0. Prerequisite
There are 3 VMs - hadoop3/hadoop4/hadoop5 for fully-distributed HBase cluster, the setup plan looks like:
| hadoop3 | hadoop4 | hadoop5 | |
| Hadoop hdfs | NameNode:8020 DateNode:50010 JobHistoryServer:19888 |
DataNode:50010 | SecondaryNameNode:50090 DateNode:50010 |
| Hadoop yarn | NodeManger:8040 | ResourceMananger:8088 NodeManger:8040 |
NodeManger:8040 |
| Zookeeper | QuorumPeerMain:2181 | QuorumPeerMain:2181 | QuorumPeerMain:2181 |
| HBase | HMaster:16000 HRegionServer:16020 |
HRegionServer:16020 | HRegionServer:16020 |
And JDK/Zookeeper/Hadoop/HBase have been installed under /opt on 3 VMs with user sunxo:
$ ls /opt
hadoop-2.10.2 hbase-2.4.16 jdk zookeeper-3.8.11) configure passwordless SSH access
hadoop3 who has Namenode needs to access all VMs as sunxo
$ ssh-keygen -t rsa
$ ssh-copy-id hadoop3
$ ssh-copy-id hadoop4
$ ssh-copy-id hadoop5and root as well
# ssh-keygen -t rsa
# ssh-copy-id hadoop3
# ssh-copy-id hadoop4
# ssh-copy-id hadoop5
haddoop4 who has ResourceMananger needs to access all VMs as sunxo
$ ssh-keygen -t rsa
$ ssh-copy-id hadoop3
$ ssh-copy-id hadoop4
$ ssh-copy-id hadoop5
2) hadoop3 add environment variable in $HOME/.bashrc (not .bash.profile)
export JAVA_HOME=/opt/jdk
export ZOOKEEPER_HOME=/opt/zookeeper-3.8.1
export KAFKA_HOME=/opt/kafka-3.3.1
export HADOOP_HOME=/opt/hadoop-2.10.2
export HBASE_HOME=/opt/hbase-2.4.16
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$JAVA_HOME/bin:$HOME/bin:.:$PATHAnd distribute .bashrc to hadoop4 hadoop5
$ rsync.sh .bashrc hadoop4 hadoop5
rsync -rvl /home/sunxo/.bashrc sunxo@hadoop4:/home/sunxo
sending incremental file list
.bashrc
sent 614 bytes received 37 bytes 1302.00 bytes/sec
total size is 541 speedup is 0.83
rsync -rvl /home/sunxo/.bashrc sunxo@hadoop5:/home/sunxo
sending incremental file list
.bashrc1. Zookeeper on hadoop3
1) configurate and distribute zoo.cfg
$ cd $ZOOKEEPER_HOME/conf
$ diff -u zoo_sample.cfg zoo.cfg
--- zoo_sample.cfg 2023-01-26 00:31:05.000000000 +0800
+++ zoo.cfg 2023-10-17 14:30:06.598229298 +0800
@@ -9,7 +9,7 @@
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
-dataDir=/tmp/zookeeper
+dataDir=/opt/zookeeper-3.8.1/tmp
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
@@ -25,7 +25,7 @@
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
-#autopurge.purgeInterval=1
+autopurge.purgeInterval=1
## Metrics Providers
#
@@ -35,3 +35,7 @@
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
+# cluster
+server.3=hadoop3:2888:3888
+server.4=hadoop4:2888:3888
+server.5=hadoop5:2888:3888
$ rsync.sh zoo.cfg hadoop4 hadoop52) create and distribute data dir assigned in zoo.cfg
cd $ZOOKEEPER_HOME
$ mkdir -p tmp
$ rsync.sh tmp hadoop4 hadoop53) start zookeeper cluster
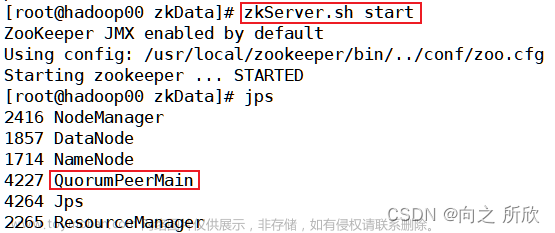
$ hosts="hadoop3 hadoop4 hadoop5"
$ for host in $hosts
> do
> echo "============= zk start on $host ============="
> ssh $host $ZOOKEEPER_HOME/bin/zkServer.sh start
> done
============= zk start on hadoop3 =============
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.1/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
============= zk start on hadoop4 =============
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.1/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
============= zk start on hadoop5 =============
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.8.1/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
$ jps.sh hadoop3 hadoop4 hadoop5
============= hadoop3 =============
30495 QuorumPeerMain
============= hadoop4 =============
313 QuorumPeerMain
============= hadoop5 =============
4264 QuorumPeerMain2. Hadoop on hadoop3
1) configurate
$ cd $HADOOP_HOME/etc/hadoop
$ diff -u hadoop-env.sh.orig hadoop-env.sh
...
-export JAVA_HOME=${JAVA_HOME}
+export JAVA_HOME=/opt/jdk
$ cat core-site.xml
...
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop3:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.10.2/data/tmp</value>
</property>
</configuration>
$ cat hdfs-site.xml
...
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop5:50090</value>
</property>
</configuration>
$ cat mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop3:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop3:19888</value>
</property>
</configuration>
$ cat yarn-site.xml
...
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop4</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
$ cat slaves
hadoop3
hadoop4
hadoop52) distribute configuration to hadoop4, hadoop5
$ cd $HADOOP_HOME/etc
$ rsync.sh hadoop/ hadoop4 hadoop53) format filesystem
$ cd $HADOOP_HOME
$ rm.sh data/ hadoop3 hadoop4 hadoop5 # remove old data if need
$ rm.sh log/ hadoop3 hadoop4 hadoop5 # remove old log if need
$ bin/hdfs namenode -format4) start hdfs/yarn/historyserver
$ echo "============= dfs start from hadoop3 ============="
ssh hadoop3 $HADOOP_HOME/sbin/start-dfs.sh
echo "============= yarn start from hadoop4 ============="
ssh hadoop4 $HADOOP_HOME/sbin/start-yarn.sh
echo "============= history start on hadoop3 ============="
ssh hadoop3 $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
============= dfs start from hadoop3 =============
Starting namenodes on [hadoop3]
hadoop3: starting namenode, logging to /opt/hadoop-2.10.2/logs/hadoop-sunxo-namenode-hadoop3.out
hadoop4: starting datanode, logging to /opt/hadoop-2.10.2/logs/hadoop-sunxo-datanode-hadoop4.out
hadoop3: starting datanode, logging to /opt/hadoop-2.10.2/logs/hadoop-sunxo-datanode-hadoop3.out
hadoop5: starting datanode, logging to /opt/hadoop-2.10.2/logs/hadoop-sunxo-datanode-hadoop5.out
Starting secondary namenodes [hadoop5]
============= yarn start from hadoop4 =============
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.10.2/logs/yarn-sunxo-resourcemanager-hadoop4.out
hadoop3: starting nodemanager, logging to /opt/hadoop-2.10.2/logs/yarn-sunxo-nodemanager-hadoop3.out
hadoop4: starting nodemanager, logging to /opt/hadoop-2.10.2/logs/yarn-sunxo-nodemanager-hadoop4.out
hadoop5: starting nodemanager, logging to /opt/hadoop-2.10.2/logs/yarn-sunxo-nodemanager-hadoop5.out
============= history start on hadoop3 =============
starting historyserver, logging to /opt/hadoop-2.10.2/logs/mapred-sunxo-historyserver-hadoop3.out
$ jps.sh hadoop3 hadoop4 hadoop5
============= hadoop3 =============
816 DataNode
616 NameNode
1385 JobHistoryServer
1166 NodeManager
30495 QuorumPeerMain
============= hadoop4 =============
2065 DataNode
2354 NodeManager
313 QuorumPeerMain
2222 ResourceManager
============= hadoop5 =============
5892 DataNode
6023 SecondaryNameNode
4264 QuorumPeerMain
6120 NodeManager3. HBase on hadoop3
1) configurate
$ diff -u hbase-env.sh.orig hbase-env.sh
--- hbase-env.sh.orig 2020-01-22 23:10:15.000000000 +0800
+++ hbase-env.sh 2023-10-19 18:21:33.098131203 +0800
@@ -25,7 +25,7 @@
# into the startup scripts (bin/hbase, etc.)
# The java implementation to use. Java 1.8+ required.
-# export JAVA_HOME=/usr/java/jdk1.8.0/
+export JAVA_HOME=/opt/jdk
# Extra Java CLASSPATH elements. Optional.
# export HBASE_CLASSPATH=
@@ -123,7 +123,7 @@
# export HBASE_SLAVE_SLEEP=0.1
# Tell HBase whether it should manage it's own instance of ZooKeeper or not.
-# export HBASE_MANAGES_ZK=true
+export HBASE_MANAGES_ZK=false
# The default log rolling policy is RFA, where the log file is rolled as per the size defined for the
$ cat hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop3,hadoop4,hadoop5</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop3:8020/hbase</value>
</property>
</configuration>
$ cat regionservers
hadoop3
hadoop4
hadoop52) start hbase
$ echo "============= hbase start from hadoop3 ============="
$HBASE_HOME/bin/start-hbase.sh
============= hbase start from hadoop3 =============
running master, logging to /opt/hbase-2.4.16/logs/hbase-sunxo-master-hadoop3.out
hadoop3: running regionserver, logging to /opt/hbase-2.4.16/logs/hbase-sunxo-regionserver-hadoop3.out
hadoop4: running regionserver, logging to /opt/hbase-2.4.16/logs/hbase-sunxo-regionserver-hadoop4.out
hadoop5: running regionserver, logging to /opt/hbase-2.4.16/logs/hbase-sunxo-regionserver-hadoop5.out
$ jps.sh hadoop3 hadoop4 hadoop5
============= hadoop3 =============
816 DataNode
2064 HMaster
616 NameNode
2280 HRegionServer
1385 JobHistoryServer
1166 NodeManager
30495 QuorumPeerMain
============= hadoop4 =============
2065 DataNode
2354 NodeManager
2995 HRegionServer
313 QuorumPeerMain
2222 ResourceManager
============= hadoop5 =============
5892 DataNode
6023 SecondaryNameNode
4264 QuorumPeerMain
6120 NodeManager
6616 HRegionServerNote: check related url
Hdfs - http://hadoop3:50070/explorer.html#/
Yarn - http://hadoop4:8088/cluster
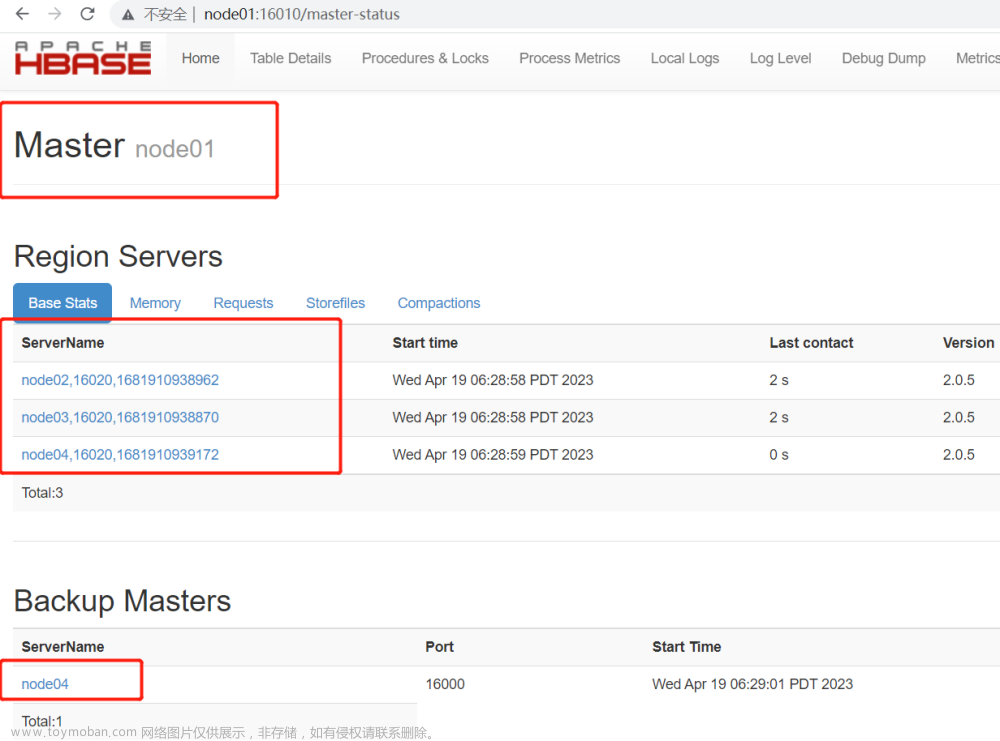
HBase - http://hadoop3:16010/master-status文章来源:https://www.toymoban.com/news/detail-721077.html
文章来源地址https://www.toymoban.com/news/detail-721077.html
到了这里,关于搭建HBase分布式集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!