收藏关注不迷路
前言
随着电子技术的普及和快速发展,线上管理系统被广泛的使用,有很多商业机构都在实现电子信息化管理,图书推荐也不例外,由比较传统的人工管理转向了电子化、信息化、系统化的管理。
传统的图书推荐管理,一开始都是手工记录,然后将手工记录的文档进行存档;随着电脑的普及,个性化智能图书推荐管理演变成了手工记录后,输入电脑进行存档。传统的管理方式,对管理者来说工作量大。而且这种图书推荐管理的方式,容易出现遗失或因为失误输入错误的信息等等。在这些基础上,我把python技术的图书馆书目推荐数据分析与可视化荐系统作为我的毕业设计,希望可以解决图书推荐管理中出现的问题,简化工作人员的压力,也可以方便管理员进行系统化、电子化的管理。
一、项目介绍
建立本图书馆书目推荐数据分析是为了通过系统对图书数据根据算法进行的分析好推荐,以方便用户对自己所需图书信息的查询,根据不同的算法机制推荐给不同用户不同的图书,用户便可以从系统中获得图书信息信息。本系统旨在建立用户、管理者、图书三者之间的桥梁关系,从而使用户能及时有效的从管理者手中获取到信息。所以我们认为建立一个网上图书馆书目推荐数据分析是非常必要的,其方便高效、简单快捷的管理模式是很有使用性的。
通过图书馆书目推荐数据分析与可视化系统的研究可以更好地理解系统开发的意义,而且也有利于发展更多的智能系统,解决了人才的供给和需求的平衡问题,图书馆书目推荐数据分析与可视化系统的开发建设,由于其开发周期短,维护方便,所以它可以适应个性化智能图书推荐体系的基本要求。
二、开发环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
系统采用的技术包括,Python网络爬虫,pandas,numpy数据分析,flask后端框架,前端采用bootstrap,echarts和JavaScript进行渲染和交互,sqlite关系数据库,轻量级mysql。论文内容基于该图书馆书目推荐数据分析系统的实现分为两个部分,爬虫部分,和爬取的数据进行分析展示。
本课题对图书馆的书籍和用户数据进行采集,使用Python技术进行数据整理并存储MySQL数据库中;采用numpy技术进行数据分析,在结合图书馆书籍借阅的具体特征的基础上,提出适用于馆藏书籍的个性化推荐模型;对用户相关数据进行分析,为相似度较高的用户建立邻居关系,基于协同过滤算法产生符合用户兴趣的个性化图书资源列表;最后对推荐结果进行排序,并通过可视化技术展示出来 。然后使用Python专门的数据可视化库echarts进行可视化展示,所以要选取数据维度较多的数据源进行采集爬取。并且根据各个方向进行了图表的设计和测试数据的完善。
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
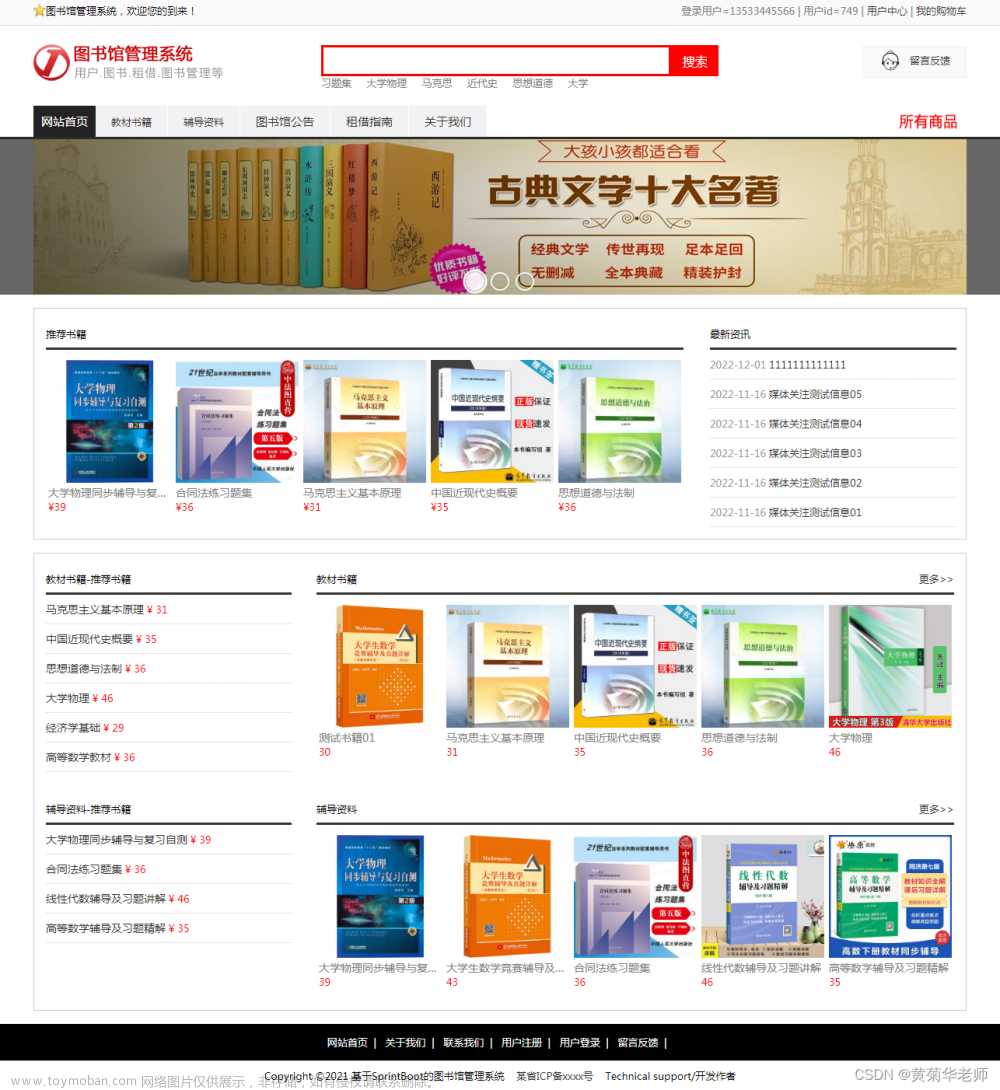
五、效果图








 文章来源:https://www.toymoban.com/news/detail-719918.html
文章来源:https://www.toymoban.com/news/detail-719918.html
六、文章目录
目 录
摘 要 I
ABSTRACT II
目 录 II
第1章 绪论 1
1.1背景及意义 1
1.2 国内外研究概况 1
1.3 研究的内容 1
第2章 相关技术 3
2.1 Python简介 4
2.2 Django 框架介绍 6
2.3 B/S结构 4
2.4 MySQL数据库 4
第3章 系统分析 5
3.1 需求分析 5
3.2 系统可行性分析 5
3.2.1技术可行性:技术背景 5
3.2.2经济可行性 6
3.2.3操作可行性: 6
3.3 项目设计目标与原则 6
3.4系统流程分析 7
3.4.1操作流程 7
3.4.2添加信息流程 8
3.4.3删除信息流程 9
第4章 系统设计 11
4.1 系统体系结构 11
4.2开发流程设计系统 12
4.3 数据库设计原则 13
4.4 数据表 15
第5章 系统详细设计 19
5.1管理员功能模块 20
5.2用户功能模块 23
5.3前台功能模块 19
第6章 系统测试 25
6.1系统测试的目的 25
6.2系统测试方法 25
6.3功能测试 26
结 论 28
致 谢 29文章来源地址https://www.toymoban.com/news/detail-719918.html
到了这里,关于python爬虫分析基于python图书馆书目推荐数据分析与可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[N-117]基于微信小程序图书馆管理系统](https://imgs.yssmx.com/Uploads/2024/02/791594-1.png)





