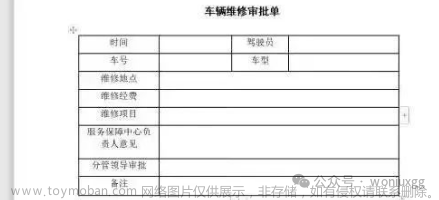
1. 引入依赖
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext7-core</artifactId>
<version>8.0.1</version>
</dependency>
2. 代码实现
import com.itextpdf.kernel.geom.PageSize;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.layout.Document;
import com.itextpdf.layout.element.Paragraph;
import com.itextpdf.layout.property.TextAlignment;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class XmlToPdf {
public static void main(String[] args) throws Exception {
// 读取XML文件
File xmlFile = new File("example.xml");
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(xmlFile);
doc.getDocumentElement().normalize();
// 创建PDF文档
PdfWriter writer = new PdfWriter("output.pdf");
PdfDocument pdf = new PdfDocument(writer);
Document pdfDoc = new Document(pdf, PageSize.A4);
// 遍历XML元素并将其添加到PDF文档中
processNode(pdfDoc, doc.getDocumentElement());
// 关闭文档
pdfDoc.close();
}
private static void processNode(Document pdfDoc, Node node) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
Paragraph paragraph = new Paragraph(element.getTextContent())
.setTextAlignment(TextAlignment.CENTER);
pdfDoc.add(paragraph);
}
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
processNode(pdfDoc, children.item(i));
}
}
}
文章来源地址https://www.toymoban.com/news/detail-718866.html
文章来源:https://www.toymoban.com/news/detail-718866.html
到了这里,关于xml导出pdf简单实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!