1.什么是时状态(state)?
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。 例如以下状态都需要使用流处理的状态功能:
数据流中的数据有重复,想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
在Flink任务中,Flink的一个算子有多个子任务,每个子任务分布在不同实例上,可以把状态理解为某个算子子任务在其当前实例上的一个变量,变量记录了数据流的历史信息。当新数据流入时,可以结合历史信息来进行计算。实际上,Flink的状态是由算子的子任务来创建和管理的。一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。
对于获取和更新状态数据的逻辑不复杂,但是对于流处理框架还需要解决以下问题:
数据的产出要保证实时性,延迟不能太高。
需保证数据的不重不丢,恰好计算一次,尤其是当状态数据非常大或者应用出现故障需要恢复时,要保证状态的计算不出任何错误。
一般流处理任务都是全天运行的,程序的可靠性非常高。
基于上述要求, 不能将状态直接交由内存管理,因为内存的容量是有限制的,当状态数据稍微大一些时,就会出现OOM问题。 作为一个计算框架,Flink提供了有状态的计算,封装了一些底层的实现,比如状态的高效存储、Checkpoint和Savepoint持久化备份机制、计算资源扩缩容等问题。因为Flink接管了这些问题,开发者只需调用Flink API,这样可以更加专注于业务逻辑。
总而言之,Flink中的状态:
由一个任务维护,并且用来计算某个结果的所有数据,就属于这个任务的状态。
状态可以理解为一个本地变量,可以被任何业务逻辑访问。
当任务失败时,可以使用状态恢复数据。
状态始终与特定的算子相关联。
算子需要预先注册其状态,以便Flink在运行时能够了解算子状态。
2.状态描述(StateDescriptor)
StateDescriptor 是所有状态描述符的基类。 Flink 通过 StateDescriptor 定义状态,包括状态的名称,存储数据的类型,序列化器等基础信息。

Flink 中提供了 ListStateDescriptor、MapStateDescriptor、ValueStateDescriptor、AggregatingStateDescriptor、ReducingStateDescriptor 、FoldingStateDescriptor(废弃) 状态描述符供使用。
2.Flink状态分类
2.1 托管状态和原始状态
Flink的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,作为开发人员只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要开发人员管理,实现状态的序列化和故障恢复。
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime托管,自动存储、自动恢复、自动伸缩 | 用户管理 |
| 状态数据结构 | Flink提供常见的数据结构,如ValueState、ListValue、MapState等 | 字节数据组:byte[] |
| 应用场景 | 绝大多数Flink算子(通过继承Rich函数或者其他提供的接口类) | 用户自定义算子 |
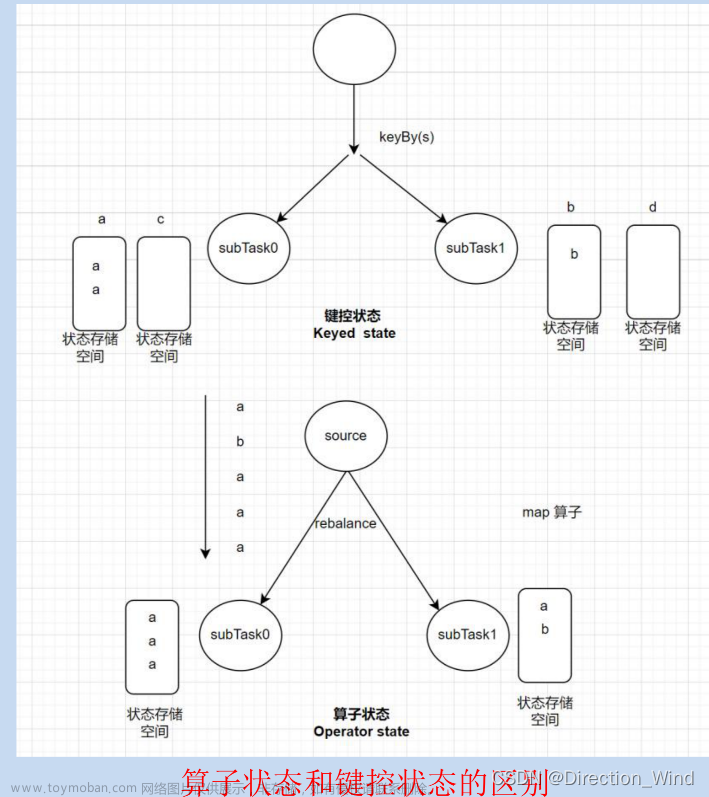
2.2 Keyed State和Operator State
在Flink任务中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。而很多有状态的操作(比如聚合、窗口)都是要先做keyBy进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前key有效,所以状态也应该按照key彼此隔离。在这种情况下,状态的访问方式又会有所不同。基于上述情况,托管状态可分为两类:算子状态和按键分区状态。
2.2.1 算子状态(Operator State)概述
状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。对于一个并行子任务,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的,如图所示:
算子状态可以用在所有算子上,使用时其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。在使用时,还需进一步实现CheckpointedFunction接口。
2.2.2 按键分区状态(Keyed State)概述
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以key为作用范围进行隔离。在进行按键分区(keyBy)之后,具有相同键的所有数据,都会分配到同一个并行子任务中;所以如果当前任务定义了状态,Flink就会在当前并行子任务实例中,为每个键值维护一个状态的实例。
一个并行子任务可能会处理多个key的数据,在底层,Keyed State类似于一个分布式的映射(map)数据结构,所有的状态会根据key保存成键值对(key-value)的形式。
当一条数据到来时,任务就会自动将状态的访问范围限定为当前数据的key,从map存储中读取出对应的状态值。所以具有相同key的所有数据都会到访问相同的状态,而不同key的状态之间是彼此隔离的。这种将状态绑定到key上的方式,相当于使得状态和流的逻辑分区一一对应了,不会有别的key的数据来访问当前状态;而当前状态对应key的数据也只会访问这一个状态,不会分发到其他分区去。这就保证了对状态的操作都是本地进行的,对数据流和状态的处理做到了分区一致性。
Keyed State是KeyedStream上的状态。 状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就keyBy之后才可以使用,如图所示:
2.2.3 Keyed State 与 Operator State比较
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
| Operator State | Keyed State | |
|---|---|---|
| 适用算子类型 | 可以适用所有算子 | 只适用于KeyedStream上的算子 |
| 状态分配 | 一个算子子任务对应一个状态 | 每个Key对应一个状态 |
| 创建和访问方式 | 实现CheckpointedFunction等借口 | 重写Rich Function,通过里面的RuntimeContext访问 |
| 横向扩展 | 有多种状态重新分配的方式 | 状态随着Key自动在多个算子子任务上迁移 |
| 支持数据结构 | ListState、BroadcastState等 | ValueState、ListValue、MapState等 |
current key OperatorState没有current key的概念,KeyedState的数值总是与一个current key对应。
snapshot OperatorState 需要手动实现snapshot和restore方法,KeyedState由backend实现,对用户透明。
heap OperatorState 只有堆内存一种实现,KeyedState由有堆内存和RocksDB两种实现。
Size OperatorState 一般被认为是规模比较小的,KeyedState一般是相对规模较大的。
2.2.4 状态的使用
在 Flink 中,状态始终是与特定算子相关联的;算子在使用状态前首先需要“注册”,其实就是告知Flink当前上下文中定义状态的信息,这样运行时的Flink才能知道算子有哪些状态。
状态的注册,主要是通过“状态描述器”(StateDescriptor)来实现的。状态描述器中最重要的内容,就是状态的名称(name)和类型(type。状态描述器中还可能需要传入一个用户自定义函数(user-defined-function,UDF),用来说明处理逻辑,比如ReduceFunction和AggregateFunction。
2.3 按键分区状态(Keyed State)

值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。
源码如下:
//接口 T表示泛型,value表示可以是任何具体的数据类型。public interface ValueState<T> extends State { T value() throws IOException; //获取当前状态的值 void update(T value) throws IOException;//更新当前状态的值(value即为新的值)}在使用时,为了让运行时上下文清楚到底是哪个状态,需要创建一个"状态描述器"提供基本信息(StateDescriptor)
映射状态(MapState)
以键值对(key-value)的形式将状态整体保存起来
对应的MapState<UK, UV>接口中,UK、UV是泛型,分别表示保存的key和value的类型。
MapState提供了操作映射状态的方法,与Map的使用非常类似。
列表状态(ListState)
将状态数据以列表(List)的形式组织起来。
ListState提供操作状态的方法,使用方式与一般的List非常相似。
归约状态(ReducingState)
需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。
归约逻辑的定义,是在归约状态描述器(ReducingStateDescriptor)中,通过传入一个归约函数(ReduceFunction)来实现的。
聚合状态(AggregatingState)
聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。
聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的,里面通过一个累加器(Accumulator)来表示状态
2.4 算子状态(Operator State)

列表状态(ListState)
与Keyed State中的ListState一样,将状态表示为一组数据的列表。
与Keyed State中列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”,也就是当前并行子任务上所有状态项的集合。
列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),通过逐一“发牌”的方式将状态项平均分配的。
联合列表状态(UnionState)
与ListState类似,联合列表状态将将状态表示为一个列表。
与ListState的区别在于算子并行度进行缩放调整时对于状态的分配方式不同。
在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。
广播状态(BroadcastState)
一种特殊算子状态,所有分区的所有数据都会访问到同一个状态,如同状态被广播到所有分区。
在并行度调整时,只要复制一份到新的并行任务就可以实现扩展。
3.总结
Flink状态:
Flink中的状态是用来保存中间结果或者一些缓存数据,由一个任务维护。
Flink中的状态可类比为本地变量,可以被任何业务逻辑访问。
当Flink任务失败时,可以使用状态恢复数据,状态始终与特定的算子相关联。
算子需要预先注册其状态,以便于Flink在运行时能够了解算子状态。
Flink状态分类:托管状态和原始状态
托管状态由Flink统一管理,原始状态由用户管理。
托管状态分为:算子状态(OperatorState)和按键分区状态(KeyedState)。
Flink中的托管状态(Manage)
current key OperatorState没有current key的概念,KeyedState的数值总是与一个current key对应。
snapshot OperatorState 需要手动实现snapshot和restore方法,KeyedState由backend实现,对用户透明。
heap OperatorState 只有堆内存一种实现,KeyedState由有堆内存和RocksDB两种实现。
Size OperatorState 一般被认为是规模比较小的,KeyedState一般是相对规模较大的。
算子状态(OperatorState)与按键分区状态(KeyedState)的区别:
算子状态分为:列表状态(ListState)、广播状态(BroadcastState)、联合列表状态(UnionState)。
按键分区状态分为: 值状态(ValueState)、列表状态(ListState)、映射状态MapState)、文章来源:https://www.toymoban.com/news/detail-720840.html
归约状态(ReducingState)、聚合状态(AggregatingState)。文章来源地址https://www.toymoban.com/news/detail-720840.html
到了这里,关于Flink状态详解:什么是时状态(state)?状态描述(StateDescriptor)及其重要性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!