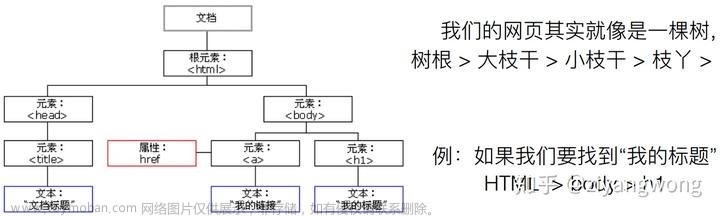
一、Requests库的安装
以管理员身份运行命令控制台,输入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests

测试:打开IDLE

此时百度的html页面被抓取成功
二、requests库的7个主要方法

三、Requests库的get()方法:获得一个网页

完整使用方法:
 Requests库的get()方法源代码:get方法实际上使用request方法来封装, 也就是说,除了request方法是基础方法,其他6个方法都是通过调用request方法实现的,即实际上只有一个方法。
Requests库的get()方法源代码:get方法实际上使用request方法来封装, 也就是说,除了request方法是基础方法,其他6个方法都是通过调用request方法实现的,即实际上只有一个方法。

四、Requests库的2个主要对象
 下面重点来看Response对象:
下面重点来看Response对象:
Response 对象包含服务器返回的所有信息,还包含了向服务器请求的request信息

Response对象的5个常用属性:

五、使用get()方法获取页面内容的基本流程
 关于Requests的编码:
关于Requests的编码: 
 ISO-8859-1不能解析中文,apparent_encoding比encoding更加准确,因为encoding并没有分析内容。所以,一般用encoding不能正确解析中文页面内容时,用apparent_encoding的值替换encoding文章来源:https://www.toymoban.com/news/detail-719168.html
ISO-8859-1不能解析中文,apparent_encoding比encoding更加准确,因为encoding并没有分析内容。所以,一般用encoding不能正确解析中文页面内容时,用apparent_encoding的值替换encoding文章来源:https://www.toymoban.com/news/detail-719168.html
 文章来源地址https://www.toymoban.com/news/detail-719168.html
文章来源地址https://www.toymoban.com/news/detail-719168.html
到了这里,关于网络爬虫-Requests库入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!