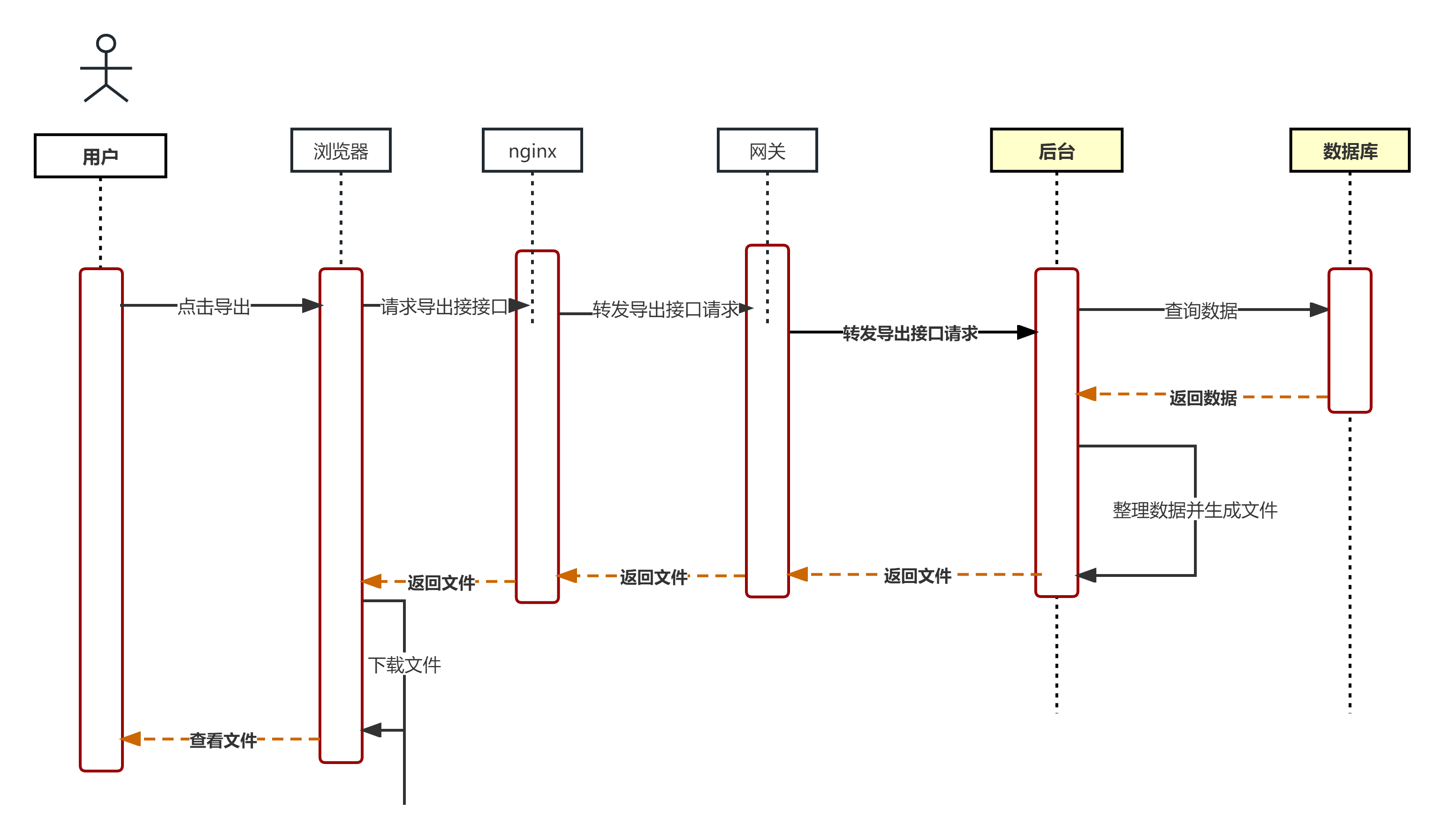
知识点复习:
什么是数据流定向,个人理解就是将 一些结果信息不打印在屏幕上,而是定位在某一个文件里面
ll /wdf > file 会覆盖file的原内容
ll /wdf >> 会追加到原文件后面
比如在自己的目录新建1.TXT, 2.txt
ll /home/wdf > list
cat list
然后增加3.txt
ll /home/wdf >>list
cat list #此时会显示3个文件,如果把>>改成> ,那么就会覆盖原有内容,变成一个文件记录了
注意,错误的信息不回写入到定向的文件里面,有三个定义;
标准输入<,<<,标准输出1>,1>>,标准错误输出2>,2>>
其中<<'eof'表示输入eof就停止了,这个要注意下
例如:一般用户模式下
find /home -name .bashrc >list_right 2>>list_error

命令执行后,前两行信息会送到list_error,最后一行送到list_right里面
如果将错误的返回信息丢弃可以>/dev/null
重点来了,如果想写如一个文件呢?如何实现
>list_right 2>&1 或者 &>list_right

标准输入< 和<<
代替键盘输入创建新文件的流程
cat > catfile<~./,batshrc
<<代表的是结束输入的意思
cat >catfile<<'eof'
命令判断依据:
;多个命令 在一行执行可以用;分割,sync;sync;shutdown -h now
&&判断前一命令是否正确执行,如果执行 则执行后面命令
||前面命令非正确执行,执行后面命令
command1 && command2 ||command3
经典的判断 类似exp?a:b
管道命令:cut,grep,sort,wc,uniq,双重定向tee,字符串转换命令:tr,col,jion,paste,expand ,切割split
个人感觉这些命令在使用的时候在研究就可以,小白看完啥感觉也没有,用法还是不熟悉,可能实践的太少了
这些配合 | 使用
echo $PAHT | cut -d ":" -f 5
-d:表示分隔符
-f:表示第几段的意思
将path的值按:分割,并将第五列信息显示到屏幕上
grep这个比较数据,经常用来某个程序的,常用
ps -ef |grep weblogic
查看weblogic进程信息
配合使用
last | grep 'root' |cut -d " " -f 1
这个意思很明显,找到last内有root的信息,以空格分割,显示第一列
sort
排序,也是在管道后接sort ,参数很多,自己看吧
cat /etc/passwd |sort
将passwd的信息排序并输出到屏幕上
wc
常用显示行数,字数,字符数
cat /etc/man.config |wc
uniq去重,重复的记录只显示一行
tee双重定向,这个和>,>>,2>,2>>可以对比学习
tee顾名思义,就是将文件分别送到文件和屏幕 上
ls -l /home |tee ~/homefile |more #将ls的数据存一份到homefile里面,并在屏幕上输出
tr:删除或者替换
-d:删除
cat /etc/passwd | tr -d ':' #删除结果集中的:
替换 last |tr [a-z] [A-Z],#将结果集数据转为大写
col 可以将tab换成空格
cat -A /etc/man.config #显示所有特殊字符,空格,tab,回车等
cat -A /etc/man.config |col =x #将tab换成对等的空格,用-x控制
join 操作两个文件
join -t ':' -1 4 /home/file1 -2 3 /home/fie2
将1,2文件用:分割,整合第一个文件的第四列,第二个文件的第三列,整合成一个文件
一般先找到两个文件分割后的相同列,然后在join,可以用来对比文件
paste比join简单,直接在一行后面追加默认空格分割
past /home/file /home/file2
file-xxxxx file2-xxxxx
expand 将tab转空格 和col区别是,这个可以自定义字符,一个tab默认8个字符,可以自定义
grep ‘^MANPATH’ /etc/man.config | head -n 3|expand -t 6 |cat -A
配置文件找到内容MANPATH想关信息,取前三行,显示特殊字符,将其中的tab换成6空格后显示输出
split分割,多用来将大文件分割成小文件,方便读取
按照文件大小分割 -b
按照行数分割 -l
ls -al / |split -l 10 - lsroot #根目录列表信息,每10条记录创建一个文件,文件名前缀lsroot【aa,ab,ac】 其中 “-”经常代表标准的输入,这个暂时不太理解,等有时间多看看其他博主的说明吧。文章来源:https://www.toymoban.com/news/detail-719785.html
文章只是本人笔记,非常简陋,仅供参考文章来源地址https://www.toymoban.com/news/detail-719785.html
到了这里,关于linux中好玩的数据流定向和管道命令一的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!