首先这篇文章是转载的,但是我看懂了,经过修改成功了!!
PS上一节课:请查看【爬虫专栏】
本文所需的库(其余为内置库):
| 库 | 安装 |
|---|---|
| js2py | pip install js2py |
| requests | pip install requests |
我依照原帖的思路讲一下:
第 1 步,进入百度翻译网页版:点我
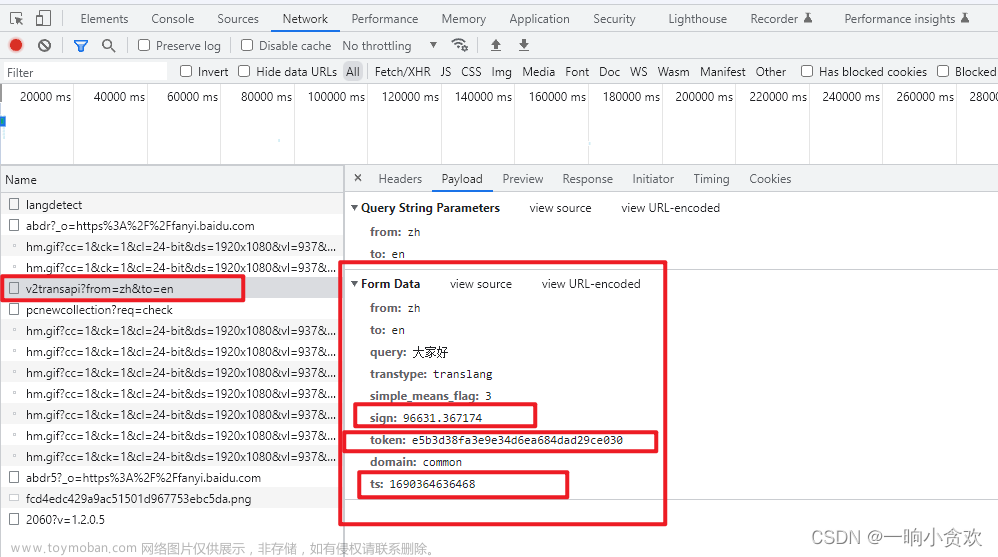
第 2 步 分析所需参数
这里我们发现所需的参数:
1、sign(这是最重要的!!)
2、token
3、ts,时间戳
第 3 步 分析sign 加密代码,这里我就直接展示出来了
请将该文件命名【webtrans.js】
// webtrans.js
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
,
// l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
i = null;
u = null !== i ? i : (i = window[l] || "") || "";
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
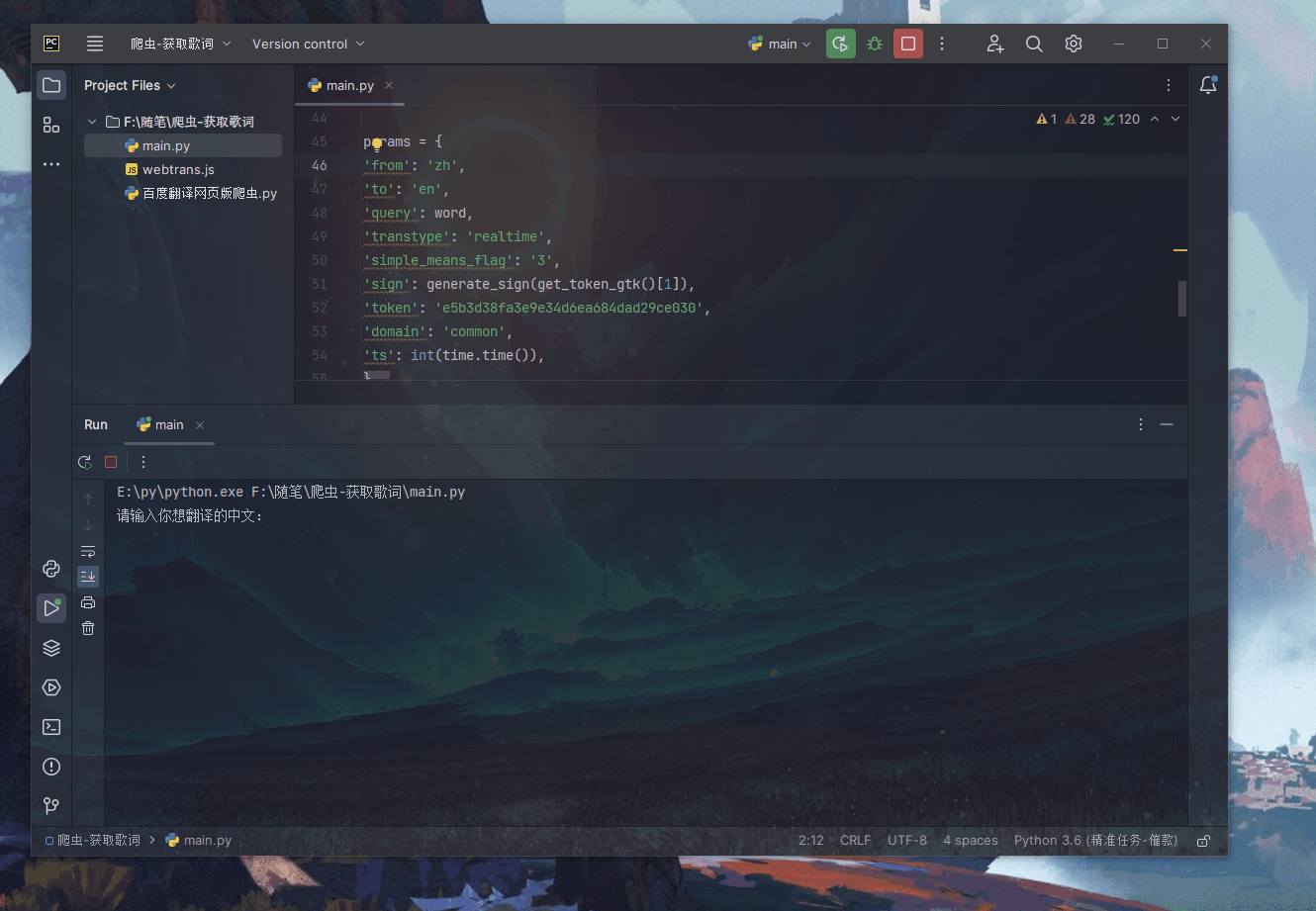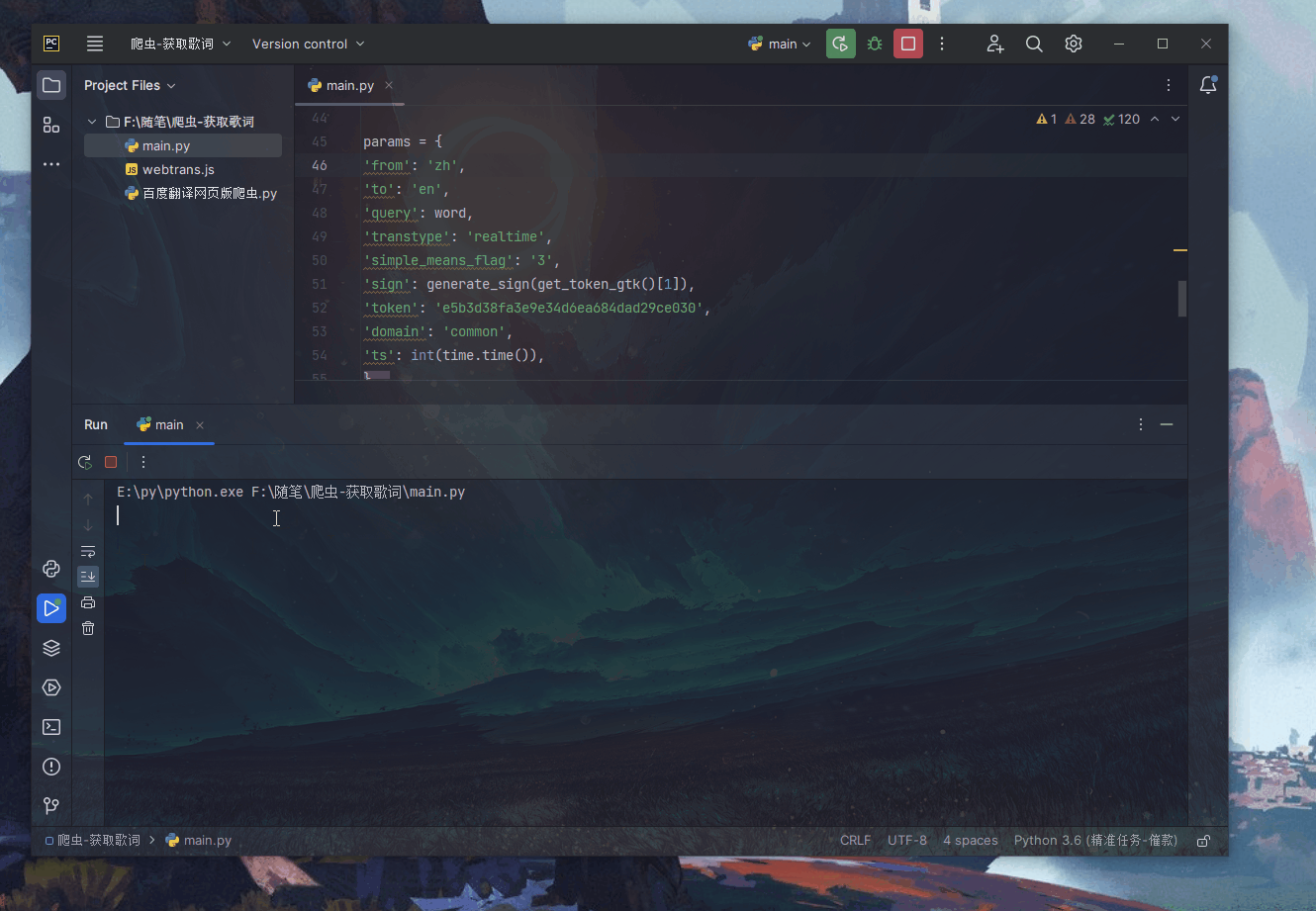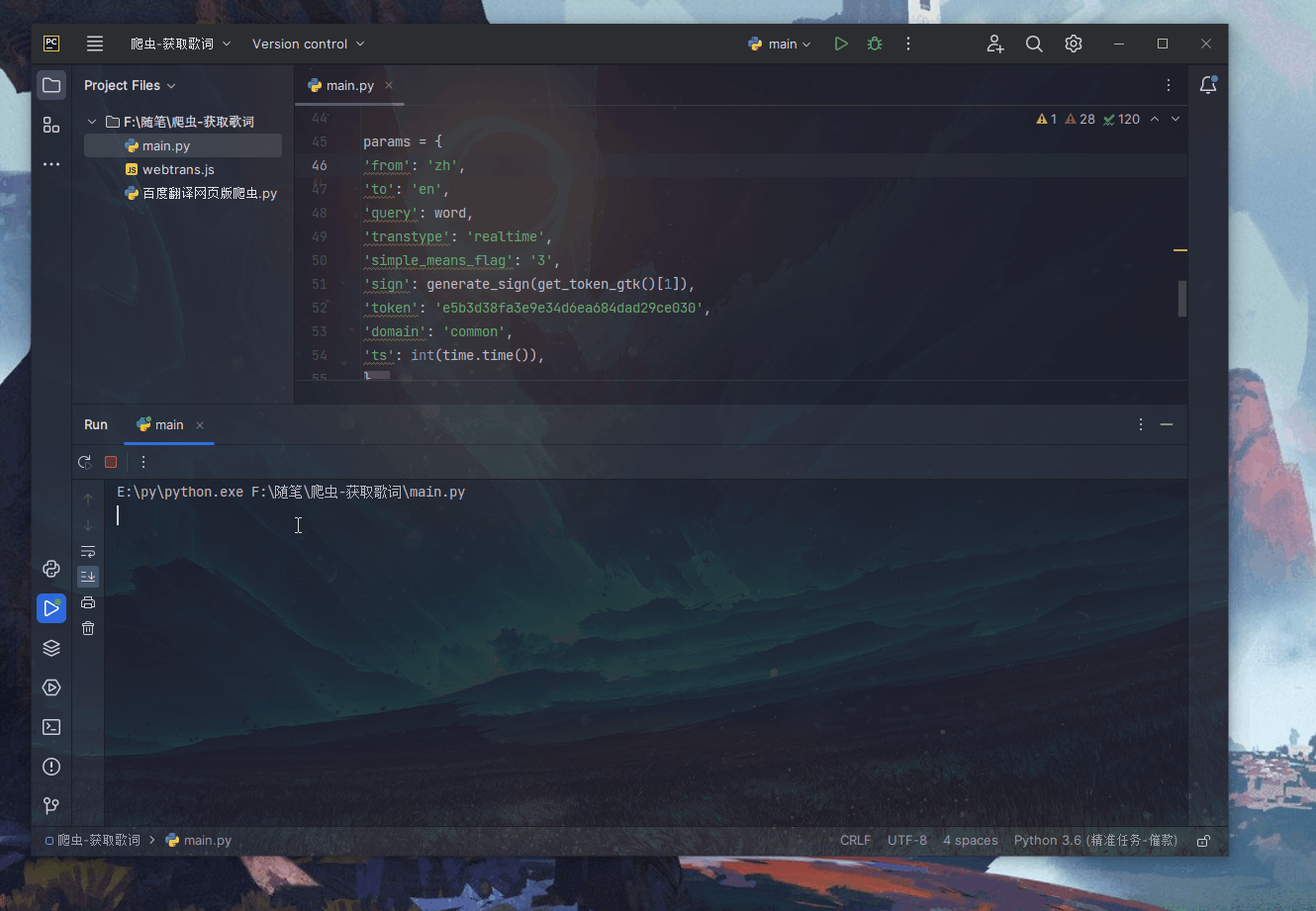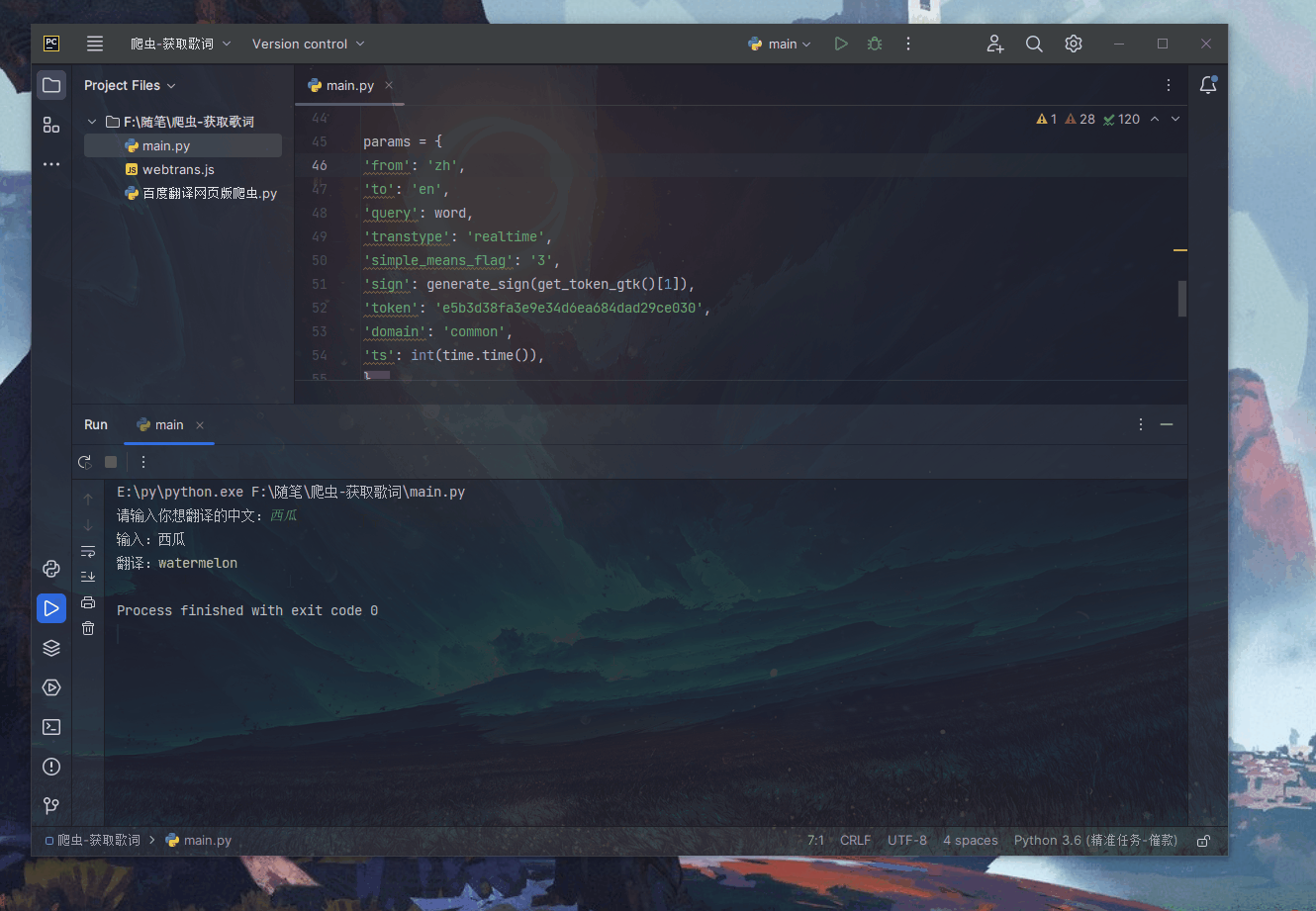
第 4 步:
在调用上述js函数前,需要获取网页中的【window.bdstoken】以及【window.gtk】,如下图
只有拿到这两个才能生成 sign
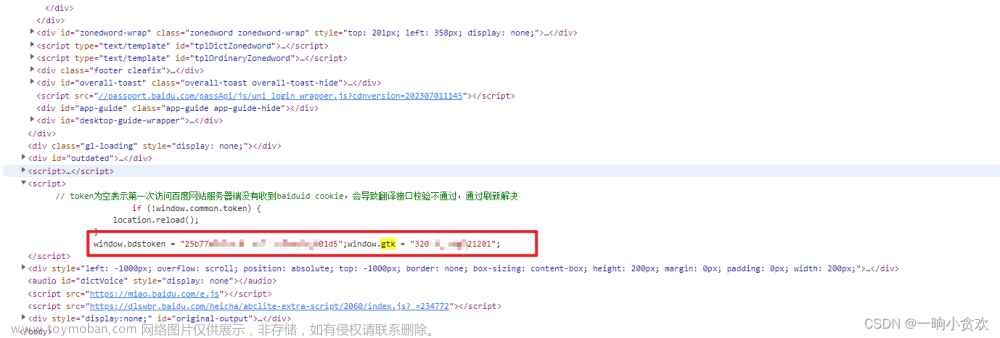 文章来源:https://www.toymoban.com/news/detail-720889.html
文章来源:https://www.toymoban.com/news/detail-720889.html
第 5 步
通过【js2py】库 调用刚刚保存的 【webtrans.js】,获取最终的 【sign】
目录结构
 文章来源地址https://www.toymoban.com/news/detail-720889.html
文章来源地址https://www.toymoban.com/news/detail-720889.html
附上完整版代码1(自己的改写版,后面还附赠进阶版(面向对象))
注意事项(必看)
代码17行:token = ‘请您写上自己的token’
代码52行:token = ‘请您写上自己的token’
代码60行:cookies = {‘Cookie’: ‘请您写上自己的cookie’}
import json
import re
import time
import requests
import js2py
def get_token_gtk():
'''获取token和gtk(用于合成Sign)'''
url = 'https://fanyi.baidu.com/'
resp = requests.get(url)
html_str = resp.content.decode()
# print(html_str)
# token = re.findall(r"token: '(.*?)'", html_str)[0]
token = '请您写上自己的token'
# print('token: ',token)
pattern = r'gtk = "(.*?)\"'
gtk = re.search(pattern, html_str).group(1)
# print('gtk: ',gtk)
# gtk = re.match(r".gtk = '(.*?)'", html_str)
# print(token, gtk)
return token, gtk
# get_token_gtk()
word = input("请输入你想翻译的中文:")
def generate_sign(gtk):
"""生成sign"""
# 1. 准备js编译环境
context = js2py.EvalJs()
with open('webtrans.js', encoding='utf8') as f:
js_data = f.read()
js_data = re.sub("window\[l\]",'"'+gtk+'"',js_data)
# js_data = re.sub("window\[l\]", "\"{}\"".format(gtk), js_data)
# print(js_data)
context.execute(js_data)
sign = context.e(word)
return sign
# print(generate_sign(get_token_gtk()[1]))
params = {
'from': 'zh',
'to': 'en',
'query': word,
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': generate_sign(get_token_gtk()[1]),
'token': '请您写上自己的token',
'domain': 'common',
'ts': int(time.time()),
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
cookies = {
'Cookie': '请您写上自己的cookie'
}
url2 = 'https://fanyi.baidu.com/v2transapi?from=zh&to=en'
res_data = requests.post(url=url2,params=params,headers=headers,cookies=cookies)
res_data.encoding= "utf-8"
data = json.loads(res_data.text)
# print(data)
print(f"输入:{data['trans_result']['data'][0]['src']}")
print(f"翻译:{data['trans_result']['data'][0]['dst']}")
完整版2(面向对象版)
# 面向对象
# 百度翻译 -- 网页版(自动获取token,sign)
import requests
import js2py
import json
import re
class WebFanyi:
"""百度翻译网页版爬虫"""
def __init__(self,query_str):
self.session = requests.session()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
}
self.session.headers = headers
self.baidu_url = "https://www.baidu.com/"
self.root_url = "https://fanyi.baidu.com/"
self.lang_url = "https://fanyi.baidu.com/langdetect"
self.trans_url = "https://fanyi.baidu.com/v2transapi"
self.query_str = query_str
def get_token_gtk(self):
'''获取token和gtk(用于合成Sign)'''
self.session.get(self.root_url)
resp = self.session.get(self.root_url)
html_str = resp.content.decode()
# print(html_str)
token = re.findall(r"token: '(.*?)'", html_str)[0]
# print(token)
pattern = r'gtk = "(.*?)\"'
gtk = re.search(pattern, html_str).group(1)
# print(gtk)
# gtk = re.match(r".gtk = '(.*?)'", html_str)
return token,gtk
def generate_sign(self,gtk):
"""生成sign"""
# 1. 准备js编译环境
context = js2py.EvalJs()
with open('webtrans.js', encoding='utf8') as f:
js_data = f.read()
js_data = re.sub("window\[l\]",'"'+gtk+'"',js_data)
# js_data = re.sub("window\[l\]", "\"{}\"".format(gtk), js_data)
print(js_data)
context.execute(js_data)
sign = context.e(self.query_str)
return sign
def lang_detect(self):
'''获取语言转换类型.eg: zh-->en'''
lang_resp = self.session.post(self.lang_url,data={"query":self.query_str})
lang_json_str = lang_resp.content.decode() # {"error":0,"msg":"success","lan":"zh"}
lan = json.loads(lang_json_str)['lan']
to = "en" if lan == "zh" else "zh"
return lan,to
def parse_url(self,post_data):
trans_resp = self.session.post(self.trans_url,data=post_data)
trans_json_str = trans_resp.content.decode()
trans_json = json.loads(trans_json_str)
result = trans_json["trans_result"]["data"][0]["dst"]
print("{}: {}".format(self.query_str,result))
def run(self):
"""实现逻辑"""
# 1.获取百度的cookie,(缺乏百度首页的cookie会始终报错998)
self.session.get(self.baidu_url)
# 2. 获取百度翻译的token和gtk(用于合成sign)
token, gtk = self.get_token_gtk()
# 3. 生成sign
sign = self.generate_sign(gtk)
# 4. 获取语言转换类型.eg: zh-->en
lan, to = self.lang_detect()
# 5. 发送请求,获取响应,输出结果
post_data = {
"from": lan,
"to": to,
"query": self.query_str,
"transtype": "realtime",
"simple_means_flag": 3,
"sign": sign,
"token": token
}
self.parse_url(post_data)
if __name__ == '__main__':
webfanyi = WebFanyi('西瓜')
webfanyi.run()
原帖查看
希望对大家有帮助
我也正在努力学习爬虫,大家共同进步!!
都看到这了,关注+点赞+收藏=不迷路!!
到了这里,关于Python爬虫实战(高级篇)—3百度翻译网页版爬虫(附完整代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!