如何处理数据集中的缺失值,以便更准确地进行数据分析或模型训练?
在数据分析和机器学习中,数据的完整性和准确性至关重要。但现实情况是,收集到的数据往往存在缺失值。例如,医疗研究中可能缺少某些患者的体重、年龄或血压等信息。这样的缺失值会对数据分析或模型训练产生不良影响。
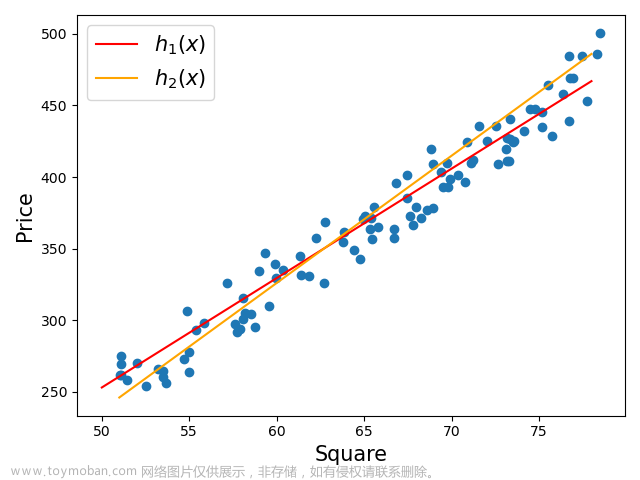
假设一个小型医院需要分析患者的多项身体指标(如体重、身高、血压和血糖)以预测其是否有糖尿病风险。收集到的数据可能如下:文章来源:https://www.toymoban.com/news/detail-718534.html
| 体重(kg) | 身高(cm) | 血压(mmHg) | 血糖(mmol/L) |
|---|---|---|---|
| 70 | 175 | 120 | 5.5 |
| 60 | 160 | 4.8 | |
| 170 | 130 | 6.0 | |
| 75 | 180 | 125 |
注意到有些数据是缺失的。一个简单但有效的方法是使用邻近数据进行插值,即通过观察“邻居”的数据来填充缺失值。这就是KNN(K-Nearest Neighbors)插值算法的基本思想。文章来源地址https://www.toymoban.com/news/detail-718534.html
到了这里,关于【Python机器学习】零基础掌握SimpleImputer缺失值填充的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!