一、模板虚拟机环境准备
使用VMware虚拟机搭建基于CentOS7的Hadoop环境:
- cpu核数(需要搭建3台Hadoop组成集群,加上Windows本机,所以可以分配的数量为本机的cpu核数除以4)
- 内存至少4G
- 硬盘最少50G
1. 创建虚拟机
创建虚拟机:
- 新建虚拟机,选择自定义(高级)—>硬件兼容性默认—>选择稍后安装操作系统 —>客户机操作系统选择 Linux、CentOS7 64位
- 配置虚拟机名称、存储位置
- 处理器数量2,每个处理器内核数2(本机总共有8核,16个逻辑处理器)—>配置虚拟机内存4G
- 网络类型默认的NAT—>IO类型、磁盘类型默认
- 选择创建新虚拟磁盘—>磁盘容量设置为50G,默认将虚拟磁盘拆分成多个文件不用变—>- 创建的磁盘文件配置到指定目录
- 完成
安装CentOS7系统:
- 配置CD/DVD使用的iso文件指向下载好的 CentOS 7系统镜像
- 启动虚拟机—>选择安装CentOS7 虚拟机
- 自动进入图形界面安装—>选择中文(安装过程中使用的语言,不代表操作系统的语言),继续—>修改时区、日期和时间—>软件选择可以选择最小安装或者GNOME桌面安装,本次选择桌面版
- 选择安装位置,我要分配分区进行手动分区,大小可以参考以下配置: /boot:1g(如果是最小化安装,/boot只有150多Mb),文件系统配置为 ext4 swap分区:4g
/:剩余空间分给根分区,文件系统默认xfr就行- 自己实验用的虚拟机,KDUMP可以禁用kdump以节省资源。(kdump是系统崩溃前捕获系统信息,用于诊断崩溃原因,但是需要预留一部分系统内存)
- 网络和主机名称配置主机名称、网络,主机名设置为hadoop100—>SECURITY POLICY安全策略默认打开即可
- 点击安装—>安装的过程中可以配置root密码—>等安装完成,点击重启—>重启进来之后,点开许可协议,选择我同意许可协议—>点击完成配置
- 选择中文、汉语、打开位置、选择上海时区、跳过在线账号—>创建一个普通用户
- 完成
详细步骤可点击—>尚硅谷大数据Hadoop教程
2. 配置网络静态IP
-
配置hostname,检查
vim /etc/hostname中的主机名配置信息,例如将主机名配置为hadoop100(后面的几台集群中主机为hadoop101、hadoop102、hadoop103组成集群) -
配置IP为静态IP,
vim /etc/sysconfig/network-scripts/ifcfg-ens33进入配置文件,修改内容为:
# 将DHCP动态获取修改为static静态IP,其他保持默认
BOOTPROTO="static"
# 然后添加以下配置(根据虚拟机实际情况进行配置)
# ip地址
IPADDR=192.168.103.100
# 网关(可以在VMware虚拟网络编辑器的NAT模式中 NAT设置里面查找到)
GATEWAY=192.168.103.2
# 域名解析器
DNS1=192.168.103.2
3. 配置host映射文件
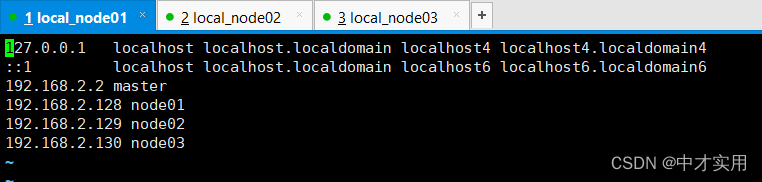
- 配置hosts映射,,将集群中的主机添加进来,
vim /etc/hosts进入配置文件添加如下内容:
192.168.103.100 hadoop100
192.168.103.101 hadoop101
192.168.103.102 hadoop102
192.168.103.103 hadoop103
192.168.103.104 hadoop104
- 在Windows系统中,也将Hosts映射加入进来,进入
C:\Windows\System32\drivers\etc\hosts文件增加同样的内容。 - 配置好网络,使用
reboot重启使其生效 - 重新进来后,使用
ifconfig判断网络配置是否生效,ping一个外部网站查看是否可以连网
4. 安装epel-release
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository中是找不到的。
安装命令
yum install -y epel-release
如果Linux安装的是最小系统板,还需要安装net-tool、vim等常用工具:
# 安装ifconfig命令
yum install -y net-tools
# 安装vim编辑器
yum install -y vim
5. 关闭防火墙及防火墙的开机自启
# 关闭防火墙
systemctl stop firewalld
# 关闭防火墙的开机自启
systemctl disable firewalld.service
6. 用户添加root权限
如果安装的桌面版,在安装过程就会让创建一个非root用户。
如果安装的最小系统版,则可以手工执行命令创建一个非root用户:
useradd huahua
passwd huahua
将该用户加入sudoers中,方便后续添加sudo执行命令。
编辑/etc/sudoers文件(该文件默认只读,需要先添加写权限),在%wheel用户执行命令权限下面添加一行:
%wheel ALL=(ALL) ALL
# 在%wheel下面添加,不要直接加载 root下面。因为所有用户都属于wheel组,如果放到了root下面(%wheel上面),那么执行了NOPASSWD:ALL免密之后,程序走到%wheel时就又会被覆盖回需要密码
huahua ALL=(ALL) NOPASSWD:ALL
7. 创建文件夹
在/opt下创建文件夹module、software:
mkdir /opt/module
mkdir /opt/software 修改 module、software 文件夹的所有者和所属组
chown huahua:huahua /opt/module
chown huahua:huahua /opt/software
8. 卸载虚拟机自带的JDK
注意:如果虚拟机是最小化安装不需要执行这一步。
检查系统中自带的JDK:
rpm -qa | grep -i java
卸载自带的JDK(需要以root用户运行):
rpm -qa | grep -i java | grep -v ".noarch" | xargs -n1 rpm -e --nodeps
- grep -i 忽略大小写
- xargs 将前面的输出结果作为命令的参数
- -n1 每次只取一个结果作为命令参数。如果不加,则会将所有结果以空格分隔拼接作为命令的参数
- rpm -e --nodeps 不验证套件档的相互关联性进行卸载
9. 重启虚拟机
# 重启虚拟机
reboot
二、克隆虚拟机
- 因为我们要搭建集群,所以需要再克隆出几台虚拟机出来。
- 将hadoop100虚拟机关机,然后创建完整克隆。克隆出 hadoop102、hadoop103、hadoop104几台主机。(hadop101用于后面搭建伪分布式,分析源码,本次先不搭建进集群中)。
- 克隆完成之后,还需要依次修改 hadoop102、hadoop103、hadoop104的ip和hostname。
1. 修改克隆机IP
- 修改克隆虚拟机的静态IP(以hadoop102为例)
vim /etc/sysconfig/network-scripts/ifcfg-ens33进入配置文件,修改
BOOTPROTO=static
···
IPADDR=192.168.103.102
GATEWAY=192.168.103.2
DNS1=192.168.103.2
- 查看 Linux 虚拟机的虚拟网络编辑器,编辑—>虚拟网络编辑器—>VMnet8
- 查看 Windows 系统适配器 VMware Network Adapter VMnet8 的 IP 地址
- 保证 Linux 系统 ifcfg-ens33 文件中 IP 地址、虚拟网络编辑器地址和 Windows 系统 VM8 网络 IP 地址相同
2. 修改克隆机主机名
- 修改主机名称(以hadoop102为例),
vim /etc/hostname进入配置文件,主机名改为hadoop102 - 配置 Linux 克隆机主机名称映射 hosts 文件,
vim /etc/hosts打开/etc/hosts
添加如下内容:
192.168.103.100 hadoop100
192.168.103.101 hadoop101
192.168.103.102 hadoop102
192.168.103.103 hadoop103
192.168.103.104 hadoop104
- 配置好网络,使用
reboot重启使其生效 - 在Windows系统中,也将Hosts映射加入进来,进入
C:\Windows\System32\drivers\etc\hosts文件增加同样的内容。
三、环境搭建
JDK、Hadoop都先在 hadoop102 服务器上安装,安装好之后再 scp 复制到其他服务器。文章来源:https://www.toymoban.com/news/detail-720638.html
1. 安装JDK
- 将 jdk1.8 压缩包上传到创建的
/opt/software文件夹中。 - 将 jdk 解压到创建的
/opt/module/文件夹中:
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /opt/module/
- 配置环境变量,可以直接在
/etc/profile.d文件夹中创建一个.sh后缀的文件,/etc/profile会遍历该文件夹下的所有.sh文件的内容作为环境变量。
在/etc/profile.d下创建my_env.sh:
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_361
export PATH=$PATH:$JAVA_HOME/bin
- 重新加载环境变量:
source /etc/profile
- 测试 JDK 是否安装成功
java -version
# 如果能看到以下结果,则代表 Java 安装成功
java version "1.8.0_361"
2. 安装Hadoop
- 从官网(或国内镜像站)下载Hadoop 3.x安装包。
- 将安装包上传到创建的
/opt/software文件夹中 - 解压:
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/module/
- 配置环境变量(hadoop需要配置 /bin和 /sbin两个目录到环境变量)。
同样的,我们在/etc/profile.d/my_env.sh中进行添加:
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 刷新环境变量,查询Hadoop版本进行验证:
# 刷新环境变量
source /etc/profile
# 验证
hadoop version
Hadoop重要目录文章来源地址https://www.toymoban.com/news/detail-720638.html
- bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
到了这里,关于【大数据】Hadoop运行环境搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!