前置工作
配置host文件
在每个节点的/etc/hosts文件下加入
192.168.3.73 master
192.168.3.66 slave1
192.168.3.61 slave2
确保可以相互ping通
[root@host-192-168-3-73 ~]# ping slave1
PING slave1 (192.168.3.66) 56(84) bytes of data.
64 bytes from slave1 (192.168.3.66): icmp_seq=1 ttl=64 time=0.589 ms
64 bytes from slave1 (192.168.3.66): icmp_seq=2 ttl=64 time=0.476 ms
64 bytes from slave1 (192.168.3.66): icmp_seq=3 ttl=64 time=0.490 ms
64 bytes from slave1 (192.168.3.66): icmp_seq=4 ttl=64 time=0.528 ms
^C
--- slave1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 0.476/0.520/0.589/0.051 ms
跳转顶部
ssh免密登录
执行命令ssh-keygen -t rsa -P '',然后回车即可
[root@host-192-168-3-73 ~]# ssh-keygen -t rsa -P ''
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:MtzaPUXxJdLDLcvwLxQqWH7HQkr20m7rUgL48IF9f/U root@host-192-168-3-73
The key's randomart image is:
+---[RSA 2048]----+
| oo...|
| + o+*o.|
| + * =.*.= |
| .+.= *.* B .|
| ++S+ *.+ o.|
| =o...= o E|
| . . o+ o . |
| ... |
| o. |
+----[SHA256]-----+
查看/root下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。,因为我是使用root用户来配置的,所以在这目录下,若你使用的时其他用户,则需要在/home/User目录下寻找.ssh目录
[root@master .ssh]# pwd
/root/.ssh
[root@master .ssh]# ll
total 8
-rw-------. 1 root root 1675 Mar 16 16:02 id_rsa
-rw-r--r--. 1 root root 393 Mar 16 16:02 id_rsa.pub
将 id_rsa.pub 追加到授权key文件中
cat id_rsa.pub >> authorized_keys
修改文件权限,若使用的时管理员用户则不需要
chmod 600 authorized_keys
修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容,需要将该配置字段前面的#号删除,启用公钥私钥配对认证方式。
PubkeyAuthentication yes
重启服务
systemctl restart sshd
尝试本机嵌套登录,如能不输入密码就表示本机通过密钥登陆验证成功
[root@master .ssh]# ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:Hr69gEn5JbaH3pZPvyJ9qhzyCzPYIyleYQyqA+vPz3U.
ECDSA key fingerprint is MD5:f6:f4:9e:7d:c5:b1:8f:68:db:a3:49:66:05:6e:e4:c4.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Last login: Wed Mar 16 15:41:55 2022 from 192.168.0.1
将 Master 节点的公钥 id_rsa.pub 复制到每个 Slave 点,注意不要复制到相同目录下,否则会直接覆盖,建议放到前一个目录
scp id_rsa.pub root@slave1:/root/
[root@master .ssh]# scp id_rsa.pub root@slave1:/root/
The authenticity of host 'slave1 (192.168.0.163)' can't be established.
ECDSA key fingerprint is SHA256:HCyXDBNPToF3n/6WgB/Sj8M9z3IHaGy8CRVTJY6YqQs.
ECDSA key fingerprint is MD5:2e:16:4d:94:00:05:ff:c5:8e:13:08:6a:6a:a9:02:f8.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'slave1,192.168.0.163' (ECDSA) to the list of known hosts.
root@slave1's password:
id_rsa.pub 100% 393 314.0KB/s 00:00
在每个Slave 点把 Master 节点复制的公钥复制到 authorized_keys 文件
cat id_rsa.pub >> .ssh/authorized_keys
删除文件
rm -fr id_rsa.pub
将slave1的公钥发送到master
scp .ssh/id_rsa.pub root@master:/root/
The authenticity of host 'master (192.168.0.162)' can't be established.
ECDSA key fingerprint is SHA256:Hr69gEn5JbaH3pZPvyJ9qhzyCzPYIyleYQyqA+vPz3U.
ECDSA key fingerprint is MD5:f6:f4:9e:7d:c5:b1:8f:68:db:a3:49:66:05:6e:e4:c4.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.0.162' (ECDSA) to the list of known hosts.
root@master's password:
id_rsa.pub 100% 393 493.3KB/s 00:00
在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件
cat id_rsa.pub >> .ssh/authorized_keys
删除文件
rm -fr id_rsa.pub
查看master节点的authorized_keys文件,可以发现有两个公钥
[root@master ~]# cat .ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDIgiraYbUS+wal7gSzx/kpuZ+ZPnE1Tc+u1QVi25i3ZgoBTOFqjTv973xy3ueExn1udYGmhDDB+vXFxNs2AIgXZEoEpgZAz2kcAEJBjkXT0p8sYXgaliMMFNP8dwiJTCs/YIDol+KIIkIwa3WbQoVEc1zQH1+Xr1Rto1IgLXPRgXO3IMfmX7nqc2ZMdBt0OaPDf2NtBI3e/QDEa59f6J+ge4r8MPuc9C51MeU6NPr20A99Psy1Jbvrr7/Fb2pLxnfne50+4DYjsGPztOgHuQFWoAQ+LDUW6Xhbs5Ig8bUEHt1AILwyNwagJvcsGIvp3wOQt+HRHxJCoAjgPeFsFwJF root@master
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCoPA9uCf/PmUgbpmbPF13VvIwJiSHqAVIpffylbk2g+mEJQMnLxmYv4AVsdc3Wjul2rUMoQh4RPeMFFFincrYFN88DA6SF0F9ZNQOy+6p7CWxLd24hrsn7J69Pab0HxIlMAng8zKjAxZKAOBWyih1nJzqf3UHNdAeZkoe8MbNf6jTXM67vGa0V0FUFU/GvX6st8fLDbROKB8kh1N2X/qLNFiDgxY3Vm1rgN4cDGhs/UqugOHgwnvUScUkjoDQyGn/vYfgHxThHoF+Dv57Xa+bjyUbMmIQYgH7xR/V25F3iU6no3P0LmWsVc4uTTZwdcsPpxMcAfDFL+u5cnivtKrdj root@slave1
这时可以从master节点来登录slave
[root@master ~]# ssh slave1
Last login: Tue Mar 15 12:18:56 2022 from ::1
[root@slave1 ~]#
需要将每一个节点的公钥都交换
跳转顶部
JDK的配置
将文件解压到指定目录:tar -zxvf jdk-8u162-linux-x64.tar.gz -C /home/
重命名mv jdk1.8.0_162/ jdk
配置环境变量:vi /etc/profile
export JAVA_HOME=/home/jdk
export PATH=$PATH:$JAVA_HOME/bin
使其立即生效
source /etc/profile
测试
[root@host-192-168-3-73 home]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
将jdk转发
scp -r /home/jdk slave1:/home
scp -r /home/jdk slave2:/home
[root@host-192-168-3-73 home]# scp /etc/profile slave1:/etc/
profile 100% 1880 1.2MB/s 00:00
[root@host-192-168-3-73 home]# scp /etc/profile slave2:/etc/
profile 100% 1880 1.2MB/s 00:00
跳转顶部
ZooKeeper配置
解压缩:tar -zxvf zookeeper-3.4.5.tar.gz -C /home/
重命名:mv zookeeper-3.4.5/ zookeeper
在根目录下创建两个文件夹
mkdir logs
mkdir data
加入conf目录,生成文件:cp zoo_sample.cfg zoo.cfg
并且修改文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/zookeeper/data
dataLogDir=/home/zookeeper/logs
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2889:3889
server.3=slave2:2890:3890
分发
scp -r /home/zookeeper/ slave1:/home/
scp -r /home/zookeeper/ slave2:/home/
在每个节点的zookeeper/data目录下写入
echo '1' > data/myid
echo '2' > data/myid
echo '3' > data/myid
启动:bin/zkServer.sh start
查看状态
[root@host-192-168-3-73 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper/bin/../conf/zoo.cfg
Mode: follower
跳转顶部
Hadoop HA配置文件
解压缩:tar -zxvf hadoop-2.7.7.tar.gz -C /home/
创建目录
mkdir logs
mkdir tmp
mkdir -p dfs/name
mkdir -p dfs/data
修改slaves文件
slave1
slave2
修改hadoop-env.sh文件
export JAVA_HOME=/home/jdk
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<!-- hadoop 链接 zookeeper 的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
跳转顶部
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>n1,n2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.n1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.n2</name>
<value>slave1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.n1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.n2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<!-- journalnode 集群之间通信的超时时间 -->
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>60000</value>
</property>
跳转顶部
mapred-site.xml
<!-- 指定 mr 框架为 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定 mapreduce jobhistory 地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 任务历史服务器的 web 地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
跳转顶部
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>r1,r2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.r1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.r2</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.r1</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.r2</name>
<value>slave1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
跳转顶部
启动与测试
分发
scp -r /home/hadoop slave1:/home
scp -r /home/hadoop slave2:/home
每个节点需要先启动journalnode
sbin/hadoop-daemon.sh start journalnode
格式化namenode
bin/hadoop namenode -format
将已格式化的namenodetmp目录传给另一个namenode
[root@host-192-168-3-73 hadoop]# scp -r dfs/ slave1:/home/hadoop/
VERSION 100% 205 130.7KB/s 00:00
seen_txid 100% 2 1.6KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 68.6KB/s 00:00
fsimage_0000000000000000000 100% 321 270.9KB/s 00:00
或者使用命令:bin/namenode -bootstrapStandby
格式化zkfc
bin/hdfs zkfc -formatZK
在每个namenode节点上启动zkfc
sbin/hadoop-daemon.sh start zkfc
启动集群
sbin/start-all.sh
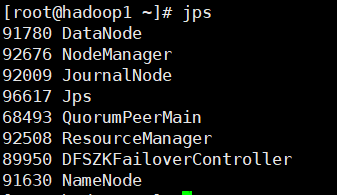
查看集群的进程
# namenode1
2752 NameNode
2326 JournalNode
2568 DFSZKFailoverController
1897 QuorumPeerMain
3035 ResourceManager
3182 Jps
# namenode2
2080 NodeManager
2194 Jps
1763 JournalNode
1861 DFSZKFailoverController
1656 QuorumPeerMain
1992 DataNode
1933 NameNode
# datanode
1953 NodeManager
1866 DataNode
1659 QuorumPeerMain
2107 Jps
1773 JournalNode
查看webui


杀死活跃的主节点
kill -9 2752

一些命令文章来源:https://www.toymoban.com/news/detail-719826.html
# 强制切换成等待
bin/hdfs haadmin -transitionToStandby -forcemanual nn1
# 强制切换成活跃
bin/hdfs haadmin -transitionToActive -forcemanual nn1
跳转顶部文章来源地址https://www.toymoban.com/news/detail-719826.html
到了这里,关于【Hadoop HA】搭建Hadoop HA的详细教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!