项目场景:
需求:需要在之前上线的分区报表中新增加一列。
实现方案:
1、创建分区测试表并插入测试数据
drop table test_1;
create table test_1
(id string,
score int,
name string
)
partitioned by (class string)
row format delimited fields terminated by ',';
insert overwrite table test_1
partition (class='A')
values('a',92,'lily'),('b',102,'mike');
查看原有分区表test_1的表结构
desc test_1;

2、新增加一列 grade,数据类型为strIng
alter table test_1 add columns(grade string);
查看添加列之后的数据结构
desc test_1;

3、新增加列grade有数据后,插入新的分区B数据正常显示,原来A区grade列为NULL。
insert overwrite table test_1
partition (class='B')
values('a',92,'John','良好'),('b',112,'Jeff','优秀');
select * from test_1;

原因是: hive使用新增加列语句,只修改了hive的元数据, 并没有改变hdfs的数据文件。
显示Table和Partition的详细信息,及表数据存放的hdfs的数据文件路径。
desc formatted test_1;

查看具体分区的hdfs的数据文件路径
hadoop fs -lsr hdfs://b1/apps/database/hive/database/test_1

查看A、B两个分区下的hdfs的数据文件的内容,发现A区并没有grade的内容。
A区:
hadoop fs -cat hdfs://b1/apps/database/hive/database/test_1/class=A/000000_0

B区:
hadoop fs -cat hdfs://b1/apps/database/hive/database/test_1/class=B/000000_0

问题描述:
为了表的旧分区新增加列有数据,尝试重新写入A区的数据,发现A区新增列还是为NULL,重写分区后只有最新分区(B区)的新增列有数据。
insert overwrite table test_1
partition (class='A')
values('a',92,'lily','良好'),('b',102,'mike','良好');
select * from test_1;

原因分析:
“alter table test_1 add columns(grade string);”,hive新增加列只修改了更新分区的表结构(metadata),没有变更旧分区的表结构。
表的表结构
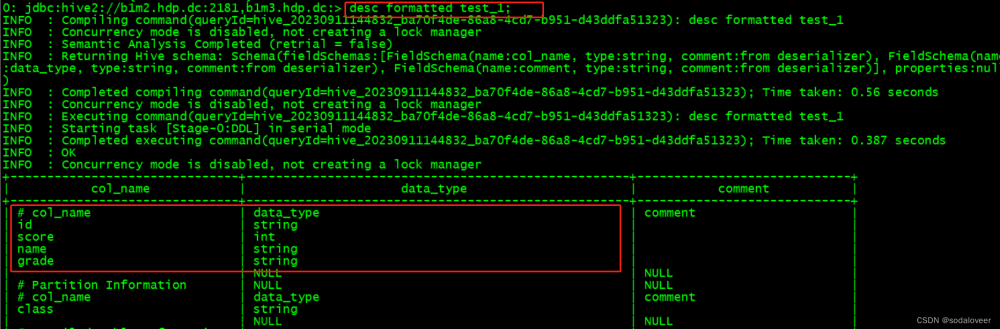
A分区的表结构
desc formatted test_1 partition(class='A');

B分区的表结构
desc formatted test_1 partition(class='B');

查看表的表结构和新增分区的表结构(B区)是一致,与旧分区的表结构(A区)不一致。
解决方案:
- 方法一:删除原来的分区数据重新插入
alter table test_1 drop partition (class='A');
insert overwrite table test_1
partition (class='A')
values('a',92,'lily','良好'),('b',102,'mike','良好');
select * from test_1;

- 方法二: 最初,需要在增加grade时加上cascade关键字,cascade的中文翻译为“级联”,也就是不仅变更新分区的表结构(metadata),同时也变更旧分区的表结构。
添加列的语法
ALTER TABLE table_name
[PARTITION partition_spec] -- (Note: Hive 0.14.0 and later)
ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
[CASCADE|RESTRICT]
注意:ALTER TABLE ADD|REPLACE COLUMNS with CASCADE command changes the columns of a table’s metadata, and cascades the same change to all the partition metadata. RESTRICT is the default, limiting column changes only to table metadata.
drop table test_1;
create table test_1
(id string,
score int,
name string
)
partitioned by (class string)
row format delimited fields terminated by ',';
insert overwrite table test_1
partition (class='A')
values('a',92,'lily'),('b',102,'mike');
alter table test_1 add columns(grade string) cascade;
insert overwrite table test_1
partition (class='A')
values('a',92,'lily','良好'),('b',102,'mike','良好');

如果已经执行添加操作,并且没有带cascade,可以尝试下面的方法:
alter table test_1 replace columns(id string ,score int,name string);
再重新带上cascade进行添加列的操作。
扩展
需求:增加一列,指定增加到原始的两列中间
1、新增加列grade
alter table test_1 add columns (grade string comment '新添加的列') cascade;

2、再对grade列进行排序(注意:必须添加cascade关键字,不然不会刷新旧分区数据,关键字cascade能修改元数据)
更新列的语法文章来源:https://www.toymoban.com/news/detail-720155.html
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
--将grade增加到score列与name中间
alter table test_1 change column grade grade string after score cascade;
 文章来源地址https://www.toymoban.com/news/detail-720155.html
文章来源地址https://www.toymoban.com/news/detail-720155.html
到了这里,关于【hive】—原有分区表新增加列(alter table xxx add columns (xxx string) cascade;)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








