这涉及将句子分解为单词或短语、将单词简化为其基本形式以及识别句子的不同部分等任务。
- 命名实体识别 (NER):NLP 可以识别文本中的特殊事物,例如人名、地名或组织名称。 这有助于理解正在讨论的内容。
向量搜索
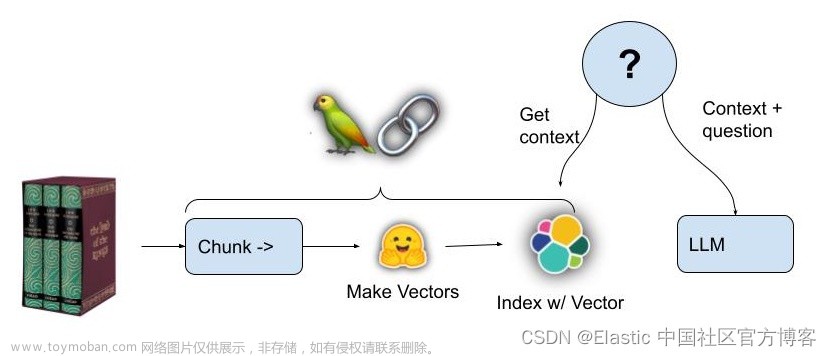
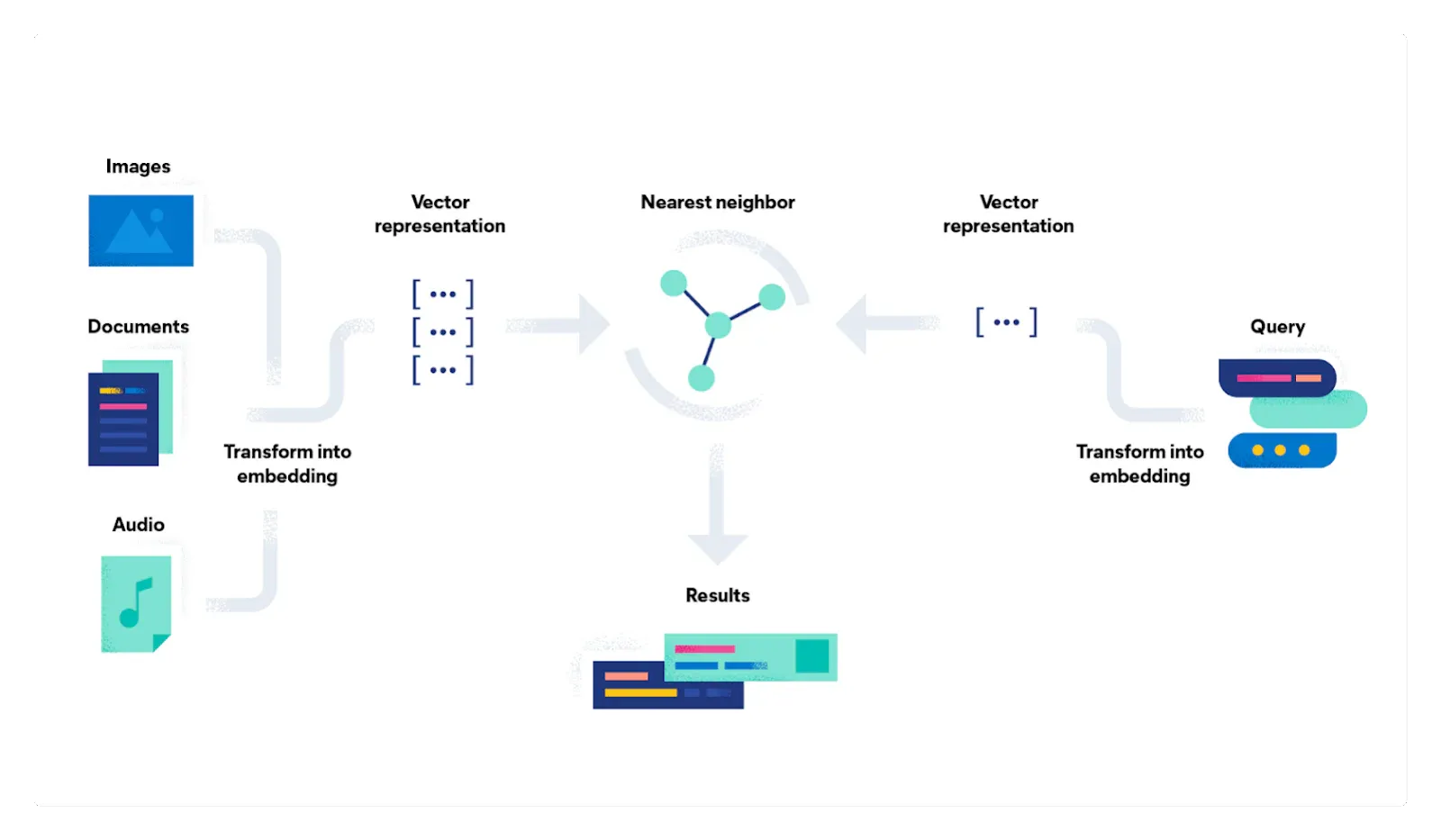
向量搜索是一种涉及将数据点或信息表示为多维空间中的向量的技术。 空间的每个维度代表文档或数据点的不同特征或属性。
在这个向量空间中,相似的文档或数据点彼此距离更近。 这允许有效的基于相似性的搜索。 例如,如果你正在搜索与给定文档相似的文档,则可以计算表示文档的向量之间的相似度以查找最接近的匹配项。
向量搜索广泛用于各种应用,包括:
- 推荐系统:它有助于根据用户的喜好向他们推荐类似的项目。
- 信息检索:它允许在大型语料库中查找相似的文档。
- 异常检测:它有助于识别异常或异常数据点。
NLP 与向量搜索的工作原理

1)Vector embedding:
在此步骤中,NLP 涉及将文本数据转换为数值向量。 使用词嵌入等技术将文本中的每个单词转换为高维向量
2.相似度分数:
引擎将向量化查询与向量化文档进行比较以确定它们的相似性。
3)人工神经网络算法:
近似最近邻 (ANN) 算法可有效查找高维空间中的近似最近邻。
4)查询处理:
用户的查询经历与文档类似的处理以生成向量表示。
5)距离计算:
引擎计算向量化查询和文档之间的距离(相似度分数)。
6)最近邻搜索:
引擎查找嵌入最接近查询嵌入的文档。
7)排名结果:
结果根据相似度分数进行排名。
ELSER
ELSER 是一个经过专门设计的预训练模型,可以出色地理解上下文和意图,而无需进行复杂的微调。 ELSER 目前仅适用于英语,其开箱即用的适应性使其成为各种自然语言处理任务的宝贵工具。 它对稀疏向量表示的利用提高了处理文本数据的效率。 ELSER 的词汇表中包含约 30,000 个术语,通过用上下文相关的对应项替换术语来优化查询,确保精确而全面的搜索结果。
让我们深入探讨如何利用 ELSER 的潜力来增强 Elasticsearch 中的搜索能力。你可以参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR” 来配置自己的 ELSER。
第 1 步:创建具有所需映射的索引
- 在 Elasticsearch 中,“索引 (index)” 是指具有共同特征或属于相似类别的文档的集合。 它类似于关系数据库中的表或其他一些 NoSQL 数据库中的类型。 索引中的每个文档都分配有一个唯一标识符,并且包含 JSON 格式的结构化数据。
- 定义索引的映射,该映射将包含模型根据您的输入生成的 token。 该索引必须有一个 rank_features 字段类型的字段来索引 ELSER 输出。
PUT <index-name>
{
"mappings": {
"properties": {
"ml.tokens": {
"type": "rank_features"
},
"name": {
"type": "text"
}
}
}
}第 2 步:使用推理处理器创建摄取管道
- Elasticsearch 中的摄取管道使您能够在索引之前对数据应用各种转换。 这些转换包括字段删除、文本值提取和数据丰富等任务。
- 管道包含一组称为处理器的可定制任务。 这些处理器以顺序方式运行,对传入文档实施特定修改。使用推理处理器创建摄取管道,以使用 ELSER 对正在摄取的数据进行推理。
PUT _ingest/pipeline/<pipeline-name>
{
"processors": [
{
"inference": {
"model_id": ".elser_model_1",
"target_field": "ml",
"field_map": {
"text": "text_field"
},
"inference_config": {
"text_expansion": {
"results_field": "tokens"
}
}
}
}
]
}第 3 步:将数据添加到索引
- 索引映射和摄取管道已设置,现在我们可以开始向索引添加数据。
- 摄取管道作用于传入数据并将相关标记添加到文档中
curl -X POST 'https://<url>/<index-name>/_doc?pipeline=<ingest-pipeline-name'
-H 'Content-Type: application/json'
-H 'Authorization: ApiKey <Replace_with_created_API_key>'
-d '{
"name" : "How to Adapt Crucial Conversations to Global Audiences"
}'摄取管道作用于传入数据并将相关 token 添加到文档中:
{
"name" : "How to Adapt Crucial Conversations to Global Audiences",
"ml":{
"tokens": {
"voice": 0.057680283,
"education": 0.18481751,
"questions": 0.4389099,
"adaptation": 0.6029656,
"language": 0.4136539,
"quest": 0.082507774,
"presentation": 0.035054933,
"context": 0.2709603,
"talk": 0.17953876,
"communication": 1.0619682,
"international": 0.38651025,
"different": 0.25769454,
"conversation": 1.03593,
"train": 0.021380302,
"audience": 0.97641367,
"development": 0.33928272,
"adapt": 0.90020984,
"certification": 0.45675382,
"cultural": 0.63132435,
"distraction": 0.38943478,
"success": 0.09179027,
"cultures": 0.82463825,
"essay": 0.2730616,
"institute": 0.21582486,
},
"model_id":".elser_model_1"
}
}第 4 步:执行语义搜索
- 使用 text expansion 查询来执行语义搜索。 提供查询文本和 ELSER 模型 ID。
- 文本扩展查询使用自然语言处理模型将查询文本转换为 token 权重对列表,然后将其用于针对 rank_features 字段的查询。
GET <index-name>/_search
{
"query":{
"text_expansion":{
"ml.tokens":{
"model_id":".elser_model_1",
"model_text":<query_text>
}
}
}
}第 5 步:将语义搜索与其他查询结合起来
- 我们还可以将 text_expansion 与复合查询中的其他查询结合起来,以获得更精细的结果。
GET my-index/_search
{
"query": {
"bool": {
"should": [
{
"text_expansion": {
"ml.tokens": {
"model_text": <query_text>,
"model_id": ".elser_model_1",
}
}
},
{
"query_string": {
"query": <query_text>,
}
}
]
}
}
}我们还可以将 text_expansion 与复合查询中的其他查询结合起来,以获得更精细的结果。
与 Elasticsearch 中的其他查询相比,text_expansion 查询通常会产生更高的分数。 我们可以使用 boost 参数调整相关性分数。
更多阅读:
-
Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR
-
Elasticsearch:使用 ELSER 进行语义搜索文章来源:https://www.toymoban.com/news/detail-718119.html
-
Elasticsearch:使用 ELSER 释放语义搜索的力量:Elastic Learned Sparse EncoderR文章来源地址https://www.toymoban.com/news/detail-718119.html
到了这里,关于Elasticsearch:使用 Elasticsearch 进行语义搜索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!