1、合并行/列
合并行:t1.join(t2)相当于t1左关联t2,通过行索引关联,保留t1、t2全部字段,t1、t2列重复会报错
合并列:t1.merge(t2,left_on=column1,right_on=column2,how=‘inner’),t1连接t2,通过t1的field1与t2的field2字段连接,有相同的字段可以通过on指定,默认how为inner内连接取交集,outer为外连接取并集,left左连接,right右连接,NaN补全
2、分组与聚合
grouped=df.groupby(by=column1):获得元组(columns取值,分组后的dataframe)为元素的DataFrameGroupBy对象,可以循环遍历。
grouped[column2].count()或grouped.count()[column2]:对group by column1计数,不限制column2则对所有列计数。常用的统计函数有count(分组中非NA的数量)、sum(非NA的和)max、min、mean(非NA的均值)、median(非NA的中位数)、std(无偏标准差)、var(无偏方差)。
df.groupby(by=[df[col1],df[col2]])或df.groupby(by=[col1,col2]):对多列进行分组
df[col3].groupby(by=[df[col1],df[col2]]).count()或df.groupby(by=[col1,col2])[col3].count():结果为series,col1、col2组成复合索引,若先选列再分组,则by中必须加df。
df[[col3]].groupby(by=[df[col1],df[col2]]).count()或df.groupby(by=[col1,col2])[[col3]].count():结果为dataframe,col1、col2组成复合索引。
3、行索引
df.index:获取行索引,对于复合索引level为每一索引列的可能取值,name为索引列名称
df.index=[a,b]:设置行索引
df.reindex([i1,i2]):筛选行索引,不存在的行取值为空
df.set_index([col1,col2],drop=True)或df.set_index(col1,drop=True):将已有列设置为索引,drop为True会删列(默认)
df.index.unique():行索引可以重复
从复合索引取值:
s[外层索引][内层索引]:从series取值
df.loc[外层索引].loc[内层索引]:从dataframe取数
若要对内层索引取数可以通过df.swaplevel()交换内外层索引位置
dataframe[[col]]:获取单列的dataframe
4、操作案例1
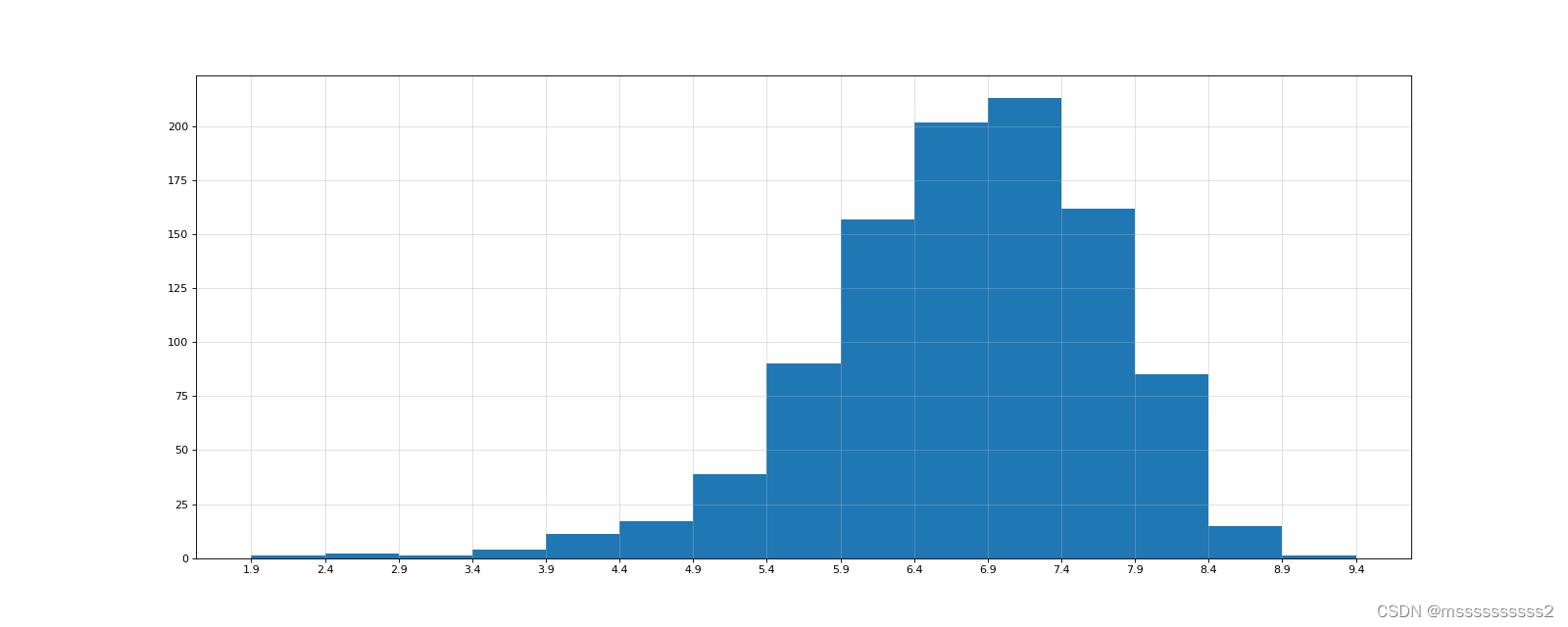
对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
import pandas as pd
import matplotlib.pyplot as plt
path='IMDB-Movie-Data.csv'
movie_data=pd.read_csv(path)
pd.set_option('display.max_columns',None)
print(movie_data.head(1))
Rating_max=movie_data['Rating'].max()###最大值
Rating_min=movie_data['Rating'].min()###最小值
bin_num=(Rating_max-Rating_min)//0.5
bin_list=[Rating_min+0.5*i for i in range(int(bin_num+2))]##分组
print(bin_list)
plt.figure(figsize=(20,8),dpi=80)
plt.hist(movie_data['Rating'],bin_list)
plt.xticks(bin_list)
plt.grid(alpha=0.4)
plt.show()
'''
5、操作案例2
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
代码1
import pandas as pd
import numpy as np
path='IMDB-Movie-Data.csv'
movie_data=pd.read_csv(path)
pd.set_option('display.max_columns',None)
print(movie_data.head(1))
#获取分类的列表
Genre_series=movie_data["Genre"].str.split(',').tolist()
Genre_set=set([j for i in Genre_series for j in i ])
#构建全0数组
Genre_dataframe=pd.DataFrame(np.zeros((movie_data.shape[0],len(Genre_set))),columns=Genre_set)
###对每行进行迭代#给每个电影出现分类的位置赋值1
for i in range(len(Genre_series)):
Genre_dataframe.loc[i,Genre_series[i]]=1
print(Genre_dataframe.sum(axis=0))
print(type(Genre_dataframe.sum(axis=0)))###Series对象
Genre_count=Genre_dataframe.sum(axis=0)
print(Genre_count)
###排序
Genre_count=Genre_count.sort_values()
##获取索引
_x=Genre_count.index
##获取值
_y=Genre_count.values
plt.barh(_x,_y)
plt.show()
代码2
import pandas as pd
import numpy as np
path='IMDB-Movie-Data.csv'
movie_data=pd.read_csv(path)
pd.set_option('display.max_columns',None)
print(movie_data.head(1))
#获取分类的列表
Genre_series=movie_data["Genre"].str.split(',').tolist()
Genre_list=list(set([j for i in Genre_series for j in i ]))
#构建全0数组
Genre_dataframe=pd.DataFrame(np.zeros((movie_data.shape[0],len(Genre_list))),columns=Genre_list)
###对每列进行迭代 #给每个电影出现分类的位置赋值1
for i in Genre_list:
Genre_dataframe[i][movie_data["Genre"].str.contains(i)]=1
print(Genre_dataframe.sum(axis=0))
print(type(Genre_dataframe.sum(axis=0)))###Series对象
Genre_count=Genre_dataframe.sum(axis=0)
print(Genre_count)
Genre_count=Genre_count.sort_values()
_x=Genre_count.index
_y=Genre_count.values
plt.barh(_x,_y)
plt.show()
5、操作案例3
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?文章来源:https://www.toymoban.com/news/detail-720364.html
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
path='starbucks_store_worldwide.csv'
sbk_data=pd.read_csv(path)
pd.set_option('display.max_columns',None)
print(sbk_data.head(1))
print(sbk_data.info())
###根据国家分组,获得分组对象
sbk_groupby=sbk_data.groupby(by='Country')
###统计国家数量,为series类型
sbk_groupby_cnt=sbk_groupby['Brand'].count()
###展示数量前10国家的条形图
sbk_groupby_cnt_top10=sbk_groupby_cnt.sort_values()[:10]
plt.barh(sbk_groupby_cnt_top10.index,sbk_groupby_cnt_top10.values,color='orange')
plt.show()
###限制为中国,按省份分组
sbk_groupby_cn=sbk_data[sbk_data['Country']=='CN'].groupby(by='State/Province')
sbk_groupby_cnt_cn=sbk_groupby_cn['Brand'].count()
##中国城市的数量情况条形图
sbk_groupby_cn=sbk_data[sbk_data['Country']=='CN'].groupby(by='City')
sbk_groupby_cnt_cn=sbk_groupby_cn['Brand'].count().sort_values(ascending=False)[:25]
plt.figure(figsize=(20,12),dpi=80)
plt.barh(range(len(sbk_groupby_cnt_cn)),sbk_groupby_cnt_cn.values,color='orange')
myfont=font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
plt.yticks(range(len(sbk_groupby_cnt_cn)),sbk_groupby_cnt_cn.index,fontproperties=myfont)
plt.show()
##按多分类进行分组,返回有多层索引的series
grouped = sbk_data["Brand"].groupby(by=[sbk_data["Country"],sbk_data["State/Province"]]).count()
##按多分类进行分组,返回有多层索引的dataframe
grouped1 = sbk_data[["Brand"]].groupby(by=[sbk_data["Country"],sbk_data["State/Province"]]).count()


5、操作案例4
现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
不同年份书的数量
不同年份书的平均评分情况文章来源地址https://www.toymoban.com/news/detail-720364.html
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
path='books.csv'
df=pd.read_csv(path)
pd.set_option('display.max_columns',None)
print(df.head(5))
print(df.info())
###筛选年份非空的记录
#df=df[df['original_publication_year'].notnull()]
df = df[pd.notnull(df["original_publication_year"])]
###不同年份书的数量
print(df['id'].groupby(by=df['original_publication_year']).count())
#不同年份书的平均评分情况
print(df['average_rating'].groupby(by=df['original_publication_year']).mean())
到了这里,关于16、python中dataframe的合并行/列、分组与聚合、行索引的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!









